







1.sd1.5/sdxl的推理
主要讲述一下unet的降噪,以及采样器的作用,已sd1.5为例,sdxl类似
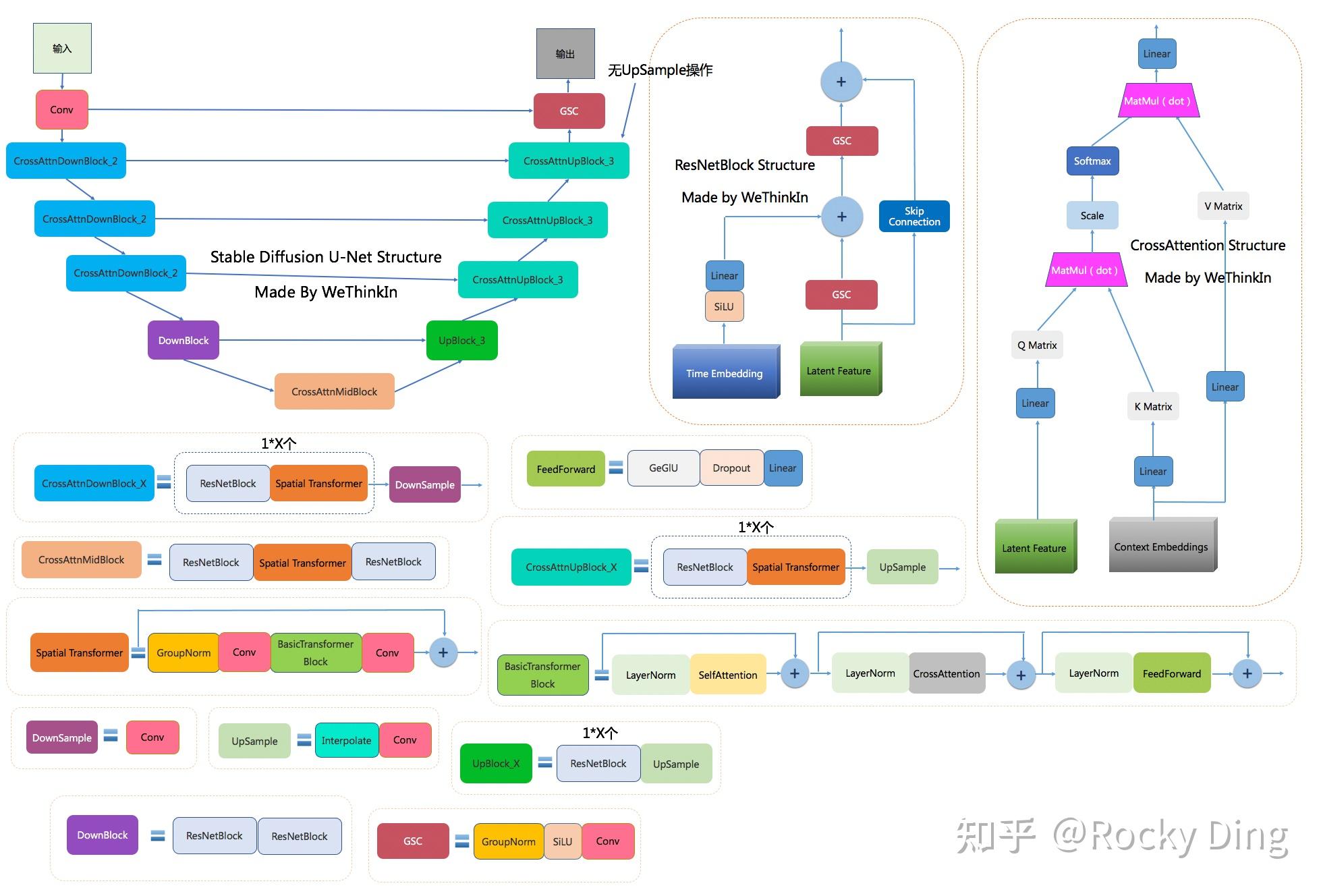
unet的降噪过程中,如20步降噪,这20个unet共用的一个权重

1.1 timesteps
根据unet的降噪步数,即num_inference_steps生成一系列timesteps,每一个降噪步数,对应一个timestep。
num_inference_steps = 20 时
timesteps = tensor([951, 901, 901, 851, 801, 751, 701, 651, 601, 551, 501, 451, 401, 351,
301, 251, 201, 151, 101, 51, 1], device='npu:0')
num_inference_steps = 50 时
timesteps = tensor([981, 961, 961, 941, 921, 901, 881, 861, 841, 821, 801, 781, 761, 741,
721, 701, 681, 661, 641, 621, 601, 581, 561, 541, 521, 501, 481, 461,
441, 421, 401, 381, 361, 341, 321, 301, 281, 261, 241, 221, 201, 181,
161, 141, 121, 101, 81, 61, 41, 21, 1], device='npu:0')1.2 latent的降噪过程
1.2.1首先使用unet预测出噪声noise_pred
如下图第二步所示,左边为unet中输入lantent,prompt,t,输出为当前时刻的预测噪声noise
1.2.2使用scheduler(调度器),计算出前一时刻的latents
如下图第二步所示,右边为schedule(调度器),调度器根据unet的预测噪声noise,当前时刻t,latent,计算出前一时刻的latent
1.2.3如此循环直到计算出t0时刻的latent,即降噪完成

# pipeline_stable_diffusion.py 文件
for i, t in enumerate(timesteps):
# noise_pred为unet预测的噪声
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
timestep_cond=timestep_cond, # None
cross_attention_kwargs=self.cross_attention_kwargs, # None
added_cond_kwargs=added_cond_kwargs, # None
return_dict=False,
)[0]
# noise_pred_uncond:无条件的噪声预测,通常是在没有任何文本或条件输入时生成的噪声预测。
# noise_pred_text:有条件的噪声预测,通常是在给定文本描述或其他条件时生成的噪声预测。
# 通过 self.guidance_scale * (noise_pred_text - noise_pred_uncond),模型试图将噪声的有条件部分(noise_pred_text)与无条件部分(noise_pred_uncond)之间的差异放大。
# 通过调整无条件噪声和有条件噪声之间的差异来放大条件对结果的影响,从而使生成的图像更符合指定的条件。
if self.do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
# 此时为调度器的计算过程,将unet预测的噪声noise_pred,当前步数time_step,以及需要降噪的latens输入调度器中,计算上一个时间节点的latens
# self.scheduler.step方法的实现,如调度器为ddim,则该方法在scheduling_ddim.py文件中
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0] 1.3 unet的预测噪声详解
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
timestep_cond=timestep_cond, # None
cross_attention_kwargs=self.cross_attention_kwargs, # None
added_cond_kwargs=added_cond_kwargs, # None
return_dict=False,
)[0]
#unet_2d_condition.py文件中self.unet的forward方法
# 将离散的时间步(例如,0 到 T 的整数)映射到一个连续的、高维的嵌入向量,是固定的,没有权重
# 它将时间步数映射到一个高维的嵌入空间,利用正弦和余弦函数的周期性特征帮助模型捕捉时间步的顺序关系。这种方法类似于 Transformer 中的位置编码,可以为时间步提供平滑的编码表示。
# timestep就是t,单个数值,类型为tensor,如:tensor(51, device='npu:0')
t_emb = self.get_time_embed(sample=sample, timestep=timestep) # torch.Size([2, 320])
# 将时间的高维特征,先使用激活函数,然后通过线性层映射到更高的维度
# 即上图中ResNetBlock将Time Embeding通过SILU,Liner层,然后加到Latent Feature上
emb = self.time_embedding(t_emb, timestep_cond)在CrossAttention中,Latent Feature充当Q,Prompt充当K,V,计算交叉注意力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









