







目录
1.概念
NoSQL非关系型数据库是一种不使用关系模型来组织数据的数据库,通常用于存储非结构化或半结构化的数据,不支持或只部分支持SQL语言,满足最终一致性。非关系型数据库有多种类型,例如键值数据库、文档数据库、列式数据库、图形数据库、时序数据库等。非关系型数据库的优点是灵活性高、性能高、可扩展性强,适合处理海量数据和复杂数据类型。非关系型数据库的缺点是不提供事务支持,无法保证数据的完整性和安全性,功能不如关系型数据库完善。
Redis是一种非关系型数据库,属于键值数据库的一种,它使用键值对的方式存储数据,支持多种类型的值,如字符串、哈希、列表、集合、有序集合等。Redis的特点有:
高性能:Redis是基于内存的数据库,读写速度非常快,可以达到每秒10万次的读写性能。
持久化:Redis支持两种持久化方式,一种是快照(snapshotting),将内存中的数据定时保存到磁盘上;另一种是只追加文件(append-only file),将每次对数据库的写操作记录到文件中。
分布式:Redis支持主从复制(master-slave replication),可以实现数据的备份和负载均衡
丰富的功能:Redis除了提供基本的增删改查操作,还提供了事务、发布订阅、Lua脚本、管道等高级功能。
简单易用:Redis使用C语言编写,代码简洁,安装和使用都非常方便。
2.redis安装(ubuntu)
1.下载工具及安装
中文网站:http://redis.cn
官方网站:http://redis.io
把下载好的包上传到linux服务器上,如下图使用命令进行解压 安装

命令如下
解压命令
tar zxvf redis-4.0.8.tar.gz
进入到解压后目录,执行下面命令
make
sudo make install使用命令测试是否安装成功
启动redis
redis-server
打开一个新终端,使用客户端连接
redis-cli #默认连接本地主机,绑定6379端口
redis-cli -p 端口号 #指定端口连接本地
redis-cli -h IP地址 -p 端口号 #连接远程主机
通过客户端关闭服务器
shutdown
客户端的测试命令
ping如下图
2.redis使用命令
1.字符串类型使用命令
字符串类型都是以
key->string
value->string
的形式
命令1
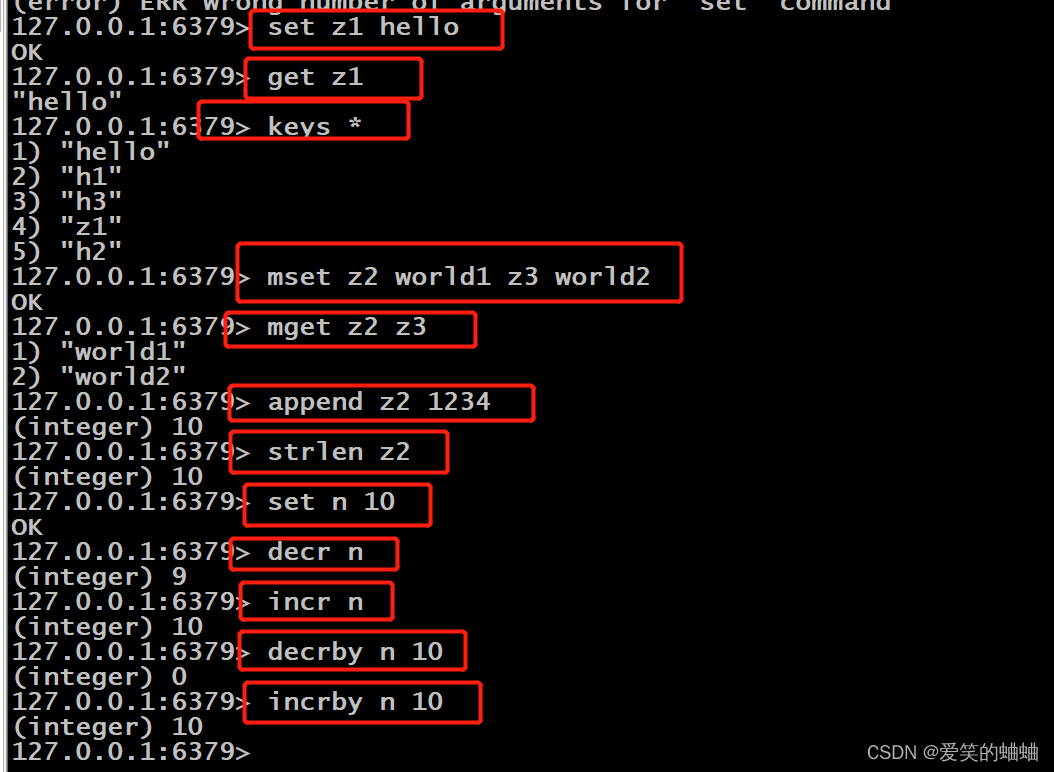
set key value #表示创建一个键值对,键值为key,值为value,如果已经存在则会被覆盖
命令2
keys * #表示查看所有的键值
命令3
get key #获取到指定键值的值
命令4
mset [key value] #表示一次创建多个键值对,例:get h1 world1 h2 world2
命令5
mget [key] #一次获取到多个指定键值的值
命令6
append key value #在指定键值后追加字符,如果指定键值不存在则会创建该键值
命令7
strlen key #查看指定键值的值的长度
命令8
decr key #只可以使用到数字字符,指定的键值减1
命令9
incr key #只可以使用到数字字符,指定的键值加1
命令10
decrby key 数字n #只可以使用到数字字符,指定的键值的值减n
命令11
incrby key 数字n #只可以使用到数字字符,指定的键值的值加n以下是操作例子
2.list(列表)类型使用命令
列表类型以
key->string
value->list
形式
命令1
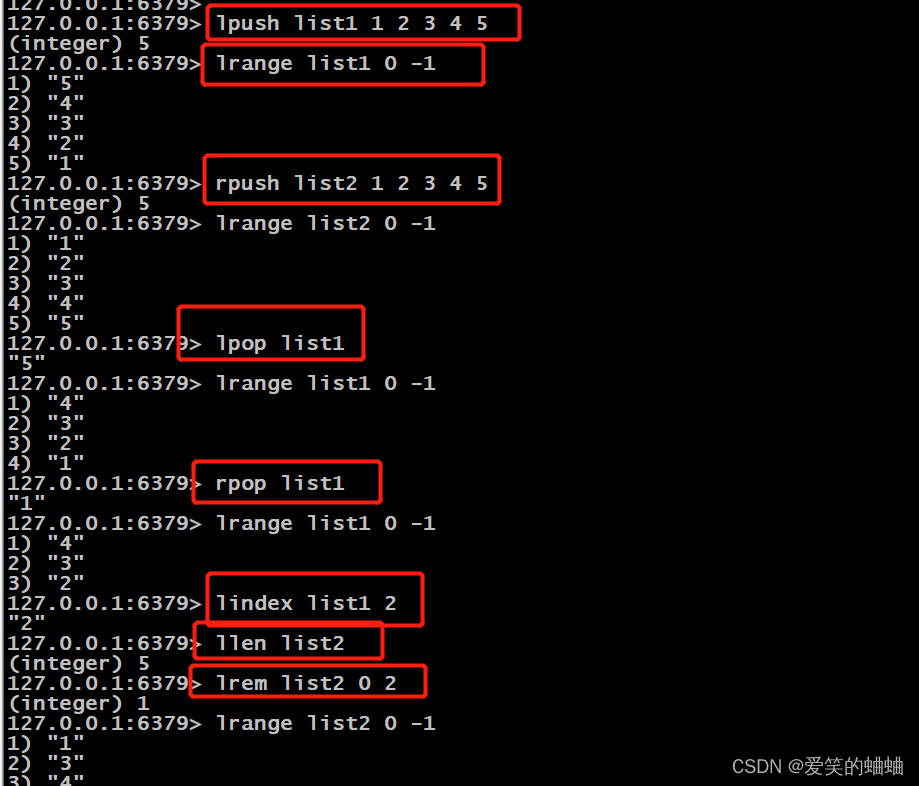
lpush key [value] #创建一条数据,将一个或多个值插入到列表key的表头
rpush key [value] #创建一条数据,将一个或多个值插入到列表key的表尾
命令2
lrange key start stop #遍历列表
key:遍历的列表名称
start:遍历的起始位置
stop:遍历的结束位置
命令3
lpop key #删除列表为key的表头元素
rpop key #删除列表为key的表尾元素
命令4
lindex key index #通过下表获取对应的值
key:要获取的列表名称
index:下标值
命令5
llen key #查看指定列表的长度
命令6
lrem key count value #根据参数 count 的值,移除列表中与参数 value 相等的元素。
count 的值可以是以下几种 :
count > 0: 从表头开始向表尾搜索,移除与 value 相等的元素,数量为 count 。
count < 0: 从表尾开始向表头搜索,移除与 value 相等的元素,数量为 count 的绝对值
count = 0 :移除表中所有与 value 相等的值以下是操作例子
3.set(集合)类型命令
set类型以
key->string
value->set类型(string,string...)
形式存储
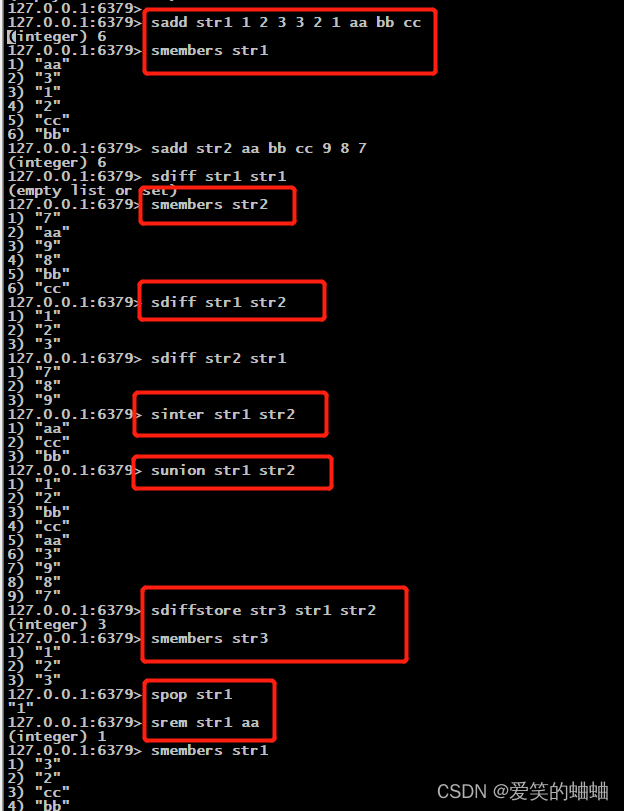
命令1
sadd key [member] #创建一个名称为key的集合,member为插入的值,插入到头部,不会有重复数据
命令2
smembers key #遍历集合
命令3
sdiff key1 key2 #求两个集合的差集
命令4
sinter key1 key2 #求两个集合的交集
命令5
sunion key1 key2 #求两个集合的并集
命令6
sdiffstore key key1 key2 #求key1和key2的集合的差集,并且把差集存放到key集合中
命令7
sinterstore key key1 key2 #和命令6一样,该命令求交集
命令8
sunionstore key key1 key2 #和命令6一样,该命令求并集
命令9
spop key #随机删除集合key中的一个元素
命令10
srem key [member] #删除集合key中指定的元素member
以下是操作例子
4.SortedSet(有序集类型)命令
有序集以
key->string
value->sorted[score,member]
的形式存储
命令1
zadd key [score,member] #创建一个有序集,插入一个或多个值到有序集key中
命令2
zrange key start stop [withscores] #遍历有序集key,按升序输出
zrevrange key start stop [withscores] #遍历有序集key,按降序输出
start:遍历的开始位置
stop:遍历的结束位置
命令3
zcount key min max #计算有序集key中,score值在min到max之间的个数
命令4
zrank key member #返回有序集key中成员member的排名,按成员score值递增排序
zrevrank key member #返回有序集key中成员member的排名,按成员score值递减排序
命令5
zrem key [member] #移除一个或多个元素
命令6
zscore key member #返回有序集key中成员member的score值
5.hsa(哈希)类型命令
hash类型以
key->string
value->hash[field:value,field:value]
的形式存储
命令1
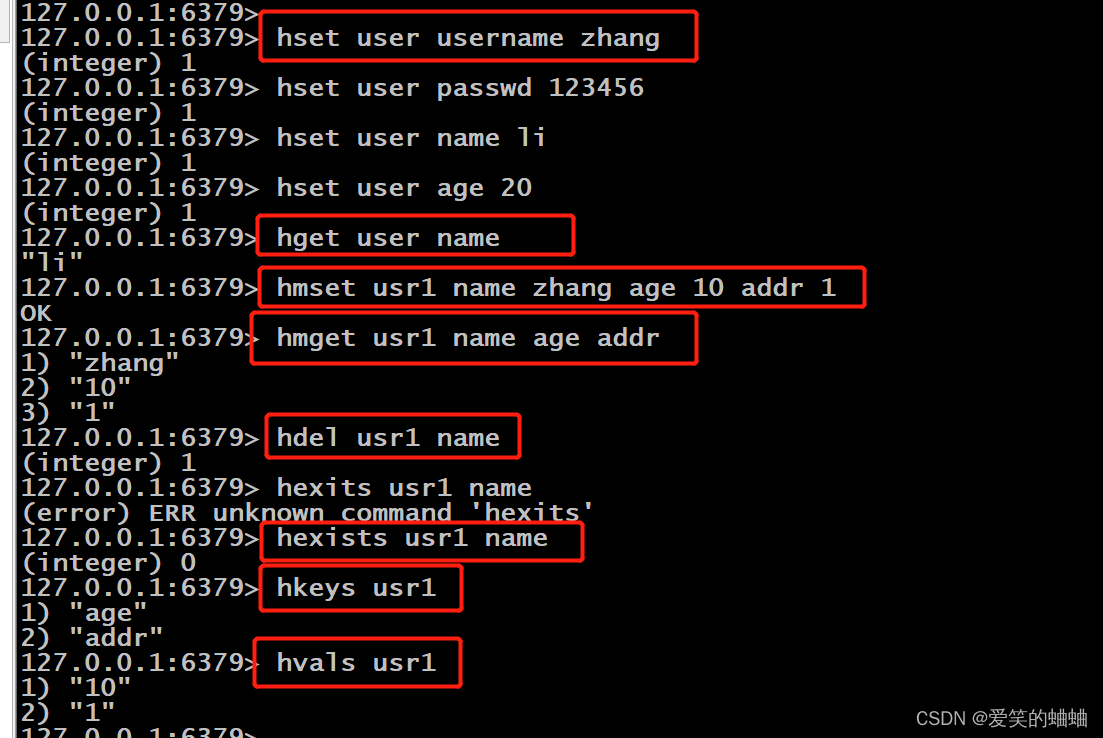
hset key field value #创建一个名为key的哈希表,并插入键值对field:value
命令2
hget key field #取出哈希表key中键为field的值
命令3
hmset key [field value] #可以同时插入多个键值对
命令4
hmget key [field] #可以同时获取多个值
命令5
hdel key [field] #删除哈希表中键值为field的值
命令6
hgetall key #输出哈希表的键和值
命令7
hkeys key #输出键
命令8
hvals key #输出值以下是操作例子
6.key操作
命令1
del [key] #删除名称为key的键值对
命令2
keys * ? [] #匹配key值
*:匹配一串字符
?:匹配一个字符
[]:匹配指定字符
命令3
expire key seconds #设置名称为key的键值存活实际,seconds表示秒
命令4
ttl key #查看存活时间,-1表示没有设置存活时间,-2表示不存在
命令5
persist key #移除给定key的生成时间
命令6
type key #返回key对应的value类型3.redis配置文件
文件redis.conf在上面解压包的目录下,如我的包是 redis-4.0.8.tar.gz ,就需要进入 redis-4.0.8的目录找,
一些配置文件的内容含义
1. bind 127.0.0.1 #绑定的ip地址,只有绑定的ip地址才可以访问到,注释默认所有ip地址都可访问
2. protected-mode yes #包含模式,要远程连接需要关闭,yes表示开启,no表示关闭
3. port 6379 #使用的端口号,默认6378
4.timeout 0 #超时时间,0表示不启用,>0表示启用
5.daemonize no #守护进程,no表示不是守护进程,yes表示是守护进程
6.pidfile /var/run/redis-b379.pid #如果不是守护进程不生效,如果是会生成一个pid文件,可以修改目录,./ -> 表示在redis启动的目录下
7.loglevel notice #日志级别
8.logfile "" #日志文件,要是守护进程才生效,这样表示不输出,
配置好文件后使用一下命令启动以及连接
启动:redis-server redis.conf
连接:redis-cli -p 端口号4.redis数据持久化
| 方式 | 生成文件 | 存储方式 | 优点 | 缺点 |
| rdb方式 | 生成 .rdb文件,默认打开 | 会将内存中的数据以二进制的形式写入到磁盘文件 | 文件比较小,恢复时间端,效率高 | 以用户设定的频率去同步数据,容易丢失数据,数据完整性较低 |
| aof方式 | 生成 .aof 文件 | 会把生成数据的命令写入到磁盘文件 | 每隔1秒钟进行一次数据同步,数据完整性高 | 文件较大,恢复时间床,效率低 |
一些配置文件内容,也是在 redis.conf 文件中
1.rdb的刷新频率,任何一个满足都会刷新
save 900 1
save 300 10
save 60 10000
2.dbfilename dump.rdb #rdb文件的名字
3.dir ./ #生成的持久化文件保存的目录,rdb和aof
4.appendonly no #是否要打开aof模式,yes表示是,no表示否
5.appendfilename "appendonly.aof" #设置aof文件的名字一些问题
1.aof和rdb能不能同时打开
可以
2.aof和rdb能不能同时关闭
可以
关闭rdb方式:save ""
3.两种模式同时开启,如果进行数据恢复,如何选择
效率上考虑:rdb模式
数据的完整性考虑:aof模式















 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











