






在计算机科学中,哈夫曼树(Huffman Tree)是一种经典的数据结构,常用于数据压缩和编码算法中。它是一种特殊的二叉树,具有最优的前缀编码性质,即权值较大的字符拥有较短的编码,从而实现高效的数据压缩。
1. 哈夫曼树的原理
哈夫曼树的构建过程基于哈夫曼算法,主要包括以下步骤:
- 初始化:创建一个大小为2n-1的huffmanTree结构数组,其中n为叶子节点的个数。初始化所有节点的权值、父节点、左右子节点为0。
- 选择最小权值节点:从叶子节点中选择两个权值最小且无父节点的节点作为合并节点,更新其权值为两者之和,并设置合并节点的左右子节点和父节点。
- 重复合并:重复上述步骤,直到所有节点合并为一个根节点。
- 构建完成后,根节点即为哈夫曼树的根。
2. 示例与分析
我们以10个权值为1, 2, 3, 4, 5, 6, 7, 8, 9, 10的叶子结点为例进行演示。以下是构建过程中每个节点的信息:
输入的10个权值分别为1 2 3 4 5 6 7 8 9 10的叶子结点的哈夫曼树为:
权值为20无父结点 权值为20左子树结点权值为:10 右子树结点权值为:10
权值为10的父结点权值为:20 权值为10左子树结点权值为:5 右子树结点权值为:5
权值为10的父结点权值为:20 权值为5左子树结点权值为:2 右子树结点权值为:3
权值为5的父结点权值为:10 权值为2无子结点
权值为5的父结点权值为:10 权值为3无子结点
权值为10的父结点权值为:20 权值为6左子树结点权值为:3 右子树结点权值为:3
权值为6的父结点权值为:10 权值为3无子结点
权值为6的父结点权值为:10 权值为3无子结点
权值为20的父结点权值为: 权值为10左子树结点权值为:5 右子树结点权值为:5
3. 应用场景
哈夫曼树在数据压缩和编码中有着广泛的应用。通过采用不等长编码方式,将出现频率高的字符用较短的二进制编码表示,而出现频率低的字符用较长的编码表示,从而实现数据的高效压缩。
在实际应用中,哈夫曼编码常被用于文件压缩、图像压缩、音频压缩等领域。它不仅可以减小数据的存储空间,还可以提高数据传输速度。
4.完整代码
#include <iostream>
#include <cfloat>
using namespace std;
const int n = 10;
const int N = 2 * n - 1;
struct huffmanTree {
double weight; // 权值
int parent, liftchild, rightchild; // 左右子树和父树
};
//初始化huffmanTree树
void initHuffman(huffmanTree (&ht)[N]) {
for (int i = 1; i <= N; i++) {
ht[i].weight = 0;
ht[i].liftchild = 0;
ht[i].rightchild = 0;
ht[i].parent = 0;
}
}
//寻找权值最小且无父节点的两个节点
void selectTree(huffmanTree (&ht)[N], int n, int *m1, int *m2) {
double min1 = DBL_MAX;
double min2 = DBL_MAX;
for (int i = 1; i <= n; i++) {
if (ht[i].weight <= min1 && ht[i].parent == 0) { // 寻找权值最小且无父节点的节点
min1 = ht[i].weight;
*m1 = i; // 记录权值最小的节点索引
}
}
for (int i = 1; i <= n; i++) {
if (ht[i].weight <= min2 && ht[i].parent == 0 && i != *m1) { // 寻找次小权值且无父节点的节点
min2 = ht[i].weight;
*m2 = i; // 记录次小权值的节点索引
}
}
}
//构建Huffman树
void creatHuffman(huffmanTree (&ht)[N], int n) {
int i;
for (i = n + 1; i <= N; i++) {
int m1, m2;
selectTree(ht, i - 1, &m1, &m2); // 选择权值最小和次小的节点
ht[i].weight = ht[m1].weight + ht[m2].weight; // 合并节点的权值为两者之和
ht[i].liftchild = m1; // 设置合并节点的左子树
ht[i].rightchild = m2; // 设置合并节点的右子树
ht[i].parent = 0; // 设置合并节点的父节点
ht[m1].parent = i; // 更新左子树的父节点为合并节点
ht[m2].parent = i; // 更新右子树的父节点为合并节点
}
}
//主程序
int main() {
cout << "输入的10个权值分别为1 2 3 4 5 6 7 8 9 10的叶子结点的哈夫曼树为" << endl;
huffmanTree huffmantree[N];
initHuffman(huffmantree);
for (int i = 1; i <= n; i++) {
huffmantree[i].weight = i; // 初始化叶子节点的权值
}
creatHuffman(huffmantree, n); // 构建哈夫曼树
for (int i = 1; i <= N; i++) {
if (huffmantree[i].parent == 0) {
cout << "权值为" << huffmantree[i].weight << "无父结点";
} else {
cout << "权值为" << huffmantree[i].weight << "的父结点权值为:";
cout << huffmantree[huffmantree[i].parent].weight;
}
if(huffmantree[i].liftchild == 0 && huffmantree[i].rightchild == 0)
{
cout << " "<<"权值为" << huffmantree[i].weight << "无子结点";
}
else
{
cout << " "<< "权值为" << huffmantree[i].weight <<"左子树结点权值为:";
cout << huffmantree[huffmantree[i].liftchild].weight << " 右子树结点权值为:";
cout << huffmantree[huffmantree[i].rightchild].weight ;
}
cout << endl;
}
return 0;
}
4.运行结果:
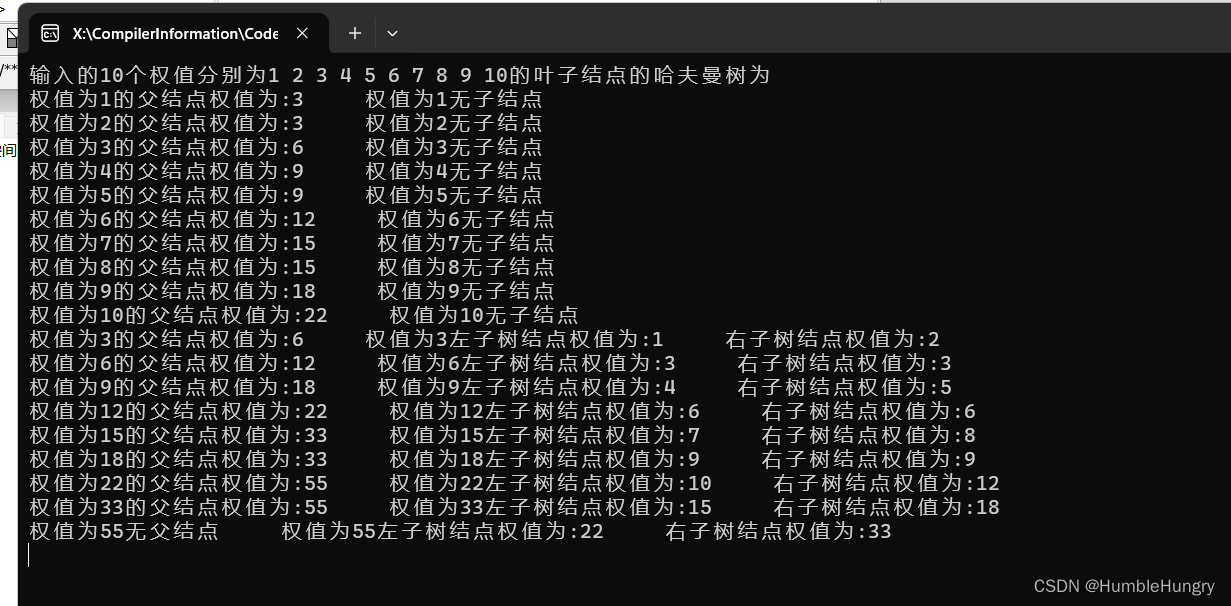
5. 总结
本文介绍了哈夫曼树的原理、构建过程以及在数据压缩中的应用。哈夫曼树通过构建最优的前缀编码方式,实现了数据的高效压缩和解压缩。在实际应用中,我们可以利用哈夫曼编码算法对数据进行压缩,从而达到节省存储空间和提高传输效率的目的。


















 1845
1845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











