







(ps一些算法可能在前面的博客写完了,请移步)
(1)关于图的基础知识详见书本
(2)关于图的几种储存模式
1.接邻矩阵,这是最简单的一种,原理其实就是二维矩阵
2.接邻表,类似二叉树中的孩子表示法,链表+数组的结合模式
3.十字链表,接邻表的拓展,不常用
4.边际数组,用数组来储存边的信息,贝尔曼福特算法就是用这个实现的
(3)图的创建,这里举例使用无向图接邻表(十字链表就是在每个结点新增一个储存前驱的链表)
//这里几个注意事项,node中的a,代表的是"终点的序号",链表只是为了储存数据,而不是由数据拼成链表.
//尝试实现接邻表
class Node {
public:
//数据区域,用来存放目标的本体
int a;//储存下一个结点的所在位置
int weight;//权重
Node* next;//指针域
Node(int a) {
this->a = a;
}
};
class headNode {
public:
Node* point;//指针区域,指向链表头部的指针
int out;//出度
int in;//入度
int num;//关系数目
};
class List {
public:
headNode arr[20];
int pointNum, edgeNum;//记录节点数目和边数
};
void createGraphList(List & list) {//创建接邻表
int point, edge;
int x, y,num;//起点,终点
cout << "请输入点,边数和" << endl;
cin >> point >> edge;
list.edgeNum = edge; list.pointNum = point;
//先把数组的结点创建完毕
for (int i = 0; i < point; i++) {
list.arr[i] = headNode();
}
//在按照边的起点和终点设置好数据,再使用头插法双向插入
//链表中每个结点的数值代表与之关联的结点,总数用num进行统计
for (int i = 0; i < edge; i++) {
cin >> x >> y;//起点终点
Node* temp = new Node(y);//创建结点
temp->next = list.arr[x].point;//头插法插入
list.arr[x].point = temp;
Node* temp2 = new Node(x);//另一个方向
temp2->next = list.arr[y].point;
list.arr[y].point = temp2;
//关系数目加一
list.arr[x].num++;
list.arr[y].num++;
}
}(4)图的遍历
图的遍历由几种方式
1,深度优先遍历DFS:
原理类似前序遍历
//深度优先算法DFS
//原理其实是前序遍历的变形
//每个点都进行遍历,如果没有被访问就对下面的链表进行遍历,同时使用递归操作
bool visited[20];
void DFS(List& list,int i) {
if (visited[i] == 0) {//如果这个点尚且没有被访问过
visited[i] = 1;//先行确认这个点已经访问过了
cout << "已经走过" << i << endl;
Node* point = list.arr[i].point;
while (point) {
DFS(list, point->a);
point = point->next;
}
}
}
void DFSserver(List & list) {
for (int i = 0; i < list.pointNum; i++) {
visited[i] == 0;
}
for (int i = 0; i < list.pointNum; i++) {
DFS(list, i);
}
}2.广度优先遍历BFS;
bool visiting[20];
void BFS(List& list) {
queue<int> Queue;
Node* point;
for (int i = 0; i < list.pointNum; i++) {
visiting[i] = 0;
}
for (int i = 0; i < list.pointNum; i++) {
if (visiting[i] == 0) {
Queue.push(i);
visiting[i] = 1;
cout << "访问到了" << i << endl; //打印结点
while (!Queue.empty()) { //类似拓扑排序的操作
int temp = Queue.front();
Queue.pop();
visiting[temp] = 1;
point = list.arr[temp].point;
while (point) {
if (visiting[point->a] == 0) {
Queue.push(point->a);
visiting[point->a] = 1;
cout << "访问到了" << point->a << endl; //打印结点
}
point = point->next;
}
}
}
}
}
(5)关于最小生成树
最小生成树其实就是寻找一个最短的路径联通所有点,其中路径数目为n-1个
最小生成树的prim算法实现(利用接邻矩阵实现的),其算法原理是"集团化"
lowcost数组代表的是,整个集团到达其余点的最短路径分别是什么(数值为0时,代表已经存在)
adjvex数组仅仅代表"这个点的上一个点是啥",用于输出而已
因为一开始默认v0结点在生成树内,所以下面的遍历都是n-1次
(1)第一部分,初始化
因为此时结点集团只有0一个,所以到达每个点的基本路径就是初始点到各个点的举例
adjvex也全是0;
(2)第二部分,大循环(n-1次)
找到最短的路
标记这个距离最近的点(lowcost变成0)
扩张集团结点,修改结点集团到其他点的距离(如果集团目前到a点的距离,大于新加入的k点到a点的距离,那就修改lowcost数组)
具体代码如下
void prim(int arr[10][10]) {
int lowcost[10];
int adjvex[10];
for (int i = 0; i < 10; i++) {
lowcost[i] = arr[0][i];
adjvex[i] = 0;
}
for (int j= 1; j < 9; j++) {//因为最小生成树有九个结点,这里循环八次就够了
int min = 100;
int k = 0;
int n = 1;//单纯的计数器罢了
while (n < 10) {
if (lowcost[n] != 0 && lowcost[n] < min) {
min = lowcost[n];
k = n;
}
n++;
}
//此刻k就是最小的那一个点
lowcost[k]=0;
cout << "(" << adjvex[k] << "," << k << ")" << endl;
for (int i = 1; i < 10; i++) {
if (lowcost[i] != 0 && lowcost[i] > arr[k][i]) {
lowcost[i] = arr[k][i];
adjvex[i] = k;
}
}
}
}图的数据如下
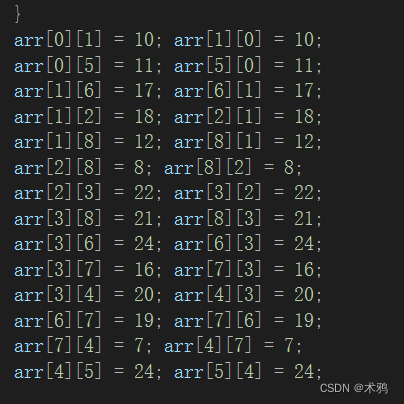
运行结果如下

最小生成树的第二种,克鲁斯卡尔算法,利用边集数组实现的
(边集数组和贝尔曼福特算法的一样,但是这里用空间换时间,已经把边集数组按权重从小到大排列了)
int Find(int parent[], int a) {//寻找最尾端结点的操作.
while (parent[a] > 0) {
a = parent[a];
}
return a;
}
void kruskal(edge arr[]) {
int parent[9] = { 0,0,0,0,0,0,0,0,0 };
for (int i = 0; i < 15; i++) {
int n = Find(parent, arr[i].start);
int m = Find(parent, arr[i].end);
if (m != n) {
parent[n] = m;
cout << arr[i].start << "-->" << arr[i].end << endl;
}
}
}
//这里补充一下parent的用途:储存集合
//而且关于为什么是parent[n]=m;
//判断start所在集合的最尾端,和end所在集合的最尾段是不是一样,如果一样代表这俩已经联通
//这个类似静态链表的东西,是按照输入的一定顺序,储存的集合
//具体的储存方式,见拍照的信息
//而find方法,就是寻找一个点所在集合中的根节点
//还有一件事,只能是[n]=m,而不能是[m]=n;
//因为那样的话会产生储存集合乱套的事情,会让一个点在find方法下同时有多个根节点
//总之,克鲁斯卡尔的原理应该是:选择权值最小的一个边,同时判断边上的两个点是不是属于同一个集合内部
//如果不在同一个集合(根节点不同),那么就整合两个点所在的集合

///临时保存一下
关于关键路径算法
//尝试实现接邻表
class Node {
public:
int a;//储存结点的所在位置
int weight;//权重
Node* next;//指针域
Node(int a) {
this->a = a;
}
};
class headNode {
public:
Node* point;//指针区域,指向链表头部的指针
int out=0;//出度
int in=0;//入度
};
class List {
public:
headNode arr[20];
int pointNum, edgeNum;//记录节点数目和边数
};
void createGraphList(List & list) {//创建接邻表(单向的)
int point, edge;
int x, y,weight;//起点,终点
cout << "请输入点,边数和" << endl;
cin >> point >> edge;
list.edgeNum = edge; list.pointNum = point;
//先把数组的结点创建完毕
for (int i = 0; i < point; i++) {
list.arr[i] = headNode();
}
cout << "请输入起点,终点,权重" << endl;
for (int i = 0; i < edge; i++) {
cin >> x >> y>>weight;//起点终点
Node* temp = new Node(y);//创建结点
temp->weight = weight;
temp->next = list.arr[x].point;//头插法插入
list.arr[x].point = temp;
list.arr[x].out++;
list.arr[y].in++;
}
}
//先对图进行拓扑排序
//要求获取stack数组和etv数组
int stack2[20];
int etv[20];
int ltv[20];
int top=0;
void tuopu(List &list) {
//已经获取图了
stack<int> Stack;
for (int i = 0; i < list.pointNum; i++) {
if (list.arr[i].in == 0) {
Stack.push(i);
}
}
//注意事项1;
//etc:指的是这个点能保证自己所有的前驱都完成开工,并且走完这个路径,
//也就是保证自己的前驱全部结束
//ltv:指的是给自己的后面预留足够的空间,所以是从反方向开始的
//注意事项2;
//关于图的遍历,这里用的是暴力遍历
//一个for来应付数组,while用来应付链表
while (!Stack.empty()) {
int temp = Stack.top();
Stack.pop();
stack2[top++] = temp;//stack2(拓扑顺序),可以在弹出栈的时候得到
Node* point = list.arr[temp].point;
while (point) {
if (--list.arr[point->a].in == 0) {
Stack.push(point->a);
}
//etc的原则是:在保证安全的情况下,最早的开工时间
//按照拓扑的正顺序,如果前一个点的开工时间+路途的时间 晚于 这个点的开工时间
//那么这个点的开工时间就延后放大到,能让上一个点开工并且走完路程
if (etv[temp] + point->weight > etv[point->a]) {
etv[point->a] = etv[temp] + point->weight;
}
point = point->next;
}
}
}
void guanjian(List& list) {
//先进行初始化
for (int i = 0; i < list.pointNum; i++) {
ltv[i] = etv[list.pointNum - 1];
}
int top2 = list.pointNum - 1;
int temp = 0;
//ltc数组的原则是:在保证安全的情况下,最晚的开工时间(给后面留足够的时间)
//按照拓扑的反顺序遍历每一个路径,若一个点的最晚时间 晚于(大于) 子点需要的时间+这段路途的时间
//就把这个点的最晚时间,提前到能让下一个点的开工和中间路径有充足的时间
while (top2 >= 0) {
temp = stack2[top2--];
Node* point = list.arr[temp].point;
while (point) {
if (ltv[point->a] - point->weight < ltv[temp]) {
ltv[temp] = ltv[point->a] - point->weight;
}
point = point->next;
}
}
//最后的比较仍然是遍历每个路径,如果起点的开工时间加上下一段路程刚好是子点的开工时间
//就不能再拖延了,需要直接输出
for (int i = 0; i < list.pointNum; i++) {
Node* point = list.arr[i].point;
while (point) {
int ete = etv[i];
int lte = ltv[point->a] - point->weight;
if (ete == lte) {
cout << i << "----" << point->a << endl;
}
point=point->next;
}
}
}














 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









