






总览
研究背景
领域:半监督目标检测(SSOD)(半监督目标检测通过利用大量无标注数据和少量有标注数据来提高模型的性能和泛化能力。其基本思路是使用有标注数据进行初步训练,然后使用无标注数据进行进一步的优化)
问题:现有的SSOD方法主要集中于水平目标检测,对多方向目标(如航空图像中的目标)的研究较少。
挑战:多方向对象的标注成本高于水平对象,且其具有任意方向、小尺度和聚集的特点。
研究目的
提出一种新的半监督多方向目标检测方法(SOOD++),利用未标记数据来提升多方向目标检测的性能。
方法概述
1.简单实例感知密集采样(SIDS)策略:
- 生成全面的密集伪标签。
2.几何感知自适应加权(GAW)损失:
- 动态调整每对伪标签与对应预测之间的重要性,利用对象的复杂几何信息。
3.噪声驱动的全局一致性(NGC)方法:
- 构建伪标签与预测集之间的多对多关系,将航空图像视为全局布局。
原文研读
相关工作
半监督目标检测
近年来,半监督学习(SSL)在图像分类领域表现出显著的性能。这些方法通过伪标签、保持一致性正则化、数据增强和对抗训练等技术来利用未标记的数据。与半监督图像分类不同,半监督目标检测(SSOD)需要实例级的预测以及额外的边界框回归任务,从而增加了其复杂性。在一些研究中,通过结合各种增强技术生成伪标签。随后的一些研究将EMA从Mean Teacher方法中引入,每次训练迭代后更新教师模型。ISMT方法将当前伪标签与历史伪标签相结合。Unbiased Teacher方法通过用焦点损失替代交叉熵损失来解决类别不平衡问题。Humble Teacher方法利用软伪标签作为学生的训练目标,使学生能从教师中提取更丰富的信息。Soft Teacher方法基于分类分数自适应地加权每个伪框的损失,并引入框抖动以选择可靠的伪标签。Unbiased Teacher v2采用无锚检测器,并使用不确定性预测来选择回归分支的伪标签。Dense Teacher方法用密集像素级伪标签替代后处理的实例级伪标签,有效消除了后处理超参数的影响。PseCo方法提出了多视图尺度不变学习,以确保标签级和特征级的一致性,校准两幅具有相同内容但不同尺度图像之间的位移特征金字塔。Consistent Teacher结合自适应锚分配、3D特征对齐模块和高斯混合模型,以减少训练中的匹配和特征不一致性。MixTeacher明确提高伪标签的质量,以处理对象的尺度变化。Semi-DETR方法专为DETR检测器设计,缓解了因双向匹配与噪声伪标签带来的训练低效问题。为了解决分配模糊问题,ARSL方法提出结合联合置信度估计和任务分离分配策略。
然而,上述所有方法都是为一般场景设计的。如何在航拍场景中释放半监督框架的潜力尚未得到充分探索。本文旨在填补这一空白,并为未来的研究提供一个坚实的基线。
多方向目标检测
与使用水平边界框(HBBs)表示对象的一般目标检测器不同,多方向目标检测器使用定向边界框(OBBs)来捕捉对象的方向,这在检测航拍对象时很实用。近年来,许多方法被开发出来以提高多方向目标检测的性能。例如,CSL通过将角度回归问题转化为分类任务来解决越界问题。R3Det在第一阶段预测HBBs,然后在第二阶段对齐特征以检测定向对象,从而提高了检测速度。Oriented R-CNN引入了一个简化的多定向区域建议网络,并使用中点偏移来表示任意定向对象。ReDet将旋转等变网络引入检测器,以提取旋转等变特征。Oriented RepPoints结合了质量评估模块和自适应点学习的样本分配方案,有助于从邻近对象中获取非轴特征,同时忽略背景噪声。LSKNet扩展了大选择性核机制以提高性能。最新的方法COBB采用从外部HBB和OBB区域派生的九个参数。
上述方法通常专注于完全监督的范式,需耗费大量标注成本。因此,最近提出了一些弱监督目标检测器,例如基于点的方法或基于HBB的方法。然而,它们要么不如完全监督的对应方法,要么未能利用未标记数据提高性能。本文探索了半监督多方向目标检测,通过利用额外的未标记数据,降低标注成本并提升检测器性能,即使是那些在大规模标记数据上训练良好的检测器。
预备知识
本节回顾了SSOD中的主流伪标签范式,并介绍了Monge-Kantorovich最优传输理论的概念。
伪标签范式
伪标签框架继承了Mean Teacher的设计,包括教师模型和学生模型。教师是学生的指数移动平均(EMA)。它们通过以下步骤迭代学习:1) 为批次中的未标记数据生成伪标签。这些伪标签是从教师的预测中筛选出来的,例如框坐标和分类分数。同时,学生对批次中的标记和未标记数据进行预测。2) 计算学生预测的损失。它由无监督损失Lu和有监督损失Ls两部分组成,分别针对未标记数据与伪标签和标记数据与真实标签(GT)计算。总体损失L是它们的总和。3) 根据总体损失更新学生的参数。教师则以EMA的方式同时更新。
基于伪标签的稀疏性,伪标签框架可以进一步分类为稀疏伪标签和密集伪标签,分别称为SPL和DPL。SPL在后处理操作后选择教师的预测(例如NMS和分数筛选),获得稀疏标签,如边界框和类别,以监督学生。DPL则直接采样教师预测的后sigmoid像素级logits,这些logits是密集且信息丰富的。
在本文中,我们考虑到稀疏和密集伪标签采样策略在处理小尺度、密集分布的遥感对象时的局限性。具体来说,SPL可能无法检测到小对象,导致监督信息不足。而DPL尽管丰富,但由于密集小对象与背景之间的不清晰性,可能引入大量噪声。因此,我们提出了一种简单的实例感知密集采样(SIDS)策略,在前景和背景的预测框中采样密集伪标签,生成更全面的密集伪标签。
最优传输
Monge-Kantorovich最优传输(OT)旨在解决以最小成本同时将物品从一个集合移动到另一个集合的问题。OT的具体数学原理在本文暂时略过,详见论文原文。
在本文中,我们扩展了最优传输理论来构建教师-学生对的全局一致性,这不仅增强了检测过程对伪标签不准确性的鲁棒性,还鼓励了一种整体学习方法,在这种方法中同时考虑空间信息和关系上下文。
方法
下图展示了我们提出的SOOD++流程。具体来说,SOOD++是一个密集伪标签框架,由三个关键组件组成:一个简单实例感知密集采样(SIDS)策略用于构建高质量的密集伪标签,几何感知自适应加权(GAW)损失和噪声驱动的全局一致性(NGC)分别用于从一对一和集合到集合(全局)角度测量教师和学生之间的差异。
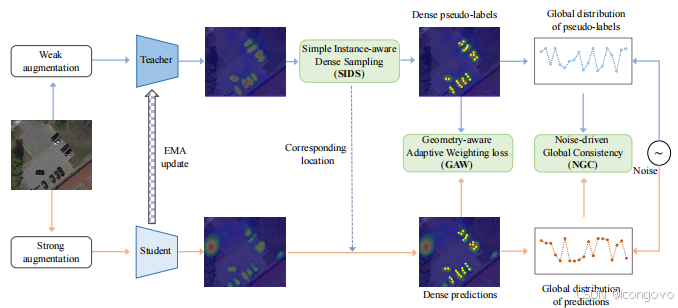
整体框架
由于航拍对象通常密集且小,稀疏伪标签范式可能会遗漏大量潜在对象。因此,我们选择了密集伪标签(DPL)范式。训练过程包括监督部分和无监督部分。对于监督部分,学生使用标记数据进行常规训练。对于无监督部分,我们采用以下步骤:
首先,给定教师的输出,我们利用简单实例感知密集采样(SIDS)策略生成全面的密集伪标签P_t。我们还在学生相同位置选择预测P_s。因此,我们获得了教师-学生对(即P_t和P_s)。
接下来,我们使用提出的几何感知自适应加权(GAW)损失,通过利用内在几何信息(包括方向差距和纵横比)动态加权每个教师-学生对的无监督损失。
然后,我们提出的噪声驱动的全局一致性(NGC)通过将P_t和P_s视为两个全局分布构建了一个放松的约束。随机噪声用于扰动教师和学生的全局分布。随后,我们实现了多角度的全局对齐,包括原始教师和学生之间的对齐、扰动教师和扰动学生之间的对齐,以及从前者对齐生成的传输计划。
我们采用广泛使用的旋转版本的FCOS作为教师和学生。注意,在每个像素级点上,旋转-FCOS将预测置信度分数、中心度和边界框。基本的无监督损失包含分类损失、回归损失和中心度损失,分别对应FCOS的输出。我们采用平滑L1损失用于回归损失,二元交叉熵(BCE)损失用于分类和中心度损失。在此基础上,我们的GAW和NGC将用于从不同角度测量教师和学生的一致性。
关于FCOS,是一个在2019年提出的一阶段检测器,具体原理可以参考下面的博客,讲得很好。
https://blog.csdn.net/qq_37541097/article/details/124844726
后续部分将于未来一周内更新。
简单的实例感知密集采样策略(SIDS)
构建伪标签是半监督框架中至关重要的预处理步骤。正如之前讨论的,由于航空场景中的物体通常较小且密集,使用密集伪标签范式比稀疏伪框范式能更好地识别未标记数据中的潜在物体。
以前的密集伪标签方法通常从预测得分图中提取固定数量(即Top-K)的密集伪标签(如下图(c))。相比之下,我们动态地从预测的实例(框)区域和背景中采样可变数量的密集伪标签(如下图(d))。具体来说,我们将未标记数据中的伪标签分为两类:从预测结果中获得的简单案例和通常无缝融合到背景中的难案例。根据教师模型经过后处理(如NMS)后的预测结果,认为是前景(简单案例),我们在这些预测框所指示的区域内按比例R随机采样像素级预测结果,得到 Pe。注意,由于实例数量的动态变化,我们的采样数量在不同场景中会有所不同,更好地匹配物体的分布。
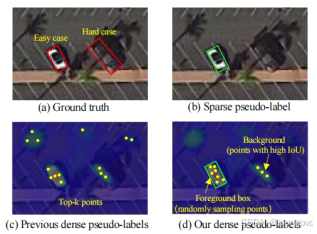
然而,单纯采用上述策略从前景中采样密集伪标签往往会忽略那些无缝融合到背景中的密集、小物体。为了解决这个问题,我们提出了一种直观的方法,从背景中提取潜在的密集伪标签。具体来说,我们通过经验发现那些尽管置信度较低但高质量的潜在正样本与目标位置对齐得很好。因此,我们可以使用预测框和真实框之间的交并比(IoU)作为在背景噪声中辨别伪标签的标准。然而,鉴于未标记数据集中缺乏真实值,无法获得明确的IoU分数。因此,我们引入了一个IoU估计分支,该分支通过有标记数据进行训练,预测未标记数据中每个像素的IoU分数。然后,我们应用阈值Th选择背景中具有高IoU分数的像素级点,得到密集的难伪标签 Ph。我们将 Ph和 Pe合并,建立最终的密集伪标签 Pt,这将作为无监督训练过程的监督信号。
基于Pt,我们在相同坐标处采样学生模型的预测,定义为 Ps。在获得Pt和Ps后,半监督框架旨在使Ps接近Pt,我们将在后续部分描述如何构建一对一和多对多的约束。
不可否认,IoU估计确实是一种广泛使用的技术。然而,我们的方法的目标与以前的方法根本不同,以前的方法主要集中在框的精细化上。相比之下,我们的方法旨在在半监督框架中从背景中挖掘潜在的密集伪标签。需要注意的是,本文并不声称所提出的SIDS的创新性,而是提出了一种简单有效的采样策略,能够生成高质量的密集伪标签。
几何感知自适应加权损失(GAW)
方向是定向物体的一个重要属性。即使物体密集且小,它们的方向仍然清晰。一些定向物体检测方法已经在损失计算中使用了这种属性。这些工作是在假设标签角度是可靠的情况下进行的,严格地让预测结果接近真实值是自然的。然而,在半监督环境下,这种假设并不成立,因为伪标签可能是不准确的。简单地强制学生模型对齐教师模型可能导致噪声积累,对模型的训练产生不利影响。此外,对于具有不同长宽比的定向物体,方向的影响也显著不同。例如,具有大长宽比的定向物体对旋转变化非常敏感,即使轻微的错位也会导致显著的IoU变化。
基于上述观察,我们提出了软性利用方向信息和长宽比的方法,使半监督框架能够更好地理解定向物体的几何先验。具体来说,预测与伪标签之间的方向差异在某种程度上可以指示实例的难度,并可以用于动态调整无监督损失。此外,由于具有不同长宽比的定向物体对旋转变化表现出不同的敏感性,这可以用来调节方向差异在指示实例难度中的重要性。因此,我们提出了一种基于这两个关键几何先验的几何感知调制因子。类似于焦点损失,这个因子通过考虑每对伪标签和预测的内在几何信息(例如方向差异和长宽比)动态加权每对伪标签-预测对的损失。具体来说,第i对的几何感知调制因子ωi_geo定义为:
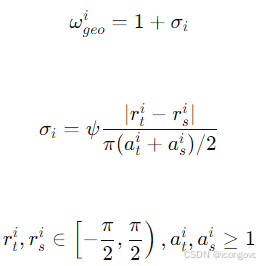
其中,r it 和 r is分别表示第i个伪标签和预测的旋转角度(以弧度为单位)。a it和 a is表示它们的长宽比。给σi加一个常数确保当伪标签和预测的方向一致时,原始的无监督损失得以保留。调制因子σi考虑了方向差异和平均长宽比。当方向差异很小但物体的长宽比很大时,所提出的因子仍然可以有效地将这种情况突出为可能的困难例子,从而帮助改进学习过程,反之亦然。
利用几何感知调节因子,整体几何感知自适应加权(GAW)损失的公式为:
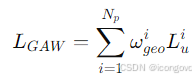
其中,Np是伪标签的数量,L_u^i 是第i个伪标签-预测对的基本无监督损失。使用几何感知调节因子,GAW损失为优化提供了明确的方向,促进了半监督学习过程。
总体而言,GAW损失通过结合方向差异和长宽比信息,动态调整损失的计算方式,从而在半监督学习中更好地利用伪标签,提高模型的训练效果和检测性能。
噪声驱动的全局一致性(Noise-driven Global Consistency, NGC)
该部分原文较长,在此处展示个人的总结。
背景与动机:
- 航拍图像中的目标通常是密集且规则分布的,这类似于文档中的结构化布局。目标集合的空间配置被称为布局,传递了对象间的关系和图像的整体模式。
- 理论上,如果每对伪标签和预测对齐,学生模型和教师模型的布局一致性将被保留。然而,由于伪标签可能包含噪声,严格要求这种对齐可能会影响性能。因此,增加布局一致性作为一个额外的优化目标是合理的,以鼓励学生模型从教师模型中学习全局信息。
NGC方法的详细步骤:
1.添加噪声:
将教师和学生模型的输出视为全局分布,并添加不同的随机噪声来干扰这些分布。
2.多视角对齐:
从三个方面进行多视角对齐:
- 对齐原始教师和原始学生的分布。
- 对齐受干扰的教师和受干扰的学生的分布。
- 对齐从上述两个步骤生成的传输计划(transport plans)。
3.全局相似性测量:
利用最优传输理论(Optimal Transport Theory)来测量教师和学生预测之间布局的全局相似性。具体方法是:
定义教师和学生模型预测的分类分数全局分布。
为了确保数值稳定性和非负性,采用指数函数。
将噪声添加到分布中,以反映多对多关系。
4.传输成本计算:
传输成本由空间距离和分数差异构成。
使用Sinkhorn距离算法解决最优传输问题,获得近似解。
5.全局一致性损失的定义:
定义原始和噪声扰动情况下的全局一致性损失。
计算传输计划(OT plans)之间的均方误差(MSE),以评估噪声的影响并为模型提供辅助指导。
综合以上损失,得到NGC的训练目标:
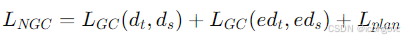
NGC损失促进学习过程的机制:
增强模型的鲁棒性:
通过引入噪声和多视角对齐,NGC方法增强了模型对输入微小变化的容忍度,使模型更有效地捕捉未标记数据的本质特征。
减少伪标签不准确的负面影响:
NGC方法通过全局一致性约束,减轻了伪标签不准确对检测过程的负面影响。
促进整体学习:
鼓励模型考虑对象的空间和关系动态,采用整体学习方法,而不仅仅依赖于单个实例。
与GAW损失的互补性:
NGC损失与几何感知自适应加权(GAW)损失互补,通过提供全局一致性约束,进一步提升半监督学习的效果。
总的来说,NGC损失通过引入全局一致性约束和噪声干扰,增强了模型对未标记数据的学习能力,促进了模型从全局视角理解和利用数据的本质特征。
训练目标
SOOD++利用几何感知自适应加权(GAW)损失和噪声驱动的全局一致性(NGC)损失来处理未标记数据,同时对于标记数据则使用监督损失。总体损失函数 L 定义如下:
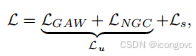
其中,Lu和Ls分别表示半监督损失和监督损失。请注意,监督损失Ls与监督基线(旋转fcos)中定义的相同,我们的设计只修改了无监督部分。
以上就是论文中的主要方法部分,实验部分暂时跳过,接下来阅读的相关论文为:Learning to Holistically Detect Bridges from Large-Size VHR Remote Sensing Imagery
正在对该领域进行研究的同学可以交流一下0.0


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









