







目录
单链表(不带头)
一、概念
每个结点保存了自身结点值、下一个结点的地址,只能从头开始遍历。
单向链表属于线性表,逻辑连续,有索引
二、要点总结
-
单链表中的最后一个结点中,指向下一个结点的地址为null
-
Node结点对象本身可视为此结点的地址
如:
node为结点自身的地址,node.next为下一结点的地址 -
仅头结点没有前驱结点,其他结点(中间结点、尾结点)都有前驱结点
-
由于头结点没有前驱结点,故头结点的插入、删除方式与其他结点不同
插入、删除操作中需注意将头结点单独进行处理
-
-
单链表的核心:寻找前驱结点(除头结点无前驱)
- 根据指定索引index找前驱结点时,分离出头结点的分支
if(index==0) {插入、删除头结点} - 根据指定值val找前驱结点时,分离出头结点的分支
if(head.val==val) {删除头结点}
- 根据指定索引index找前驱结点时,分离出头结点的分支
-
在单链表中根据index寻找结点
-
寻找index的前驱结点:从头结点 index=0 处开始向后走 (index-1) 步即到达index的前驱结点
for(int i = 0; i < index-1; i++)—— 循环执行index-1次 -
寻找index结点:从头结点 index=0 开始向后走 index 步即到达index结点
for(int i = 0; i < index; i++)—— 循环执行index次
-
-
当涉及要x掉链表中的某个指针时,检查是否已对其作出了处理:
要么修改其指向,要么置空null -
注意避免对head头结点的直接操作,防止影响整个链表
如:遍历时使用临时引用
Node x = head; x = x.next;来取代head = head.next; 删除头结点时使用临时引用
Node x = head.next; x = null;来取代head.next = null; -
node = null;和node.next = null;的区别:前者只是将指向结点node的引用置空,即找不到存放该结点的堆区地址,但其对象本身仍然在堆中实际存在,且其成员变量
node.next也仍然在堆中存在;后者是将结点node的成员变量next指针(引用)置空,不再指向确定的堆区内存,即结点node后方的链条都断了
-
涉及传参index时需先对index进行合法性判断
-
对于带索引的查询、删除、修改操作,索引的合法性要求为:在有效元素的范围内进行操作 index[0,size-1]
if(index < 0 || index >= size) {索引越界处理}—— 不允许 index=size -
对于带索引的插入操作,索引的合法性要求为:包括头插index=0、尾插index=size index[0,size]
if(index < 0 || index > size) {索引越界处理}—— 允许index=size
-
-
涉及传参val时需先对链表进行判空
- 对于根据val值查询、删除等操作,注意先对链表判空
if(head==null) {return终止当前操作}
- 对于根据val值查询、删除等操作,注意先对链表判空
三、代码实现
1. 类结构
//结点类
class Node {
int val; //当前结点保存的值
Node next; //下一个结点的地址
}
//单链表
public class SingleLinkedList {
private Node head; //头结点的地址
private int size; //链表的长度(结点个数)
...(增删改查方法)
}
2. 单链表的遍历
/**(单链表的遍历)从头结点开始,循环将下一个结点的地址值赋给当前结点的地址 */
public String toString() {
String ret = "";
//使用一个临时变量存放链表的头结点,不直接使用头结点以免改变链表本身
Node x = head; //用于遍历的临时变量总是位于链表的头结点位置
while (x != null) { //当前链表不为空
ret += x.val; //读取当前结点的值
ret += "->";
//让下一个结点成为新的临时头结点
x = x.next; //将下一个结点的地址赋给当前结点的地址
}
ret += "NULL"; //链表结尾标记
return ret;
}
3. 插入结点
3.1 头插法
/** (头插法)往链表中添加一个结点,默认在头部添加 */
public void add(int val) {
//新建一个结点
Node newNode = new Node();
newNode.val = val;
//若链表为空(头结点为空)
if(head == null) {
head = newNode;
}else { //若链表不为空
newNode.next = head; //新结点指向原头结点的地址
head = newNode; //新结点成为新的头结点
}
size++; //总结点个数增1
}
代码简化:头插结点一定会成为新的头结点,而只有当链表不为空时才要将当前新结点先指向原来的头结点
/** (头插法)往链表中添加一个结点,默认在头部添加 */
public void add(int val) {
//新建一个结点
Node newNode = new Node();
newNode.val = val;
//若链表不为空(头结点不为空)
if (head != null) {
newNode.next = head; //新结点指向原头结点的地址
}
//新结点成为新的头结点
head = newNode; //【无论链表是否为空都要执行】
size++; //总结点个数增1
}
3.2. 指定索引处插入结点
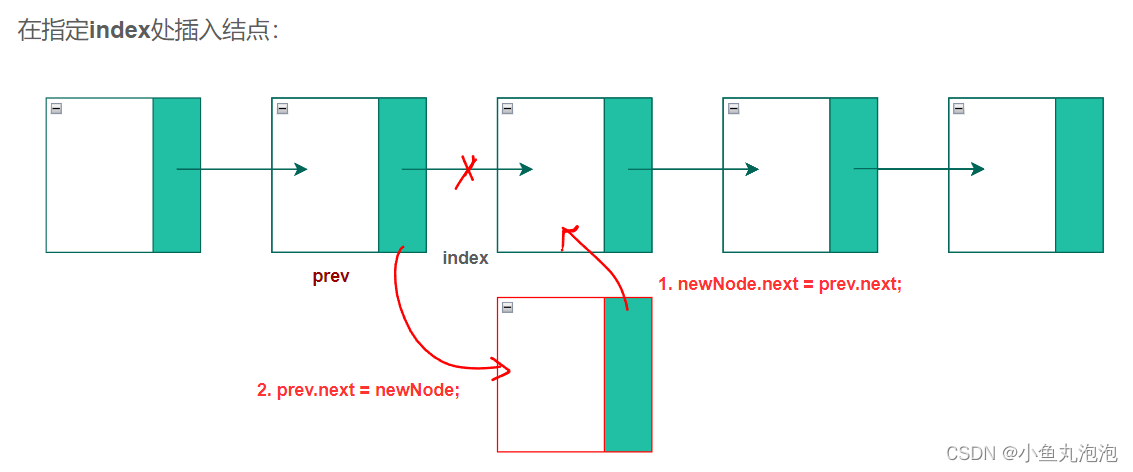
【前驱结点】:仅头结点没有前驱结点,其他结点(中间结点、尾结点)都有前驱结点
由于头结点没有前驱结点,故头结点的插入、删除方式与其他结点不同
插入、删除操作中需注意将头结点单独进行处理
【单链表的核心】:寻找前驱结点(除头结点无前驱)
- 根据指定索引index找前驱结点时,分离出头结点的分支
if(index==0) {插入、删除头结点}√- 根据指定值val找前驱结点时,分离出头结点的分支
if(head.val==val) {删除头结点}
/**(指定索引处插入元素)前驱引用prev从头结点开始向后走,需要走index-1步即找到插入位置的前驱结点 ==> 循环(index-1)次 */
public void add(int index, int val) {
//【传参涉及index就要判断其合法性】允许(index=0)头插、(index=size)尾插
if(index < 0 || index > size) {
System.out.println("add index illegal!");
return;
}
/**【单链表的核心】寻找前驱结点 */
if(index == 0) { //头结点没有前驱,单独处理
add(index); //头插
}else {
//插入位置有前驱结点,寻找前驱结点
Node prev = head;
//从头结点0处开始,prev向后走(index-1)步即找到index位置的前驱结点
for(int i = 0; i < index-1; i++) {
prev = prev.next; //prev循环向后走,把下一个结点的地址赋给自己
}
//新建一个结点
Node newNode = new Node();
newNode.val = val;
//插入新结点
newNode.next = prev.next; //新结点指向前驱结点的下一个结点
prev.next = newNode; //前驱结点指向新结点
//总结点个数增1
size++;
}
}
3.3. 尾插法
可直接复用指定索引插入结点的方法add(int index, int val)。尾结点和所有中间结点一样,都有前驱结点。只有头结点没有前驱结点。
/**(尾插法)尾结点同所有中间结点一样都有前驱结点 ==> 可直接复用add(int index, int val)方法 */
public void addLast(int val) {
add(size, val); //插入位置index表示的是新结点插入后的索引
}
头插 index=0 尾插 index=size
4. 查找结点
4.1. 查询包含指定值的结点
【链表判空】
对于根据val值查询、删除等操作,注意先对链表判空
if(head==null) {return终止当前操作}
/** 查询包含指定值的结点,存在则返回其索引,不存在返回-1 */
public int getByValue(int val) {
/** 涉及传参val的查询、删除操作需先对链表进行判空 */
if(head == null) {
System.err.println("链表为空,找不到!");
return -1;
}else { //链表不为空
//从头结点开始遍历所有结点
Node x = head;
//头结点index=0,每遍历一个结点则index++
int index = 0;
while(x != null) { //当前链表不为空,至少还有一个头结点
if(x.val == val) {
return index;
}
x = x.next; //让当前结点成为新的头结点,继续循环向后遍历
index++; //索引增1
}
}
return -1; //未找到(链表不为空也没找到)
}
4.2. 查询是否存在包含指定值的结点
/** 查询是否包含指定值的结点,存在返回true,不存在返回false */
public boolean contains(int val) {
return getByValue(val) != -1; //返回值不等于-1则为true
}
4.3. 查询指定索引处的结点值
【判断索引的合法性】
对于带索引的查询、删除、修改操作,索引的合法性要求为:在有效元素的范围内进行操作 index[0,size-1]
if(index < 0 || index >= size) {索引越界处理}—— 不允许 index=size对于带索引的插入操作,索引的合法性要求为:包括头插index=0、尾插index=size index[0,size]
if(index < 0 || index > size) {索引越界处理}—— 允许index=size
- 为增强代码复用性,提取判断索引合法性的方法,设定为private权限(用户不关心)
/** 判断index索引的合法性 —— 查询、删除、修改,设定为private私有(用户不关心)*/
private boolean rangeCheck(int index) {
//(带索引查询、删除、修改的操作)对索引合法性要求都是在有效范围内进行操作 index[0,size-1]
if(index < 0 || index >= size) { //不允许(index=size)
System.out.println("index illegal!");
return false;
}
return true;
}
1)未改进版:边查边判断索引是否匹配,对每个索引都进行判断
/** 查询索引为index的结点值,返回此值,若索引越界返回-1 */
public int get(int index) {
//【传参涉及index就要判断其合法性】
if(!rangeCheck(index)) {
return -1; //索引越界
}
//从头结点index=0开始遍历,每遍历一个结点则index++
int tempIndex = 0;
Node x = head;
while(x != null) {
//检查当前index是否为指定索引
if(tempIndex++ == index) {
return x.val;
}
x = x.next;
}
return 0;
}
2)改进版:一次走到指定索引处,再对该索引进行判断
/** 查询索引为index的结点值,返回此值,若索引越界返回-1 */
public int get(int index) {
//【传参涉及index就要判断其合法性】
if(!rangeCheck(index)) {
return -1; //索引越界
}
//从头结点index=0开始走index步即走到index索引处
Node x = head;
for(int i = 0; i < index; i++) {
x = x.next;
}
return x.val;
}
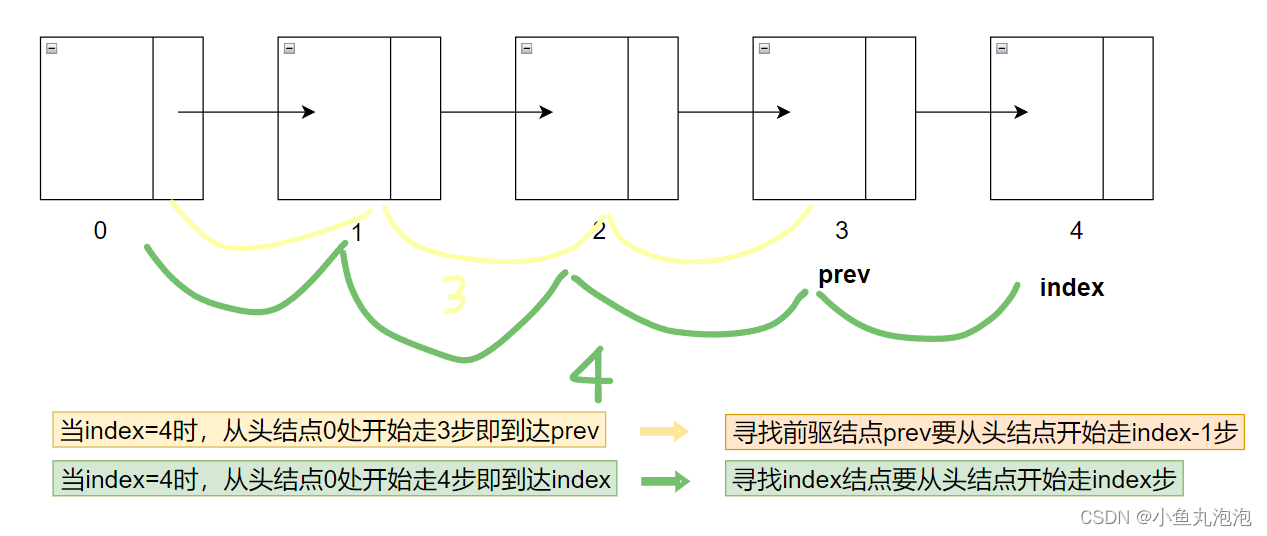
【在单链表中根据index遍历查找某个结点】
寻找index的前驱结点:从头结点 index=0 处开始向后走 (index-1) 步即到达index的前驱结点
for(int i = 0; i < index-1; i++)—— 循环执行index-1次寻找index结点:从头结点 index=0 开始向后走 index 步即到达index结点
for(int i = 0; i < index; i++)—— 循环执行index次
5. 修改结点值
5.1. 修改指定索引处的结点值
/** 修改索引为index的结点值为newVal,返回修改前的结点值,若索引越界返回-1 */
public int set(int index, int newVal) {
//【传参涉及index就要判断其合法性】
if(!rangeCheck(index)) {
return -1;
}
//从头结点index=0开始走index步即走到index索引处
Node x = head;
for(int i = 0; i < index; i++) {
x = x.next;
}
int oldVal = x.val;
x.val = newVal;
return oldVal;
}
6. 删除结点
6.1. 删除指定索引处的结点
【前驱结点】:仅头结点没有前驱结点,其他结点(中间结点、尾结点)都有前驱结点
由于头结点没有前驱结点,故头结点的插入、删除方式与其他结点不同
插入、删除操作中需注意将头结点单独进行处理
【单链表的核心】:寻找前驱结点(除头结点无前驱)
- 根据指定索引index找前驱结点时,分离出头结点的分支
if(index==0) {插入、删除头结点}√- 根据指定值val找前驱结点时,分离出头结点的分支
if(head.val==val) {删除头结点}
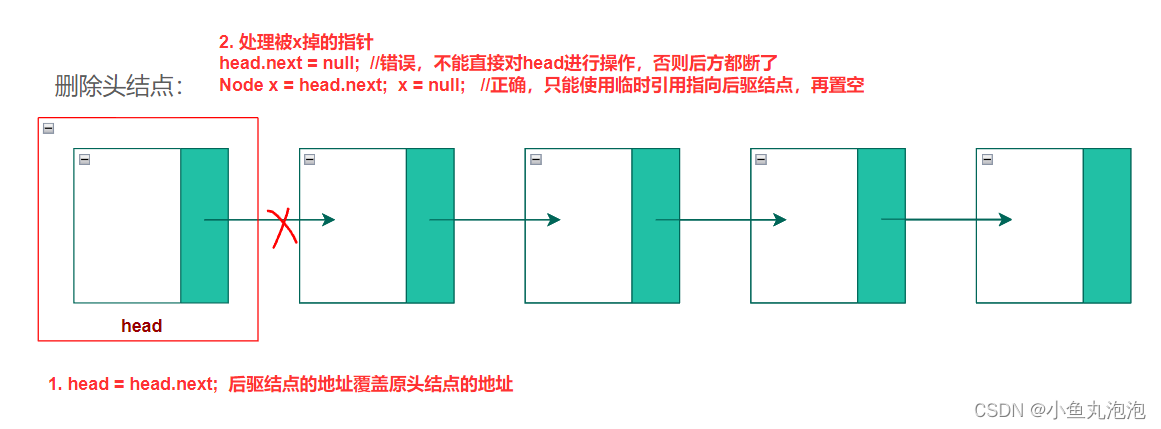
【注意】 必须对所有被x掉的指针作处理,要么改变其指向,要么置空null
Node x = head.next; x = null; //使用临时引用x将head.next置空【注意】 不能直接对head进行操作,否则一旦
head.next = null;则链表后方都断了
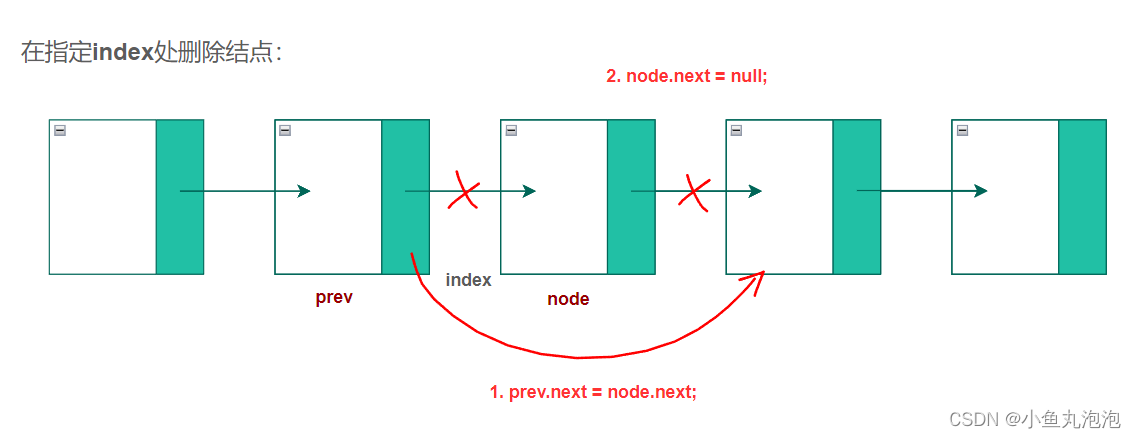
【注意】 必须对所有被x掉的指针作处理,要么改变其指向,要么置空null
prev.next = node.next; //改变指向
node.next = null; //置空
/** 删除索引为index的结点,返回删除前的结点值,若索引越界返回-1 */
public int remove(int index) {
//【传参涉及index就要判断其合法性】
if(!rangeCheck(index)) {
return -1;
}
int temp = 0; //暂存被删除的结点值
/**【单链表的核心】寻找前驱结点 */
if(index == 0) { //头结点没有前驱,单独处理
//记录被删除的头结点值
temp = head.val;
/**【注意!】要对所有被x掉的指针作处理,要么改变其指向,要么置空null */
Node x = head; //【在head被修改前暂存】
head = head.next; //将后驱结点的地址覆盖原头结点的地址,使其成为新的头结点
x = null; //将被x掉的指针置空
}else {
//删除的结点有前驱结点,寻找前驱结点
Node prev = head;
//从头结点开始向后走(index-1)步即找到前驱结点
for(int i = 0; i < index-1; i++) {
prev = prev.next;
}
//记录被删除的结点值
temp = prev.next.val;
//删除结点
/**【注意!】要对所有被x掉的指针作处理,要么改变其指向,要么置空null */
Node node = prev.next; //获取被删除的结点
prev.next = node.next; //将前驱结点的next指针指向后驱结点
node.next = null; //将被删除结点指向后驱结点的指针置空
}
size--;
return temp;
}
错误代码:
prev.next = prev.next.next; //将前驱结点指向index后驱结点的地址 prev.next.next = null; //将被删除结点指向其后驱结点的指针置空测试结果:
System.out.println(singleLinkedList); //输出30->20->100->10->40->50->60->NULL System.out.println(singleLinkedList.remove(2)); //输出被删除的结点值100 System.out.println(singleLinkedList); //输出30->20->10->NULL分析原因:
第1行中原来指向被删除结点的指针
prev.next已被修改为指向其后驱结点的地址,即prev.next转为代表后驱结点,故第2行的prev.next.next代表的是后驱结点的next指针,一旦置空,则链表后方所有都断了。
正确代码: 先获取被删除结点,分步操作Node node = prev.next; //获取被删除的结点 prev.next = node.next; //将前驱结点的next指针指向后驱结点 node.next = null; //将被删除结点指向后驱结点的next指针置空测试结果:
System.out.println(singleLinkedList); //输出30->20->100->10->40->50->60->NULL System.out.println(singleLinkedList.remove(2)); //输出被删除的结点值100 System.out.println(singleLinkedList); //输出30->20->10->40->50->60->NULL
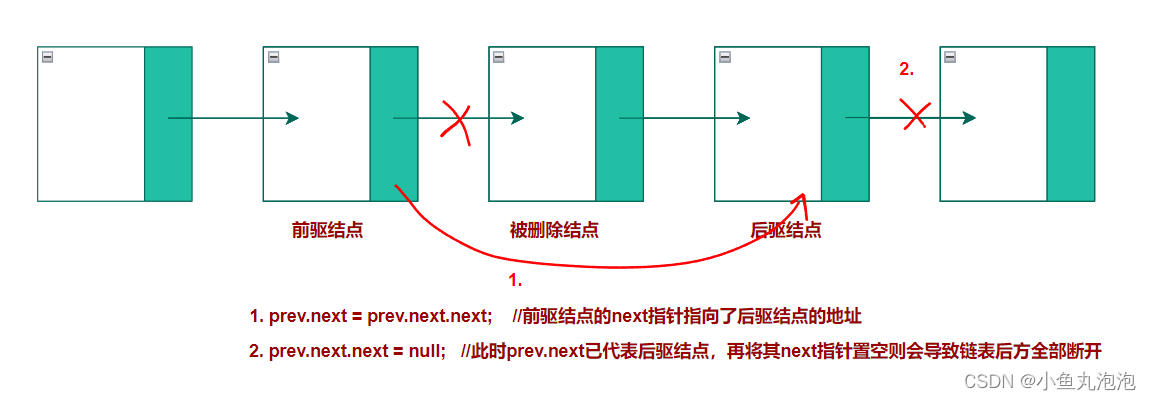
复用 remove(int index) 方法:
头结点的删除方式已在 remove(int index) 方法中考虑到,满足 if(index == 0) 分支即会删除头结点,可直接复用
/** 删除头结点,返回被删除的结点值 */
public int removeFirst(int index) {
return remove(0); //(index=0)一定不会发生越界问题,故返回值不可能为-1
}
尾结点和其他中间任意结点一样都有前驱结点,其删除方式已在 remove(int index) 方法中实现,可直接复用
/** 删除尾结点,返回被删除的结点值 */
public int removeLast(int index) {
return remove(size-1); //(index=size-1)一定不会发生越界问题,故返回值不可能为-1
}
6.2. 删除第一个值为val的元素
【前驱结点】:仅头结点没有前驱结点,其他结点(中间结点、尾结点)都有前驱结点
由于头结点没有前驱结点,故头结点的插入、删除方式与其他结点不同
插入、删除操作中需注意将头结点单独进行处理
【单链表的核心】:寻找前驱结点(除头结点无前驱)
- 根据指定索引index找前驱结点时,分离出头结点的分支
if(index==0) {插入、删除头结点}- 根据指定值val找前驱结点时,分离出头结点的分支
if(head.val==val) {删除头结点}√
【链表判空】
对于根据val值查询、删除等操作,注意先对链表判空
if(head==null) {return终止当前操作}
/** 删除链表中第一个值为val的结点,返回此结点值,删除失败返回-1 */
public int removeByValueOnce(int val) {
/** 涉及传参val的查询、删除操作需先对链表进行判空 */
if(head == null) {
System.err.println("链表为空,无法删除!");
return -1;
}
int temp = -1; //记录要返回的结点值,默认-1表示未找到
/**【单链表的核心】寻找前驱结点 */
//未知val所在索引,只能从头开始遍历,找符合要求的前驱结点(prev.next.val==val)
if(head.val == val) { //头结点没有前驱,单独处理
temp = head.val;
//删除头结点
Node x = head; //在被修改前保存head
head = head.next;
x.next = null;
size--;
}else { //要删除的不是头结点
Node prev = head;
Node node = prev.next;
while(prev != null) { //边遍历边比较
if(node.val == val) {
temp = node.val;
//删除结点
prev.next = node.next; //前驱结点的next指针指向后驱结点
node.next = null; //将被删除结点原先指向后驱结点的next指针置空
size--;
break; //删除第一个val即退出
}
prev = prev.next;
}
}
return temp;
}
6.3. 删除链表中所有值为val的元素
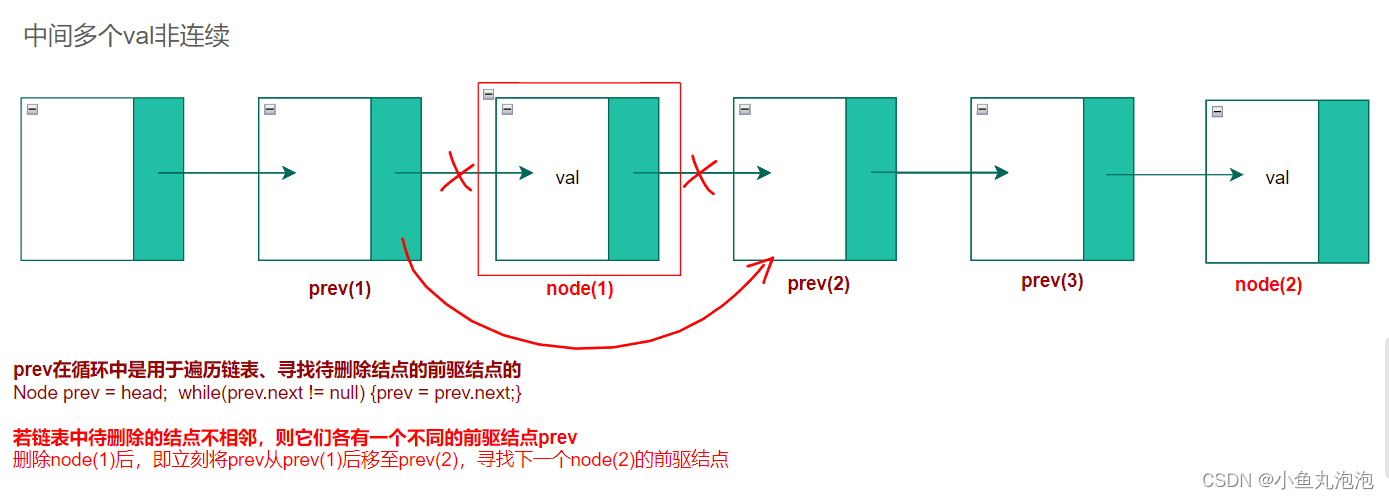
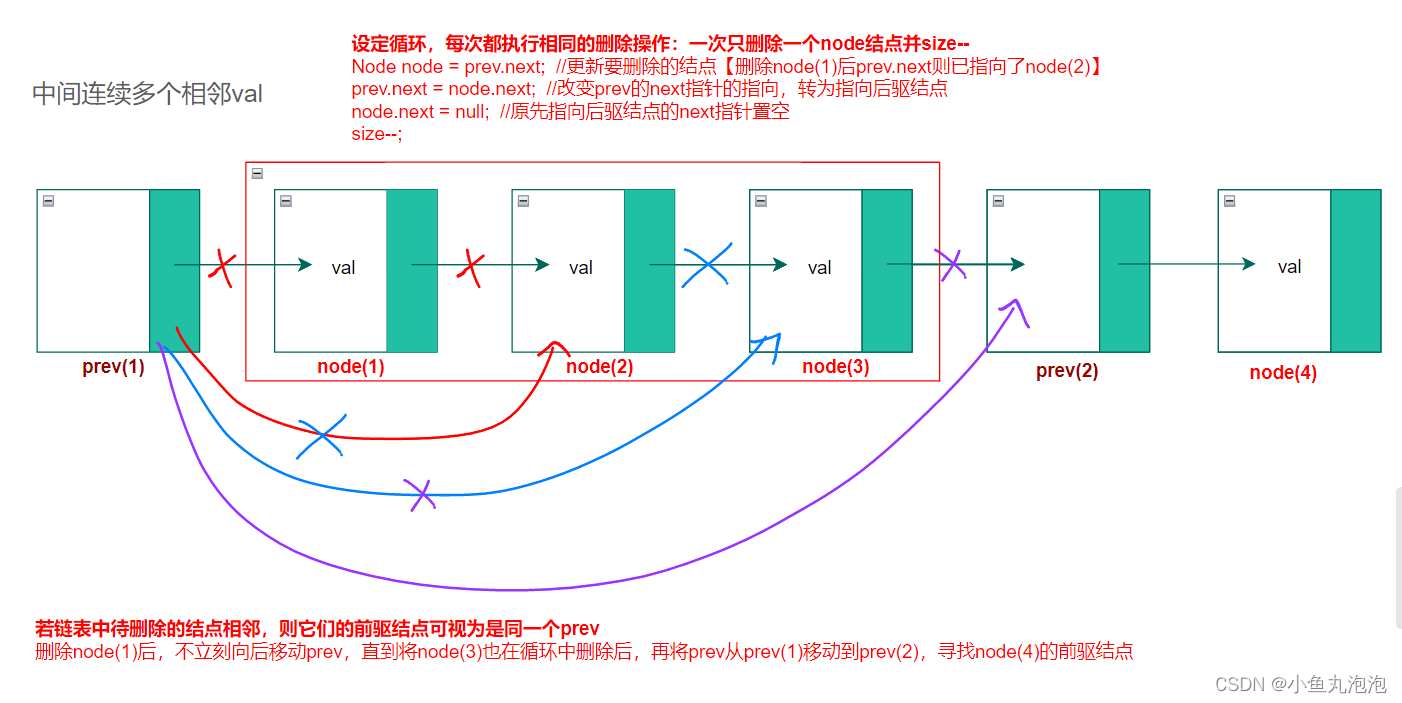
头结点没有前驱,需单独处理
/** 删除链表中所有值为val的结点 */
public void removeByValueAll(int val) {
/** 涉及传参val的查询、删除操作需先对链表进行判空 */
if(head == null) {
System.err.println("链表为空,无法删除!");
return;
}
//若头结点就是要删除的结点,且后方可能有连续多个val ==> 循环删除头结点
while(head != null && head.val == val) {
Node x = head;
head = head.next;
x.next = null;
size--;
}
//【执行完上方删除操作后,链表可能已经变空,head存在空指针隐患】
if(head != null) {
//遍历寻找待删除结点的前驱结点
Node prev = head;
while(prev.next != null ) { //循环后移prev
//仅当prev.next不再是待删除的结点时才移动prev
if(prev.next.val != val) {
prev = prev.next;
}
else { //prev.next是待删除的结点
//不移动prev,只删除结点
Node node = prev.next;
prev.next = node.next;
node.next = null;
size--;
}
}
}
}














 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









