









目录
在许多的媒体平台上我们能够看到许多事物发展的历程。比方说各大手游从2000到2020年的收入排名之类的。其视屏的排名会动态变化,在本篇博文中,我们就将介绍如何用我们的python生成事物发展历程的视屏
本篇博文先介绍每个小功能如何实现,最后会给出全部的代码,就是如何将每个功能组装起来。
development
以下是我们本次用到的数据
链接: https://pan.baidu.com/s/1OJp6bTIaLu-GaaZNooiTIQ 提取码: k7oc
一、导入我们的Python数据包
import cv2
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#由于博主所使用的是Mac电脑,所以测试的是Mac的环境
#mac版本的使用下面两行代码
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
#windows版本的使用下面两行代码
plt.rcParams["font.family"] = ["sans-serif"]
plt.rcParams["font.sans-serif"] = ['SimHei']1.读取我们的数据
如果使用下面的代码的话,我们需要将我们的数据表放在我们与Python文件的同级目录下
从我们Python读取到的原始数据中,我们发现我们的原始数据如下
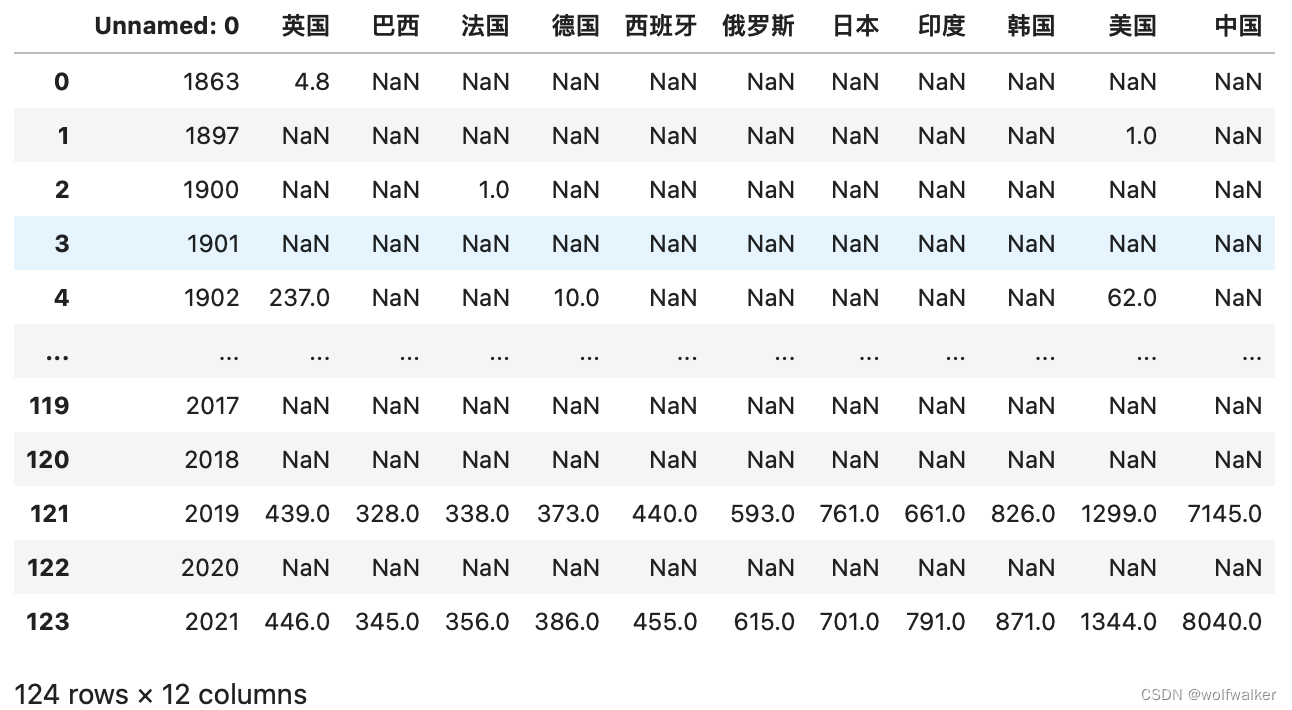
我们需要将我们原始数据的每一列空格部分都使用前后两个值进行“线性插值”填空,这里我们就用到了我们下面代码中的interpolate()方法
data=pd.read_excel('国家地铁里程历程.xlsx')
data=data.interpolate()
#将我们的空值置为0
data=data.fillna(0)
print(data)
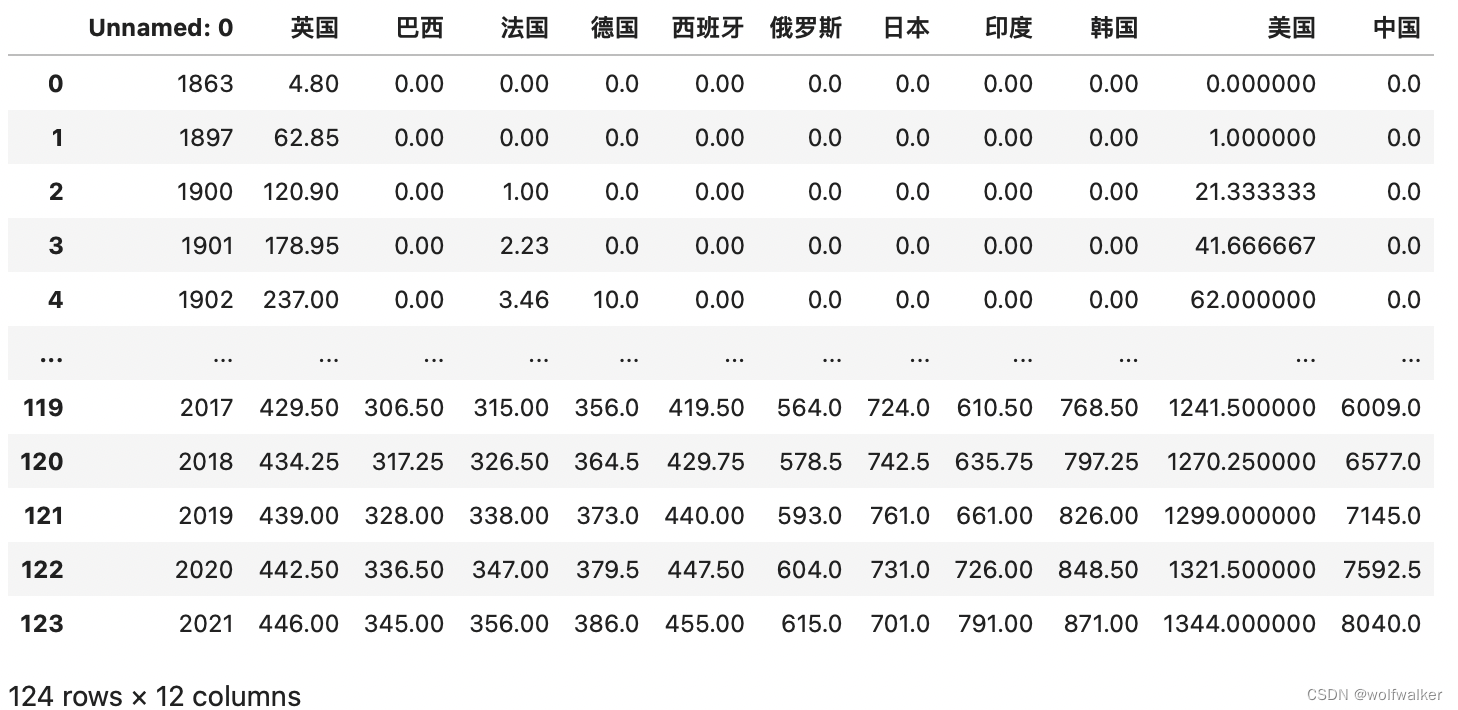
2.观察数据
由于我们需要实现的是1900-2021年的数据,并且每一年需要分成12个月,所以我们在此随机抽取我们的的100和101条数据来观察一下,
data1=data.loc[100][1:12]
data2=data.loc[101][1:12]
#算出我们扥第一个月的数据
data3=data1+(data2-data1)*1/12
#对我们的数据进行排序,这里我们按照升序排序
data3=data3.sort_values(ascending=True)
print(data3)以下就是我们查看到的数据

3.对我们的列表填充不同的颜色
由于我们每次读取到的数据在排序后,我们的对应的排序索引都会发生变化,所以我们在此用一个字典类型存储我们的每个国家对应的颜色(中国一定为红色!!!)然后将我们的column,也就是我们每次排序后的新索引传入,然后利用我们的字典,排序出我们对应的颜色列表。
dict={'中国':'r','巴西':'g', '法国':'b', '德国':'#8736FA', '西班牙':'#87C4FA', '俄罗斯':'k', '日本':'y',
'印度':'#87CEFA', '韩国':'#87C12A', '美国':'#2312FA', '英国':'#2712FA'}
color=[]
for i in column:
color.append(dict[i])
print(color)
4.设计我们所要绘制的图表的样式
#绘制条形统计图,并且依次传入我们的索引,数据,并且我们的颜色指定我们之前排序过后的颜色
plt.barh(column,data1,color=color)
#给我们的表格打上标题
plt.title("1863国家地铁里程")
#给我们的表格打上横坐标的名字
plt.xlabel('km')
#打上纵坐标的名字
plt.ylabel('国家')
#给我们的每条柱子都打上具体的数值
for index, y_value in enumerate(data1):
plt.text(y_value+10, index-0.2, "%.2f" %y_value)
#存储我们的表格在我们的subway目录下,这里我们需要先手动在我们的Python同级目录下创建一个subway文件
plt.savefig(fname="subway/2000国家地铁里程.jpg")
plt.show()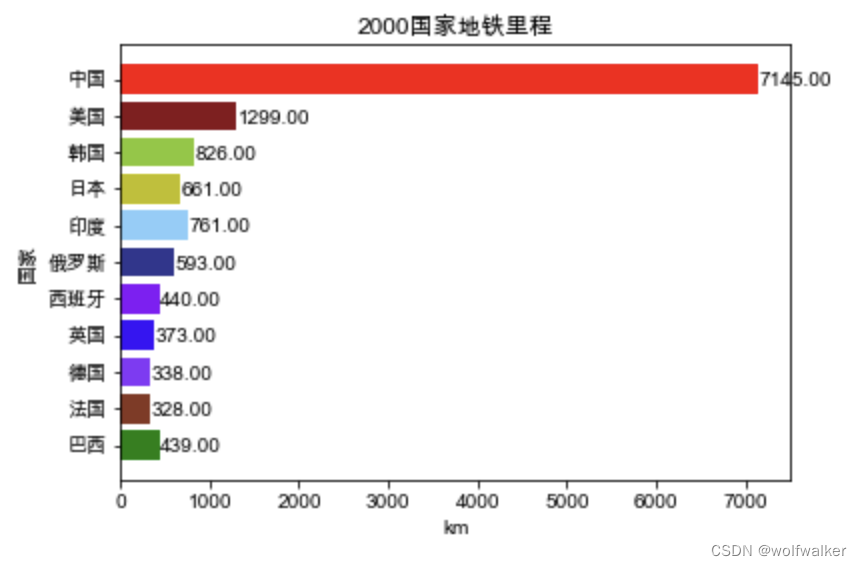
5.创建我们的年份索引列表
这里我们需要的是1900年到2021年的数据,应为在1900年之前的数据存在大量缺失
year1=data['Unnamed: 0']
year1=list(year1)[2:]
print(year1)
二、功能的拼接
这里我们就将我们的上述代码全部都拼接起来,实现我们的最终功能
1.表格的导出生成
#生成我们的年份索引
year1=data['Unnamed: 0']
year1=list(year1)[2:]
#初始化我们的月份
month1=1;
#用一个空列表来存储我们的每一张图片的名称
img_array = []
for i in range(0,123):
#仿照我们上述的步骤,读取具体的前后两年的数据(我们需要通过前后两年的数据再推算出每个月的数据)
year=str(year1[i])
data1=data.loc[i][1:12]
data2=data.loc[i+1][1:12]
#遍历我们的1~13月
for month1 in range(1,13):
#清空我们的图表,如果不清除的话,我们的图标会叠加绘制
plt.clf()
#将我们的月份转化为字符串类型
month=str(month1)
#定义我们的表格的标题,并且传入我们具体的年份和月份
plt.title("{}年{}月国家地铁里程".format(year,month))
#往我们的列表中将我们表格的名字追加
img_array.append("subway/{}年{}月国家地铁里程.jpg".format(year,month))
plt.xlabel('km')
plt.ylabel('国家')
#生成我们具体每一个月的数据
data3=data1+(data2-data1)*month1/12
data3=data3.sort_values(ascending=True)
column=list(data3.index)
dict={'中国':'r','巴西':'g', '法国':'#873620', '德国':'#8736FA', '西班牙':'#8714FA', '俄罗斯':'#303690', '日本':'y',
'印度':'#87CEFA', '韩国':'#87C82A', '美国':'#89121A','英国':'#3A13FA'}
color=[]
for i in column:
color.append(dict[i])
plt.barh(column,data3,color=color)
for index, y_value in enumerate(data3):
plt.text(y_value+10, index-0.2, "%.2f" %y_value)
#将我们的图片存储到我们的subway文件夹下(我们一共有1452张图片,为了方便,最好存储到一个文件夹下)
plt.savefig(fname="subway/{}年{}月国家地铁里程.jpg".format(year,month))
然后我们就获得了大量的表格

三、视屏的制作
#导入我们的cv2库
#须先执行安装pip install opencv-python
import cv2
#按照图像的实际大小配置
size = (432,288)
#定义我们的解码器为H264
fourcc = int(cv2.VideoWriter_fourcc(*'H264'))
#定义我们的图标的具体参数,第一个是我们视屏保存的路径,第二个是编码,第三个是帧率,第四个是我们的图片大小(必须与我们的表格大小对应)
videowrite = cv2.VideoWriter('subway.mp4',fourcc,12, size,True)
#新生成一个列表用于存储我们读取之后的数据
img_array1 = []
#将我们之前保存的列表中的每一个图表文件使用imread读入,然后将我们读取之后的数据存储到我们新的列表中
for filename in img_array:
img = cv2.imread(filename)
#如果没有读取到我们的图表,我们就将声明not found
if img is None:
print(filename + "is not found.")
continue
img_array1.append(img)
#写入我们的数据
for i in range(0,1452):
videowrite.write(img_array1[i])
#释放我们的资源
videowrite.release()
print('over')然后我们就可以在我们的Python主文件的同级目录下发现我们生成的视屏了
development
















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











