






启动

一.【es-client】项⽬的pom.xml⽂件中,引⼊Spring Data Elasticsearch的启动器
<dependency><groupId> org.springframework.boot </groupId><artifactId> spring-boot-starter-data-elasticsearch </artifactId></dependency>
二.在resources⽬录下的application.yml⽂件中配置Elasticsearch的host和port信息
spring:
data:
elasticsearch:
cluster-name: elastic
cluster-nodes: 10.48.185.11:9301,10.48.185.93:9302,10.48.185.90:9300,10.48.185.77:9300
<!-- ES高级Rest Client -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.4.3</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.4.3</version>
</dependency>
需要注意的是,
Spring Data Elasticsearch
底层使⽤的不是
Elasticsearch
提供的
RestHighLevelClient
,⽽是 TransportClient,并不采⽤
HTTP
协议通信,⽽是访问
Elasticsearch
对外开放的
TCP
端⼝。我们在之前集群配置 中,设置的端⼝分别是:9301
、
9302
、
9303
。
加上以上配置如果你有启动报错,测试报错,请加上这句话
System.setProperty("es.set.netty.runtime.available.processors","false");

四.测试
创建⼀个
SpringDataESTests
测试类。通过
@Autowired
注解对 ElasticsearchTemplate进⾏注⼊,测试对象是否可以获取到
package com.qff.esclient.test;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.test.context.junit4.SpringRunner;
@SpringBootTest
@RunWith(SpringRunner.class)
public class SpringDataESTests {
@Autowired
private ElasticsearchTemplate template;
@Test
public void check() {
System.err.println(template);
}
}
如果运⾏
check()
⽅法报错,可能是以下问题所导致。

创建索引库
创建索引库需要使⽤到的注解:


package com.qff.esclient.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "product",type = "product",shards = 3,replicas = 1)
public class Product {
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title; // 标题
@Field(type = FieldType.Keyword)
private String category; // 分类
@Field(type = FieldType.Keyword)
private String brand; // 品牌
@Field(type = FieldType.Double)
private Double price; // 价格
@Field(type = FieldType.Keyword, index = false)
private String images; // 图⽚地址
}索引数据CRUD操作(一)
在
com.yx.respository
包下⾃定义
ProductRepository
接⼝,并继承
ElasticsearchRespository
接⼝。

1.创建索引数据
单个创建
@Autowired
private ProductRepository productRepository;
@Test
public void addDocument() {
Product product = new Product(1L, "⼩⽶⼿机Mix", "⼿机", "⼩⽶", 2899.00,
"http://image.yx.com/12479122.jpg");
// 添加索引数据
productRepository.save(product);
}
批量创建
@Test
public void addDocuments() {
// 准备⽂档数据
List<Product> list = new ArrayList<>();
list.add(new Product(5L, "荣耀V20", "⼿机", "华为", 2799.00,
"http://image.yx.com/12479122.jpg"));
// 添加索引数据
productRepository.saveAll(list);
}
查询索引数据
根据
id
查询数据

查询所有数据

⾃定义⽅法查询



引数据CRUD操作(二)(原生操作)
@Test
public void nativeQuery() {
/* 1 查询结果 */
// 1.1 原⽣查询构建器
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 1.2 source过滤
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[0], new String[0]));
// 1.3 搜索条件
queryBuilder.withQuery(QueryBuilders.matchQuery("title", "⼿机"));
// 1.4 分⻚及排序条件
queryBuilder.withPageable(PageRequest.of(0, 2, Sort.by(Sort.Direction.ASC,
"price")));
// 1.5 ⾼亮显示
HighlightBuilder.Field field = new HighlightBuilder.Field("title");
field.preTags("<span style='color:red'>");
field.postTags("</span>");
queryBuilder.withHighlightFields(field);
// 1.6 聚合
queryBuilder.addAggregation(AggregationBuilders.terms("brandAgg").field("brand"));
// 1.7 构建查询条件,并且查询
// AggregatedPage<Product> result = template.queryForPage(queryBuilder.build(),
Product.class);
AggregatedPage<Product> result = template.queryForPage(queryBuilder.build(),
Product.class, new ProductSearchResultMapper());
/* 2 解析结果 */
// 2.1 分⻚结果
long total = result.getTotalElements();
int totalPages = result.getTotalPages();
List<Product> list = result.getContent();
System.out.println("总条数:" + total);
System.out.println("总⻚数:" + totalPages);
System.out.println("数据:" + list);
// 2.2 聚合结果
/*
Aggregations aggregations = result.getAggregations();
// 导包org.elasticsearch.search.aggregations.bucket.terms.Terms
Terms terms = aggregations.get("brandAgg");
terms.getBuckets().forEach(b -> {
System.out.println("品牌:" + b.getKeyAsString());
System.out.println("count:" + b.getDocCount());
});
*/
}
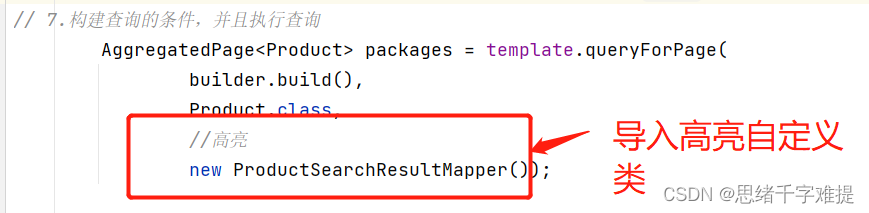
高亮自定义类
package com.qff.esclient.sercive;
import com.google.gson.Gson;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.data.elasticsearch.core.SearchResultMapper;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.aggregation.impl.AggregatedPageImpl;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/** ⾃定义查询结果映射,⽤于处理⾼亮显示 */
public class ProductSearchResultMapper implements SearchResultMapper {
/**
* 完成查询结果映射。将_source取出,然后放⼊⾼亮的数据
*/
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse searchResponse, Class<T> aClass, Pageable pageable) {
// 记录总条数
long totalHits = searchResponse.getHits().getTotalHits();
// 记录列表(泛型) - 构建Aggregate使⽤
List<T> list = new ArrayList<>();
// 获取搜索结果(真正的的记录)
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
if (hits.getHits().length <= 0) {
return null;
}
// 将原本的JSON对象转换成Map对象
Map<String, Object> map = hit.getSourceAsMap();
// 获取⾼亮的字段Map
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
for (Map.Entry<String, HighlightField> highlightField : highlightFields.entrySet()) {
// 获取⾼亮的Key
String key = highlightField.getKey();
// 获取⾼亮的Value t
HighlightField value = highlightField.getValue();
// 实际fragments[0]就是⾼亮的结果,⽆需遍历拼接
Text[] fragments = value.getFragments();
// 因为⾼亮的字段必然存在于Map中,就是key值
map.put(key, fragments[0].toString());
}
// 把Map转换成对象
Gson gson = new Gson();
T item = gson.fromJson(gson.toJson(map), aClass);
list.add(item);
}// 返回的是带分⻚的结果
return new AggregatedPageImpl<>(list, pageable, totalHits);
}
@Override
public <T> T mapSearchHit(SearchHit searchHit, Class<T> aClass) {
return null;
}
}














 1560
1560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









