







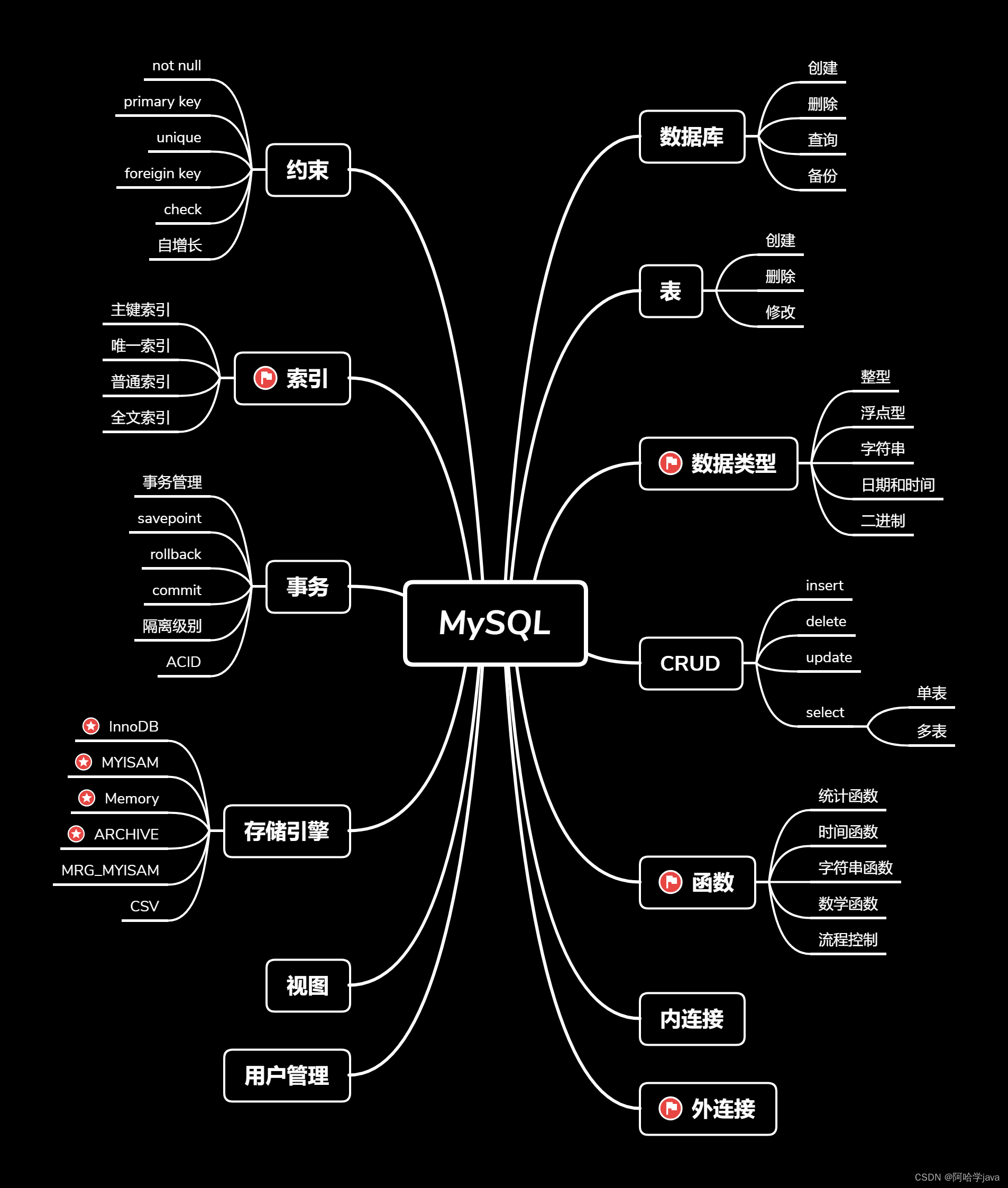
数据库
数据库存储位置
数据库的存储位置取决于你把数据库放建在哪,你建你在你电脑本地,那数据库就在本地。你放服务器上,那数据库就在服务器上。本质跟你在本地新建一个Excel表,和在百度云上建,是同一个道理。
创建数据库
代码实例
-- 创建数据库
CREATE DATABASE 数据库名
-- 删除数据库
DROP DATABASE 数据库名
-- 创建指定格式为utf8字符集的数据库
CREATE DATABASE 数据库名 CHARACTER SET utf8
-- 创建字符集utf8,校对规则为utf8_bin(区分大小写)的数据库
CREATE DATABASE 数据库名 CHARACTER SET COLLATE utf8_bin
-- 创建字符集utf8,校对规则为utf8_general_ci
CREATE DATABASE 数据库名 CHARACTER SET COLLATE utf8_general_ci
细节: 系统使用utf8字符集,若使用utf8_bin校对规则执行SQL查询时区分大小写,使用utf8_general_ci不区分大小写(默认的utf8字符集对应的校对规则是utf8_general_ci)。
查询数据库
代码实例
#查看当前数据库服务器中的所有数据库
#细节:记得加s
SHOW DATABASES
#查看前面创建的hsp__db01数据库的定义信息
SHOW CREATE DATABASE `数据库名`
#细节:在创建数据库,表的时候,为了规避关键字,可以使用反引号引用
#注:反引号在esc键下面
删除数据库
代码实例
#删除已经创建数据库
DROP DATABASE 数据库名
备份数据库
1.首先在Dos命令窗口执行mysqldump备份指令
备份,要在Dos下执行mysqldump指令其实在mysql安装目录\bin
这个备份的文件,就是对应的sql语句
mysqldump -u root -P -B 数据库名 > d: \\bak. sql(自定义路径加文件名.后缀)
如下图所示
备份成功bbb和t1两个数据库
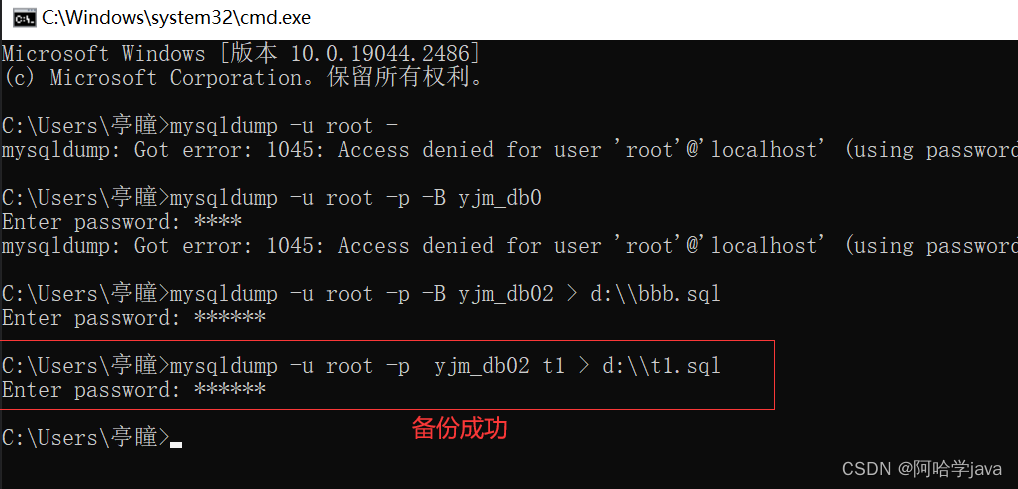
备份成功可在对应路径看到文件

恢复备份数据库
方法一
1.以管理员身份进入到Dos窗口
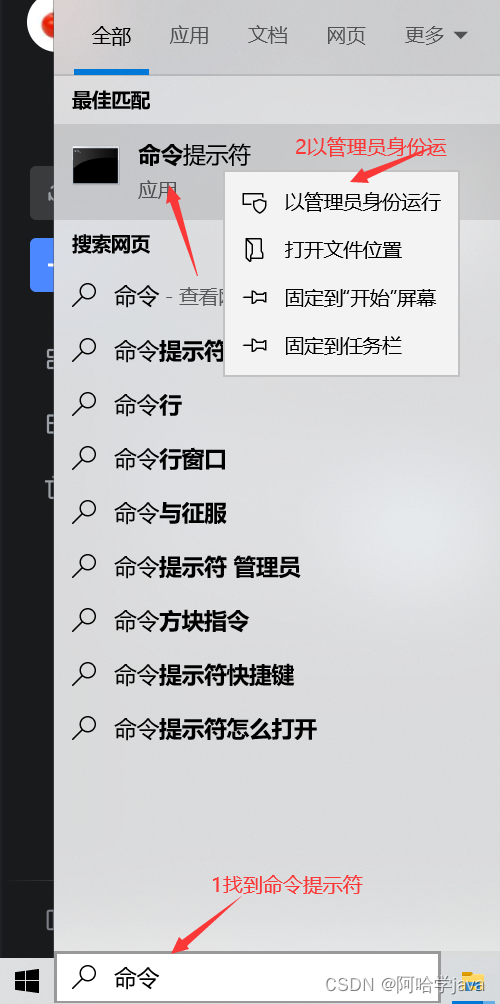
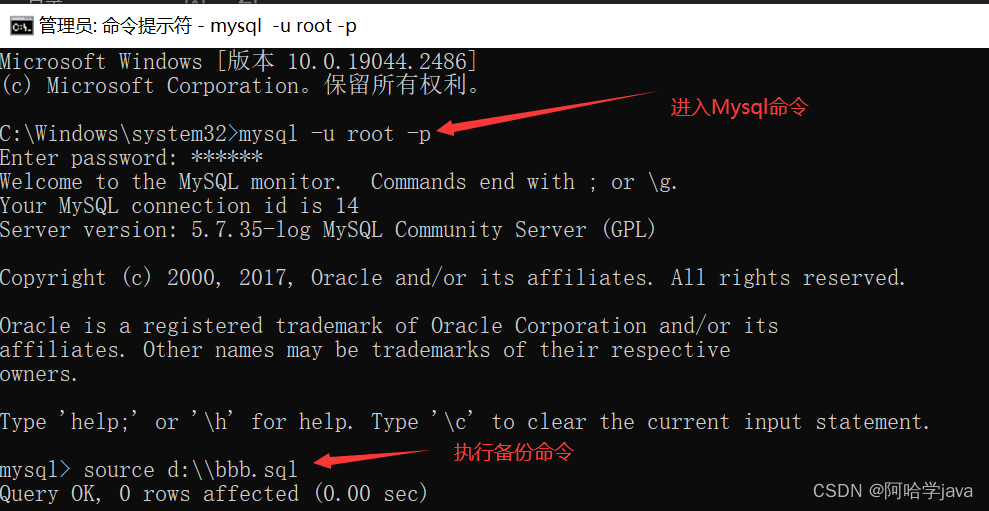
2.在窗口输入mysql -u root -p 进入mysql
3.执行备份命令:
source d: \ \bbb. sql(路径加文件名.后缀sql)
方法二
把备份的文件bbb.sql里面的内容复制粘贴到查询编辑器重新跑一遍就可以恢复!
补充:忘记自己的用户名?
一般自己默的用户名为root,不记得可以看这个链接进行查询
备份数据库的表
命令行如下,其他同理
mysqldump -u 用户名 -p密码 数据库名 表1名 表2名 表n名 >d:\\文件名.sql
恢复出现的错误:
恢复失败的原因是在备份的时候没有没有写全双斜杠

数据类型
整型
| 类型名称 | 取值范围 | 大小 |
|---|---|---|
| TINYINT | -128〜127 | 1个字节 |
| SMALLINT | -32768〜32767 | 2个宇节 |
| MEDIUMINT | -8388608〜8388607 | 3个字节 |
| INT (INTEGHR) | -2147483648〜2147483647 | 4个字节 |
| BIGINT | -9223372036854775808〜9223372036854775807 | 8个字节 |
无符号在数据类型后加 unsigned 关键字。
浮点型
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| FLOAT | 单精度浮点数 | 4 个字节 |
| DOUBLE | 双精度浮点数 | 8 个字节 |
| DECIMAL (M, D),DEC | 压缩的“严格”定点数 | M+2 个字节 |
DECIMAL[M,D] [UNSIGNED] 详解
可以支持更加精确的小数位。M是小数位数(精度)的总数,D是小数点(标度)后面的位数。
如果D是0,则值没有小数点或分数部分。M最大65。D最大是30。 如果D被省略,默认是0。 如果M被省略,默认是10。
建议:如果希望小数的精度高,推荐使用decimal
字符串
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| CHAR(M) | 固定长度非二进制字符串 | M 字节,1<=M<=255 |
| VARCHAR(M) | 变长非二进制字符串 | L+1字节,在此,L< = M和 1<=M<=255 |
| TINYTEXT | 非常小的非二进制字符串 | L+1字节,在此,L<2^8 |
| TEXT | 小的非二进制字符串 | L+2字节,在此,L<2^16 |
| MEDIUMTEXT | 中等大小的非二进制字符串 | L+3字节,在此,L<2^24 |
| LONGTEXT | 大的非二进制字符串 | L+4字节,在此,L<2^32 |
| ENUM | 枚举类型,只能有一个枚举字符串值 | 1或2个字节,取决于枚举值的数目 (最大值为65535) |
| SET | 一个设置,字符串对象可以有零个或 多个SET成员 | 1、2、3、4或8个字节,取决于集合 成员的数量(最多64个成员) |
细节一
-
char(4) :这个4表示字符数(最大255个字符),不是字节数,不管是中文还是字母都是放四个,按字符计算
-
varchar(4):这个4表示字符数,不管是字母还是中文都以定义好的表的编码来存放数据,不管是中文还是英文字母,都是最多存放4个,是按照字符来存放的。
-
GBK是两个字节表示一个中文字符的,utf8是三个字节表示一个中文字符;
所以varchar(12)在utf8字符集下只能存放4个汉字。
- 字符串的字节大小由定义的表的编码来决定
解释:GBK字符集有可能最大是4×2=8个字节;而utf8字符集最大是4×3=12个字节
代码实例
#演示字符串类型使用char varchar
#注释的快捷键shift+ctrl+c ,注销注释shift+ctrl+r
-- CHAR(size)
-- 固定长度字符串最大255字符
-- VARCHAR(size) 0~65535字节
-- 可变长度字符串最大65532字节 [ utf8编码最大21844字符 1-3个字节用于记录大小]
-- 如果表的编码是utf8 varchar(size) size = (65535-3) / 3 = 21844
-- 如果表的编码是gbk varchar(size) size = (65535-3) / 2 = 32766
#创建一个表
CREATE TABLE t09 (
`name` CHAR(255)) ;#`name`这个字段能存放255个字符(英文字母或汉字都只能放255个)
CREATE TABLE t10 (
`name` VARCHAR (32766)) CHARSET gbk;#`name`这个字段能存放32766个字符(英文字母或汉字都只能放32766个)
细节二
-
char(4)是定长(固定的大小),就是说,即使你插入’aa’,也会占用分配的4个字符的空间
-
varchar(4)是变长(变化的大小),就是说,如果你插入了’aa’,实际占用空间大小并不是4个字符,而是按照实际占用空间来分配
-
说明:varchar本身还需要占用1-3个字节来记录存放内容长度
总大小=L(实际数据大小)+(1-3)字节
细节三
- 什么时候使用char ,什么时候使用varchar
1) 如果数据是定长,推荐使用char,比如md5的密码,邮编,手机号,身份证号码等. char(32)
2) 如果一个字段的长度是不确定,我们使用varchar ,比如留言,文章
- 查询速度:char > varchar
细节四
在存放文本时,也可以使用Text数据类型.可以将TEXT列视为VARCHAR列,注意Text不能有默认值,大小0-2^16字节
如果希望存放更多字符,可以选择MEDIUMTEXT 可存0-2^24字节或者LONGTEXT 可存 0~2^32字节
日期和时间
| 类型名称 | 日期格式 | 日期范围 | 存储需求 |
|---|---|---|---|
| YEAR | YYYY | 1901 ~ 2155 | 1 个字节 |
| TIME | HH:MM:SS | -838:59:59 ~ 838:59:59 | 3 个字节 |
| DATE | YYYY-MM-DD | 1000-01-01 ~ 9999-12-3 | 3 个字节 |
| DATETIME | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 8 个字节 |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS | 1980-01-01 00:00:01 UTC ~ 2040-01-19 03:14:07 UTC | 4 个字节 |
TimeStamp时间戳在Insert和update时会自动更新时间
代码实例
-- 示范创建时间戳
CREATE TABLE t4 (
birthday DATE, #精确到年月日
job_time DATETIME ,#精确到年月日时分秒
#添加时间戳
login TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP) ;#login在插入数据的时候就会自动更新时间,精确到年月日时分秒
# 删除表后重新创建表
TRUNCATE TABLE t4
#细节:当添加了默认时间戳后再插入数据要指定字段并把时间戳字段设置为空
#方法1:
INSERT INTO t4 VALUE('1999-06-06','2022-06-06 09:30',NULL)
#方法2:
INSERT INTO t4(birthday,job_time) VALUE ('1999-06-06','2022-06-06 09:30')
#错误示范
INSERT INTO t4 VALUE('1999-06-06','2022-06-06 09:30') #错错错
二进制类型
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| BIT(M) | 位字段类型 | 大约 (M+7)/8 字节 |
| BINARY(M) | 固定长度二进制字符串 | M 字节 |
| VARBINARY (M) | 可变长度二进制字符串 | M+1 字节 |
| TINYBLOB (M) | 非常小的BLOB | L+1 字节,在此,L<2^8 |
| BLOB (M) | 小 BLOB | L+2 字节,在此,L<2^16 |
| MEDIUMBLOB (M) | 中等大小的BLOB | L+3 字节,在此,L<2^24 |
| LONGBLOB (M) | 非常大的BLOB | L+4 字节,在此,L<2^32 |
表操作
查询当前数据库所有表:
SHOW TABLES;
查询表结构:
DESC 表名;
查询指定表的建表语句:
SHOW CREATE TABLE 表名;
创建表:
CREATE TABLE 表名(
字段1 字段1类型 [COMMENT 字段1注释],
字段2 字段2类型 [COMMENT 字段2注释],
字段3 字段3类型 [COMMENT 字段3注释],
...
字段n 字段n类型 [COMMENT 字段n注释]
)[ COMMENT 表注释 ];
最后一个字段后面没有逗号
删除表:
DROP TABLE [IF EXISTS] 表名;
删除表,并重新创建该表:
TRUNCATE TABLE 表名;
使用ALTER TABLE语句追加,修改,或删除列(字段)的语法
-
添加列
ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT 注释] [约束];
例:ALTER TABLE emp ADD nickname varchar(20) COMMENT '昵称'; -
修改列
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束];例:将emp表的nickname字段修改为username,类型为varchar(30)
ALTER TABLE emp CHANGE nickname username varchar(30) COMMENT '昵称'; -
删除列 : 就是删除掉整列数据
ALTER TABLE 表名 DROP 字段名; -
查看表的结构:
desc 表名;– 可以查看表的列 -
修改表名:
alter table 表名 to 新表名 -
修改表字符集:
alter table 表名 character set 字符集;
#列名name修改为username,这列是列名啊大哥
ALTER TABLE employee CHANGE `name` `username` VARCHAR (32) NOT NULL DEFAULT '';
DML(数据操作语言)
更新数据(insert)
细节说明
- 插入的数据应与字段的数据类型相同。比如把’abc’添加到int类型会错误
- 数据的长度应在列的规定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中。
- 在values中列出的数据位置必须与被加入的列的排列位置相对应。
- 字符和日期型数据应包含在单引号中。
- 列可以插入空值[前提是该字段允许为空],insert into table value(nulI)
- insert into tab_name (列名…) values (),(),()形式添加多条记录
- 如果是给表中的所有字段添加数据,可以不写前面的字段名称
- 默认值的使用,当不给某个字段值时,如果有默认值就会添加默认值,否则报错
- 如果某个列没有指定notnull,那么当添加数据时,没有给定值,则会默认给null
- 如果我们希望指定某个列的默认值,可以在创建表时指定
代码实例
#创建表
#顺便给个默认值先
DROP TABLE goods CREATE TABLE goods (
id INT,
`name` VARCHAR (10),
price DOUBLE NOT NULL DEFAULT '0'
) #插入数据
INSERT INTO goods (id, `name`) VALUE (1, '超级无敌手机') #查询
SELECT * FROM goods
更新数据(update)
修改数据:UPDATE 表名 SET 字段名1 = 值1, 字段名2 = 值2, ...[ WHERE 条件 ];
例:UPDATE emp SET name = 'Jack' WHERE id = 1;
删除数据:DELETE FROM 表名 [ WHERE 条件 ];
代码实例
#更新员工信息
SELECT * FROM employee
#把我的工资修改到3w
UPDATE employee
SET salary = 20000,id=1,image = '暂无',phone=17840,`resume`='打杂的'
WHERE username ='游锦民'
#修改数据很重要的是where条件,如果不带条件就会修改整个表的那一列
使用细节
- UPDATE语法可以用新值更新原有表行中的各列。
- SET子句指示要修改哪些列和要给予哪些值。
- WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行(记录)。
- .如果需要修改多个字段,可以通过set 字段1=值1,字段2=值2…。
基础查询(select)
查询多个字段:
SELECT 字段1, 字段2, 字段3, ... FROM 表名;
SELECT * FROM 表名;
设置别名:
SELECT 字段1 [ AS 别名1 ], 字段2 [ AS 别名2 ], 字段3 [ AS 别名3 ], ... FROM 表名;
SELECT 字段1 [ 别名1 ], 字段2 [ 别名2 ], 字段3 [ 别名3 ], ... FROM 表名;
去除重复记录:
SELECT DISTINCT 字段列表 FROM 表名;
转义:
SELECT * FROM 表名 WHERE name LIKE '/_张三' ESCAPE '/'
/ 之后的_不作为通配符
条件查询
语法:
SELECT 字段列表 FROM 表名 WHERE 条件列表;
注意事项(创建测试表学生表)
- Select指定查询哪些列的数据。
- column指定列名。
- *星号代表查询所有列。
- From指定查询哪张表。
- DISTINCT可选,指显示结果时,是否去掉重复数据
代码实例
CREATE TABLE student(
id INT NOT NULL DEFAULT 1,
NAME VARCHAR(20) NOT NULL DEFAULT '',
chinese FLOAT NOT NULL DEFAULT 0.0,
english FLOAT NOT NULL DEFAULT 0.0,
math FLOAT NOT NULL DEFAULT 0.0
);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(1,'韩顺平',89,78,90);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(2,'张飞',67,98,56);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(3,'宋江',87,78,77);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(4,'关羽',88,98,90);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(5,'赵云',82,84,67);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(6,'欧阳锋',55,85,45);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(7,'黄蓉',75,65,30);
-- 查询表中所有学生的信息。
SELECT * FROM student
-- 查询表中所有学生的姓名和对应的英语成绩。
SELECT `name`,english FROM student
-- 过滤表中重复数据distinct,过滤英语成绩
SELECT DISTINCT english FROM student #过滤一个78
-- 要查询的记录,每个字段都相同,才会去重
AS起别名
在select语句中可使用as语句 SELECT 字段名 as 别名 from 表名;
代码实例
-- 练习select02.sql
-- 1.统计每个学生的总分
#细节1:不要打错列名,多用tab
SELECT `name`,(chinese+english+math) FROM student
-- 2.在所有学生总分加10分的情况
SELECT `name`,(chinese + english +math +10) FROM student
-- 3.使用别名表示学生分数。
SELECT `name` ,(chinese + english + math) AS `total_score` FROM student
-- 课后练习
-- 在赵云的总分上增加60%
-- SELECT 字段列表 FROM 表名 WHERE 条件列表;
#细节1:查询的时候并不会永久改变表数据,所以下一次查询不用用上一次查询的结果
#细节2:需要查看单独某一列就要加 where 条件
SELECT * FROM student
#起个别名就好看多了
SELECT `name`,(chinese + english + math)* 1.6 AS total FROM student WHERE `name`='赵云'
-- 统计关羽的总分。
SELECT `name`,(chinese + english + math) AS total_score FROM student WHERE `name`='关羽'
-- 使用别名表示学生的数学分数。
#细节1:如果要查询所有数据直接带 * 即可,另外起别名就使用 数据源 as 别名 即可
SELECT *, math AS '数学' FROM student
条件查询(where)
语法:
SELECT 字段列表 FROM 表名 WHERE 条件列表;
运算符
条件:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN … AND … | 在某个范围内(含最小、最大值) |
| IN(…) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_匹配单个字符,%匹配任意个字符) |
| IS NULL | 是NULL |
| 逻辑运算符 | 功能 |
|---|---|
| AND 或 && | 并且(多个条件同时成立) |
| OR 或 || | 或者(多个条件任意一个成立) |
| NOT 或 ! | 非,不是 |
代码实例1
-- 使用where子句,进行过滤查询select03.sql
-- 查询姓名为赵云的学生成绩
SELECT * FROM student WHERE `name`='赵云'
-- 查询英语成绩大于90分的同学
SELECT * FROM student WHERE english >90
-- 查询总分大于200分的所有同学
SELECT * FROM student WHERE (chinese + english + math)>200
-- 使用where子句,课堂练习[5min]:
-- 查询math大于60并且(and) id大于3的学生成绩
SELECT * FROM student WHERE math >60 AND id >3
-- 查询英语成绩大于语文成绩的同学
SELECT * FROM student WHERE english > chinese
-- 查询总分大于200分并且数学成绩大于语文成绩的姓韩的学生
#细节1:__ 两个下横杠表示两个任意字符 , % 表示任意个字符
#细节2:like 表示模糊查找,like 前面要写字段列表 比如 `name` LIKE '韩%':表示韩开头就行
SELECT * FROM student WHERE (chinese + english + math)>200 AND math > chinese AND `name` LIKE '韩%'
代码实例2
-- 课堂练习[学员自己练习]
-- 1.查询语文分数在70 - 80之间的同学。
#区间使用between and
SELECT * FROM student WHERE chinese BETWEEN 70 AND 80;
-- 2.查询总分为189,190,191的同学。
SELECT * FROM student WHERE (chinese + english + math) IN (189,190,191)
-- 3.查询所有姓李或者姓宋的学生成绩。
#细节:如果有两个条件需要or,要分开写,即使是同一个字段
SELECT * FROM student WHERE `name` LIKE '李%' OR `name` LIKE '宋%'
-- 4.查询数学比语文多2分的同学。
SELECT * FROM student WHERE (math-chinese) = 1
排序查询(order by)
语法:
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1, 字段2 排序方式2;
排序方式:
- ASC: 升序(默认)
- DESC: 降序
细节:
- Order by指定排序的列,排序的列既可以是表中的列名,也可以是select语句后指定的列名。
- Asc 升序[默认]、Desc 降序
- ORDER BY子句应位于SELECT语句的结尾。
- 如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
代码实例
-- 课堂练习: orderby.sql
-- 对数学成绩排序后输出[升序]。
SELECT * FROM student ORDER BY math;
-- 对总分按从高到低的顺序输出
SELECT
*,
(chinese + english + math) AS totalscore
FROM
student
ORDER BY totalscore # 这样查询还能查出其他科目的成绩
-- 对姓韩的学生成绩排序输出(降序)
# as是起别名
#where 是查找条件
SELECT
*,
(chinese + english + math) AS totalscore
FROM
student
WHERE `name` LIKE '韩%'
ORDER BY totalscore DESC ;
函数
统计函数
合计/统计函数(count)
功能:Count返回行的总数
语法:
SELECT 聚合函数(字段列表) FROM 表名;
例:
SELECT count(id) from employee where workaddress = "广东省";
代码实例
课堂练习: statistics.sql
-- 统计一个班级共有多少学生?
SELECT COUNT(*) FROM student #8
-- 统计数学成绩大于80的学生有多少个?
SELECT COUNT(*) FROM student WHERE math>80 #2
SELECT COUNT(`name`) FROM student WHERE math>80 #2
-- 统计总分大于250的人数有多少?
SELECT COUNT(*) FROM student WHERE (chinese + english + math)>250 #2
-- count(*)和count(列)的区别
# 细节1:count(*)返回满足条件的记录行数
# 细节2:统计某列满足条件的有多少个,会排除为null的条件
求和函数(sum)
功能:Sum函数返回满足where条件的行的和,一般使用在数值列
Select sum (列名).. from 表名 WHERE 条件
代码实例
-- 统计一个班级数学总成绩?
SELECT SUM(math) FROM student
-- 统计一个班级语文、英语、数学各科的总成绩
SELECT SUM(chinese),SUM(english),SUM(math) FROM student
-- 统计一个班级语文、英语、数学的成绩总和
SELECT SUM(chinese + english + math) FROM student
-- 统计一个班级语文成绩平均分
SELECT SUM(chinese)/COUNT(*)FROM student#77.25
#注意1: sum仅对数值起作用,没有意义。
#注意2:对多列求和,逗号不能少。
平均函数(avg)
功能:AVG函数返回满足where条件的一列的平均值
Select avg(列名) {,avg(列名...} from 表名 [WHERE 条件]
代码实例
-- 求一个班级数学平均分?
SELECT AVG(math) FROM student
-- 求一个班级总分平均分?
SELECT AVG(chinese + english + math) FROM student
最大函数(Max/min)
功能:Max/min函数返回满足where条件的一列的最大/最小值
Select max (列名) from tablename [WHERE where defini tion ]
代码实例
-- 演示max和min的使用
-- 求班级最高分和最低分(数值范围在统计中特别有用)
SELECT MAX(chinese + english + math) ,
MIN(chinese + english + math) FROM student;
# 细节:函数名和扩不能有空格,MAX()不能写成MAX ()!!!
分组查询(group by)
功能:使用 group by子句对列进行分组
语法:
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后的过滤条件 ];
CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
);
INSERT INTO dept VALUES(10, 'ACCOUNTING', 'NEW YORK'), (20, 'RESEARCH', 'DALLAS'), (30, 'SALES', 'CHICAGO'), (40, 'OPERATIONS', 'BOSTON');
SELECT * FROM dept;
#创建表EMP雇员
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED ,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) ,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
);
SELECT * FROM emp
#添加员工数据
INSERT INTO emp VALUES(7369, 'SMITH', 'CLERK', 7902, '1990-12-17', 800.00,NULL , 20),
(7499, 'ALLEN', 'SALESMAN', 7698, '1991-2-20', 1600.00, 300.00, 30),
(7521, 'WARD', 'SALESMAN', 7698, '1991-2-22', 1250.00, 500.00, 30),
(7566, 'JONES', 'MANAGER', 7839, '1991-4-2', 2975.00,NULL,20),
(7654, 'MARTIN', 'SALESMAN', 7698, '1991-9-28',1250.00,1400.00,30),
(7698, 'BLAKE','MANAGER', 7839,'1991-5-1', 2850.00,NULL,30),
(7782, 'CLARK','MANAGER', 7839, '1991-6-9',2450.00,NULL,10),
(7788, 'SCOTT','ANALYST',7566, '1997-4-19',3000.00,NULL,20),
(7839, 'KING','PRESIDENT',NULL,'1991-11-17',5000.00,NULL,10),
(7844, 'TURNER', 'SALESMAN',7698, '1991-9-8', 1500.00, NULL,30),
(7900, 'JAMES','CLERK',7698, '1991-12-3',950.00,NULL,30),
(7902, 'FORD', 'ANALYST',7566,'1991-12-3',3000.00, NULL,20),
(7934,'MILLER','CLERK',7782,'1992-1-23', 1300.00, NULL,10);
#工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
SELECT * FROM salgrade
#演示group by + having
GROUPby用于对查询的结果分组统计,(示意图)
-- having子句用于限制分组显示结果.
-- ?如何显示每个部门的平均工资和最高工资
-- avg(sal) max(sal)
-- 按照部门来分组查询
SELECT AVG(sal), MAX(sal),deptno
FROM emp GROUP BY deptno;
-- ?显示每个部门的每种岗位的平均工资和最低工资
#分组的标准变成两个,先按照部门再按照岗位分
SELECT AVG(sal),MIN(sal),deptno,job
FROM emp GROUP BY deptno,job
-- ?显示平均工资低于2000的部门号和它的平均工资//别名
SELECT AVG(sal),deptno
FROM emp GROUP BY deptno
HAVING AVG(sal)<2000
#使用别名,效率更高,函数不用计算两次
SELECT AVG(sal) AS avg_sal,deptno
FROM emp GROUP BY deptno
HAVING avg_sal<2000
细节
- 执行顺序:where > 聚合函数 > having
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
字符串函数
常用函数:
| 函数 | 功能 |
|---|---|
| CONCAT(s1, s2, …, sn) | 字符串拼接,将s1, s2, …, sn拼接成一个字符串 |
| LOWER(str) | 将字符串全部转为小写 |
| UPPER(str) | 将字符串全部转为大写 |
| LPAD(str, n, pad) | 左填充,用字符串pad对str的左边进行填充,达到n个字符串长度 |
| RPAD(str, n, pad) | 右填充,用字符串pad对str的右边进行填充,达到n个字符串长度 |
| TRIM(str) | 去掉字符串头部和尾部的空格 |
| SUBSTRING(str, start, len) | 返回从字符串str从start位置起的len个长度的字符串 |
| REPLACE(column, source, replace) | 替换字符串 |
代码实例
演示字符串函数
-- CHARSET(str) 返回字串字符集
-- CONCAT (string2 [,... ]) 连接字串
-- INSTR (string ,substring ) 返回substring在string中出现的位置,没有返回0
-- UCASE (string2 ) 转换成大写
-- LCASE (string2 ) 转换成小写
-- LEFT (string2 length ) 从string2中的左边起取length个字符
-- LENGTH (string) string长度[按照字节]
-- REPLACE (str ,search_ str,replace_ _str ) 在str中用replace_ str 替换search_ str
-- STRCMP (string1 ,string2 ) 逐字符比较两字串大小,
-- SUBSTRING (str,position [, length 从str的position开始[从1开始计算] ,取length个字符
-- LTRIM (string2 ) RTRIM (string2 ) 去除前端空格或后端空格
-- trim 同时去除前后
-- CHARSET(str) 返回字串字符集
SELECT CHARSET(ename) FROM emp #utf8
-- CONCAT (string2 [,... ]) 连接字串
SELECT * FROM emp
SELECT CONCAT(ename,'是一名',job) FROM emp #把名字和工作连接在一起
-- INSTR (string ,substring ) 返回substring在string中出现的位置,没有返回0
SELECT INSTR('youjinmin','min') FROM DUAL #返回7
# DUAL叫亚元表,系统表,可以作为测试使用
-- UCASE (string2 ) 转换成大写
SELECT UCASE(ename) FROM emp
-- LCASE (string2 ) 转换成小写
SELECT LCASE(ename) FROM emp
-- LEFT (string2,length ) 从string2中的左边起取length个字符
SELECT LEFT(ename,1) FROM emp
#由此可以解决以字母为小写的方式显示名字
SELECT CONCAT(LCASE(LEFT(ename,1)),LEFT(ename,LENGTH(ename))) FROM emp
-- LENGTH (string ) string长度[按照字节]
SELECT LENGTH (ename) FROM emp
-- REPLACE (str ,search_ str,replace__str ) 在str中用replace_ str 替换search_ str
SELECT REPLACE ('游锦民','游','龙') FROM DUAL #龙锦民
#第二种方法解决题目,把首字母替换成小写字母即可
SELECT REPLACE (ename,LEFT(ename,1),LCASE(LEFT(ename,1))) FROM emp
-- STRCMP (string1 ,string2 ) 逐字符比较两字串大小,
SELECT STRCMP('yjm','ljm') FROM DUAL #返回1
-- SUBSTRING (str,position [, length]) 从str的position开始[从1开始计算] ,取length个字符
SELECT SUBSTRING(ename,2,2) FROM emp #从第二个开始获取两个字符
-- LTRIM (string2 ) RTRIM (string2 ) 去除前端空格或后端空格
-- trim 去除前端和后端空格
SELECT LTRIM(' 张无忌学java') FROM DUAL
#去除后端空格
SELECT RTRIM(' 张无忌学java ') FROM DUAL
SELECT TRIM(' 张无忌学java ') FROM DUAL
#细节1:即使没有空格也不会报错
#注意:函数后面不要带空格再接括号
数学函数
常见函数:
| 函数 | 功能 |
|---|---|
| CEIL(x) | 向上取整 |
| FLOOR(x) | 向下取整 |
| MOD(x, y) | 返回x/y的模 |
| RAND() | 返回0~1内的随机数 |
| ROUND(x, y) | 求参数x的四舍五入值,保留y位小数 |
| ABS(num) | 绝对值 |
| BIN (decimal number) | 十进制转二进制 |
| FORMAT (number,decimal _places ) | 保留小数位数 |
| CONV( number2,from_ base,to_ base) | 进制转换 |
| HEX (DecimalNumber) | 转十六进制 |
| LEAST (number , number2…) | 求最小值 |
代码实例
-- 数学函数
-- ABS(num) 绝对值
SELECT ABS(-10) FROM DUAL #10
-- BIN (decimal_ number ) 十进制转二进制
SELECT BIN(20) FROM DUAL #10100
-- CEILING (number2 ) 向上取整,得到比num2大的最小整数
SELECT CEILING(1.3) FROM DUAL #2
-- CONV( number2,from_ base,to_ bas) 进制转换
#把12从10进制转成8进制
SELECT CONV(12,10,8) FROM DUAL #14
-- FLOOR (number2 ) 向下取整,得到比num2小的最大整数
SELECT FLOOR(-1.2) FROM DUAL #-2
-- FORMAT (number,decimal_ places ) 保留小数位数(四舍五入)
SELECT FORMAT(12.3456,2) FROM DUAL #把12.3456保留两位小数 12.34
-- HEX (DecimalNumber ) 转十六进制
SELECT HEX(22) FROM DUAL #16
-- LEAST (number,number2 [..]) 求最小值
SELECT LEAST(2,5,1,6) FROM DUAL #1
-- MOD (numerator ,denominator ) 求余
#10对3取余,得到1
SELECT MOD(10,3) FROM DUAL
-- RAND( [seed] ) RAND([seed]) 其范围为0≤v≤1.0
SELECT RAND() FROM DUAL #随机生成0-1之间的小数,再次运行会改变
SELECT RAND(10) FROM DUAL #放了种子之后生成随机数之后再运行不会改变,要重新切换种子
时间函数
常用函数:
| 函数 | 功能 |
|---|---|
| CURDATE() | 返回当前日期 |
| CURRENT_DATE ( ) | 当前日期 |
| CURRENT_TIME ( ) | 当前时间 |
| DATE(datetime) | 返回datetime的日期部分 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| YEAR(date) | 获取指定date的年份 |
| MONTH(date) | 获取指定date的月份 |
| DAY(date) | 获取指定date的日期 |
| DATE_ADD(date, INTERVAL expr type) | 返回一个日期/时间值加上一个时间间隔expr后的时间值 |
| DATE_SUB(date,INTERVAL expr type) | 在date上减去一个时间 |
| DATEDIFF(date1, date2) | 返回起始时间date1和结束时间date2之间的天数 |
| TIMEDIFF(date1,date2) | 两个时间差(多少小时多少分钟多少秒) |
上面函数的细节说明:
-
DATE ADD()中的interval 后面可以是 year minute second day等
-
DATE SUB()中的interval 后面可以是 year minute second hour day等
-
DATEDIFF(date1,date2) 得到的是天数,而且是date1-date2 的天数,因此可以取负数
-
这四个函数的日期类型可以是date, datetime或者timestamp
代码实例
-- 日期时间相关函数
-- CURRENT_DATE ( )当前日期
SELECT CURRENT_DATE FROM DUAL #2023-02-04
-- CURRENT_TIME (当前时间
SELECT CURRENT_TIME FROM DUAL #12:03:19
-- CURRENT_TIMESTAMP()当前时间戳
SELECT CURRENT_TIMESTAMP FROM DUAL #2023-02-04 12:03:57
-- DATE(datetime)返回datetime的日期部分
SELECT DATE(CURRENT_TIMESTAMP) FROM DUAL #2023-02-04
-- 在date2加上日期或者时间
#在当前日期加上了10天
SELECT DATE_ADD(CURRENT_DATE,INTERVAL 10 DAY) FROM DUAL #2023-02-14
-- 在date2减去日期或者时间
#在当前时间减去10分钟
SELECT DATE_SUB(CURRENT_TIME,INTERVAL 10 MINUTE) FROM DUAL #12:02:45
-- DATEDIFF(date1,date2)两个日期相差的天数
#是date1减去date2得到结果
SELECT DATEDIFF(CURRENT_DATE,DATE_ADD(CURRENT_DATE,INTERVAL 10 DAY)) FROM DUAL #-10
-- 两个时间差,精确到时分秒
SELECT TIMEDIFF(CURRENT_TIME,DATE_SUB(CURRENT_TIME,INTERVAL 10 MINUTE)) FROM DUAL #00:10:00
-- now() 当前时间
SELECT NOW() FROM DUAL #2023-02-04 12:18:11
-- YEAR MONTH DATE(DATETIME) 获取年月日
#获取NOW()的月份
SELECT MONTH (NOW()) FROM DUAL
-- 如果你能活80岁,求出你还能活多少天. [练习]
#先求出活到80岁是什么日期
SELECT DATE_ADD('1999-8-8',INTERVAL 80 YEAR) FROM DUAL
#再用80岁的日期减去现在的日期就是还能活的天数
SELECT DATEDIFF(DATE_ADD('1999-8-8',INTERVAL 80 YEAR),NOW()) FROM DUAL #20639
-- unix_timestamp() : 返回的是1970-1-1到现在的秒数
SELECT UNIX_TIMESTAMP() FROM DUAL; #1675524073
-- FROM_UNIXTIME() :可以把一个 秒数[时间戳],转换成指定格式的日期
#细节:指定格式为 %Y-%m-%d %H:%m:%s ,这里就是年月日时分秒的格式
#意义:在开发中,可以存放一个整数,然后表示时间,通过它来转换
SELECT FROM_UNIXTIME(1675524073) FROM DUAL #2023-02-04 23:21:13
加密和系统函数
常用函数
| 函数 | 功能 |
|---|---|
| USER() | 查询用户 |
| DATABASE() | 查询当前数据库名称 |
| MD5(str) | 为字符串算出一个MD5,32位的字符串,可用于密码加密 |
| PASSWORD(str)select * from mysql.user | 从原文密码str计算并返回密码字符串,通常用于对mysqI数据库的用户密码加密 |
代码实例
-- 加密函数
-- USER()查询用户
SELECT USER() FROM DUAL #root@localhost
-- DATABASE () 当前数据库名称
SELECT DATABASE() FROM DUAL #yjm_db02
-- MD5 (str)为字符串算出一个MD5 32的字符串,(用户密码)加密
SELECT MD5('123456') FROM DUAL #e10adc3949ba59abbe56e057f20f883e
SELECT LENGTH(MD5('123456')) FROM DUAL # MD5之后的密码长度为32位
-- PASSWORD (str) 加密函数
#细节:MYSql默认使用PASSWORD (str) 函数对数据库用户进行加密
SELECT PASSWORD('123456') FROM DUAL #*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
-- select * from mysql.user \G从原文密码str计算并返回密码字符串,
-- 通常用于对mysql数据用户密码进行加密
SELECT * FROM mysql.user #*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
流程函数
常用函数:
| 函数 | 功能 |
|---|---|
| IF(value, t, f) | 如果value为true,则返回t,否则返回f |
| IFNULL(value1, value2) | 如果value1不为空,返回value1,否则返回value2 |
| CASE WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END | 如果val1为true,返回res1,… 否则返回default默认值 |
| CASE [ expr ] WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END | 如果expr的值等于val1,返回res1,… 否则返回default默认值 |
代码实例
-- IF(expr1,expr2,expr3)如果expr1为True ,则返回expr2否则返回expr3
SELECT IF(NULL,'真','假') FROM DUAL #假
-- IFNULL(expr1,expr2)如果expr1不为空NULL,则返回expr1,否则返回expr2
SELECT IFNULL('有数据','没数据') FROM DUAL #有数据
SELECT IFNULL(NULL,'没数据') FROM DUAL #没数据
-- SELECT CASE WHEN expr1 THEN expr2 WHEN expr3 THEN expr4 ELSE expr5 END; [类似多重分支.]
-- 如果expr1为TRUE,则返回expr2,如果expr3 为t,返回expr4,否则返回expr5
SELECT `name`,CASE
WHEN `chinese`>80 THEN '学霸'
WHEN `english`>90 THEN '学神'
ELSE '不太行' END AS '称号' FROM student
查询结果如下
name 称号
关羽 学霸
宋江 学霸
张飞 学神
欧阳锋 不太行
赵云 学霸
韩信 不太行
韩顺平 学霸
黄蓉 不太行
查询加强
where子句和like操作符
代码实例
-- 使用where子句
-- ?如何查找1992.1.1后入职的员工
#细节:查询的条件格式要和内容匹配
SELECT * FROM emp WHERE hiredate > '1992-01-01'
-- 如何使用like操作符
-- %:表示0到多个字符: 表示单个字符
-- ?如何显示首字符为S的员工姓名和工资
SELECT ename,sal FROM emp WHERE ename LIKE 'S%'
-- ?如何显示第三个字符为大写O的所有员工的姓名和工资
SELECT ename,sal FROM emp WHERE ename LIKE '__O%'
-- 如何显示没有上级的雇员的情况
#细节:判断是否为空要使用IS
SELECT * FROM emp WHERE mgr IS NULL
-- 查询表结构selectinc.sql
#可以查询到字段和类型还有其他等等
DESC emp
排序查询
语法:
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1, 字段2 排序方式2;
?如何按照工资的从低到高的顺序,显示雇员的信息
?按照部门号升序,雇员的工资降序排列,显示雇员信息
-- 使用order by子句
-- ?如何按照工资的从低到高的顺序,显示雇员的信息
#默认升序 可以不写ASC
SELECT * FROM emp ORDER BY sal ASC
-- ?按照部门号升序而雇员的工资降序排列,显示雇员信息
#先排部门 然后再在部门内部排工资
#细节:ORDER BY后面接条件,多个条件直接用逗号隔开即可
SELECT * FROM emp ORDER BY deptno ASC , sal DESC
注意事项
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
分页查询
语法:
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数;
例子:
-- 查询第一页数据,展示10条
SELECT * FROM employee LIMIT 0, 10;
-- 查询第二页
SELECT * FROM employee LIMIT 10, 10;
代码实例
-- 按雇员的empno号降序取出,每页 显示5条记录。请分别显示第3页,第5页对应的sql语句
#细节:公式:LIMIT 每页要显示的记录数*(第几页-1), 每页要显示的记录数
#第3页
SELECT * FROM emp ORDER BY empno DESC LIMIT 10,5
#第5页
SELECT * FROM emp ORDER BY empno DESC LIMIT 20,5
注意事项
- 起始索引从0开始,起始索引 = (查询页码 - 1) * 每页显示记录数
- 分页查询是数据库的方言,不同数据库有不同实现,MySQL是LIMIT
- 如果查询的是第一页数据,起始索引可以省略,直接简写 LIMIT 10
DQL执行顺序
FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
分组增强
代码实例
使用分组函数和分组子句group by
(1)显示每种岗位的雇员总数、平均工资。
(2)显示雇员总数,以及获得补助的雇员数。
(3)显示管理者的总人数。
(4)显示雇员工资的最大差额。
SELECT COUNT(*) ,job, AVG(sal) FROM emp GROUP BY job
-- (2)显示雇员总数,以及获得补助的雇员数。
# 细节:count函数默认不统计NULL,所以NULL自动被剔除
SELECT COUNT(comm) FROM emp #3
-- (3)显示管理者的总人数。
SELECT COUNT( DISTINCT mgr) FROM emp #5
-- (4)显示雇员工资的最大差额。
SELECT MAX(sal)-MIN(sal) FROM emp #4200.00
多子句查询
DQL执行顺序
FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
代码实例
-- 应用案例:请统计各个部门group by 的平均工资avg,
-- 并且是大于1000的having, 并且按照平均工资从高到低排序,order by
-- 取出前两行记录limit 0,2
#细节:limit公式:LIMIT 每页要显示的记录数*(第几页-1), 每页要显示的记录数
SELECT * FROM emp
SELECT deptno,AVG(sal) AS avg_sal FROM emp
GROUP BY deptno
HAVING avg_sal >1000
ORDER BY avg_sal DESC
LIMIT 0,2
多表查询
多表关系
- 一对多(多对一)
- 多对多
- 一对一
一对多
案例:部门与员工
关系:一个部门对应多个员工,一个员工对应一个部门
实现:在多的一方建立外键,指向一的一方的主键
多对多
案例:学生与课程
关系:一个学生可以选多门课程,一门课程也可以供多个学生选修
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
一对一
案例:用户与用户详情
关系:一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率
实现:在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
查询
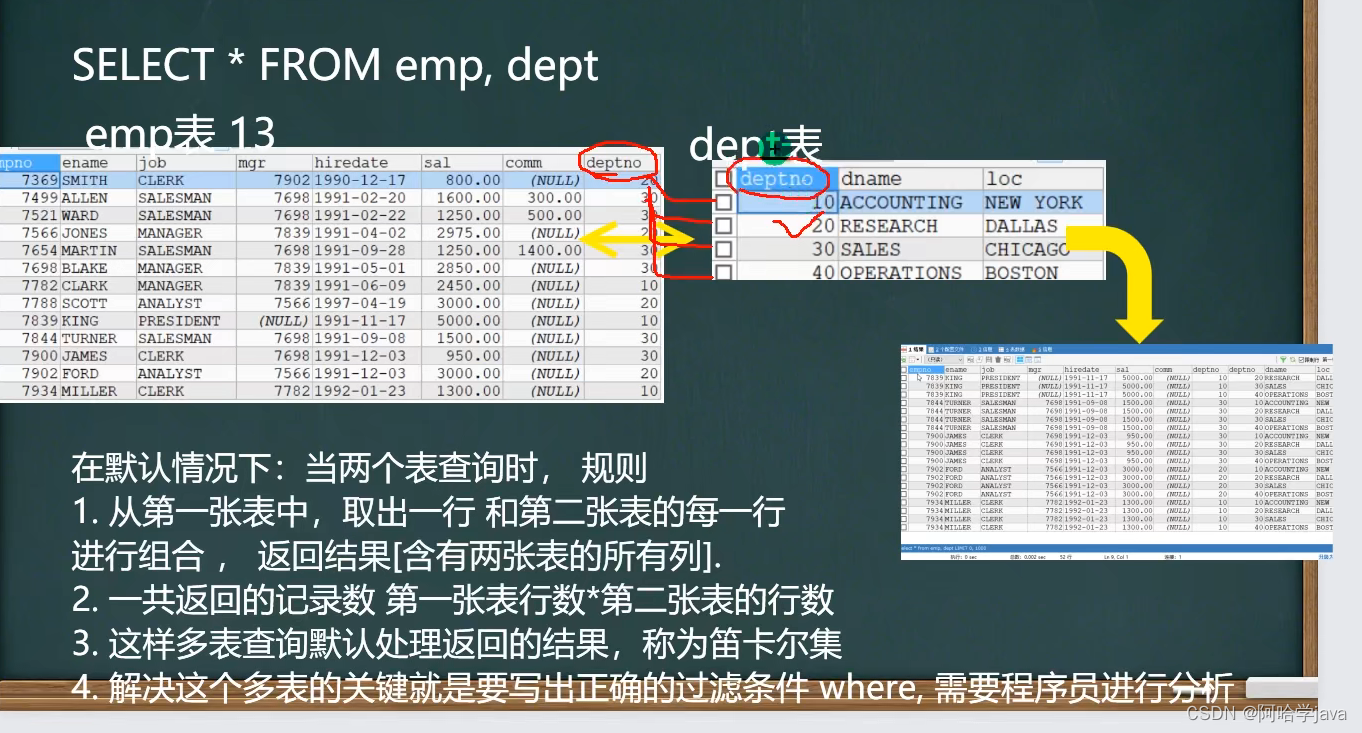
合并查询(笛卡尔积,会展示所有组合结果):
select * from employee, dept;
笛卡尔积:两个集合A集合和B集合的所有组合情况(在多表查询时,需要消除无效的笛卡尔积)
消除无效笛卡尔积:
select * from employee, dept where employee.dept = dept.id;
代码实例
-- 多表查询练习many tab.sql
-- ?显示雇员名,雇员工资及所在部门的名字[笛卡尔集]
#查询出来的数据一共52行,因为emp表和dept表的每一行数据都进行了组合
#因此要通过筛选条件去筛选
SELECT * FROM emp,dept
SELECT * FROM emp
SELECT * FROM dept
SELECT * FROM salgrade
-- 老韩小技巧:多表查询的条件不能少于表的个数-1,否则会出现笛卡尔集
-- ?如何显示部门号为10的部门名、员工名和工资
#细节:若果使用having,having要在where后面
SELECT ename,emp.`deptno`,dname,sal FROM emp,dept
WHERE emp.`deptno`=dept.`deptno`AND emp.`deptno`=10
-- ?显示各个员工的姓名,工资,及其工资的级别
# 过滤条件要想清楚
# 工资级别有规定范围,那就筛选员工表的工资落到的范围之内即可
SELECT ename,sal,grade FROM emp,salgrade
WHERE sal BETWEEN losal AND hisal
内连接
内连接查询
内连接查询的是两张表交集的部分
隐式内连接:
SELECT 字段列表 FROM 表1, 表2 WHERE 条件 ...;
显式内连接:
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ...;
显式性能比隐式高
代码实例
-- 内连接
-- 内连接是指在同一张表的连接查询[将同一张表看做两张表]。self.sql
-- 思考题:显示公司员工和他的上级的名字
SELECT * FROM emp worker,emp boss #返回了两个合并的表 13*13
# 给表起表名之后,直接可以用表的别名调用字段
SELECT worker.ename AS '员工',boss.ename AS '领导' FROM emp worker,emp boss
#分析过滤条件 就是别名员工表的领导编号 等于 别名领导表的编号
SELECT worker.ename AS '员工',
boss.ename AS '领导'
FROM emp worker,emp boss
WHERE worker.mgr = boss.empno
-- 内连接的特点
-- 1.把同一张表当做两张表使用
-- 2.需要给表取别名,直接把别名写在表名后面即可不用 as,如上 FROM emp worker,emp boss
-- 3.列名不明确,可以指定列的别名
子查询
SQL语句中嵌套SELECT语句,称谓嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2);
子查询外部的语句可以是 INSERT / UPDATE / DELETE / SELECT 的任何一个
根据子查询结果可以分为:
- 标量子查询(子查询结果为单个值)
- 列子查询(子查询结果为一列)
- 行子查询(子查询结果为一行)
- 表子查询(子查询结果为多行多列)
根据子查询位置可分为:
- WHERE 之后
- FROM 之后
- SELECT 之后
表子查询
(子查询结果为多行多列)
代码实例
-- mysql表子查询
-- 什么是子查询subquery.sql
-- 子查询是指嵌入在其它sq|语句中的select语句,也叫嵌套查询
-- 单行子查询
-- 单行子查询是指只返回一行数据的子查询语句
-- 请思考:如何显示与SMITH同一部门的所有员工?
-- 思路:先查到smith的所在部门,通过该部门号查询该部门员工
SELECT deptno FROM emp WHERE ename = 'SMITH'
SELECT ename FROM emp
WHERE deptno =(SELECT deptno FROM emp WHERE ename = 'SMITH')
行子查询
(子查询结果为一行)
代码实例
-- 多行子查询
-- 多行子查询指返回多行数据的子查询使用关键字in
-- 课堂练习:如何查询和部门10的工作相同的雇员的
-- 名字、岗位、工资、部门号,但是不含10号部门的员工.
#思路 : 1.先查出10部门的工作
# 2.接着使用where子句通过in确定查询的条件
# 细节:要进行去重,不然会有重复的岗位出现
SELECT DISTINCT job FROM emp WHERE deptno = 10 #查询10号部门的岗位
SELECT ename,job,sal,deptno FROM emp
WHERE job IN(SELECT DISTINCT job FROM emp WHERE deptno = 10) #直接套上面的条件
AND deptno <> 10 #不包含10号部门
子查询当做临时表使用
代码实例
- 子查询当做临时表使用练习题subquery.sql
-- 查询ecshop中各个类别中,价格最高的商品.
-- 老韩提示,可以将子查询当做一张临时表使用
SELECT goods_id, cat_id,goods_name,shop_price FROM ecs_goods
#查询最高的商品价格,把商品价格和源表对照获取其中商品信息
SELECT goods_id, cat_id,goods_name,MAX(shop_price)
FROM ecs_goods GROUP BY cat_id
#细节:有个错误就是以为上面这样子查询就得到结果
# 但是货物的名字和货物id是对照不上的
# 原因是goods_name没有进行筛选,返回的是表中cat_id对应最先出现的数据
#所以要进行条件匹配,匹配到每一个要查询的字段
-- 查询最高价格和cat_id
SELECT cat_id,MAX(shop_price)
FROM ecs_goods GROUP BY cat_id
#思路:
#就是把要查询的两个东西查出来再和原表匹配即可
#在获得最高价格的的查询结果当做临时表,然后作为被查询的表的之一
#同时查询两个表就可以获取两个表的信息
#通过where子句进行条件判断匹配原表数据
#temp.cat_id = ecs_goods.cat_id ,查到临时表的id和原表的id进行匹配
#max_price=ecs_goods.shop_price ,临时表的最高价格和原表的价格进行匹配
#细节:select 的字段要清晰写明是哪个表的!
SELECT goods_id, ecs_goods.cat_id,goods_name,max_price FROM (
SELECT cat_id,MAX(shop_price) AS max_price
FROM ecs_goods GROUP BY cat_id) temp,ecs_goods
WHERE temp.cat_id = ecs_goods.cat_id AND max_price=ecs_goods.shop_price
列子查询
返回的结果是一列(可以是多行)。
常用操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围内,多选一 |
| NOT IN | 不在指定的集合范围内 |
| ANY | 子查询返回列表中,有任意一个满足即可 |
| SOME | 与ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查询返回列表的所有值都必须满足 |
代码实例1
-- 请思考:如何显示工资比部门30的其中一个员工的工资高的员工的姓名、工资和部门号
#思路:这里要求使用any
#把30部门的工资查询出来然后使用any再和其他部门比较即可
SELECT sal FROM emp WHERE deptno=30 #查询到10部门的所有工资
SELECT ename, sal, deptno FROM emp
WHERE sal>ANY(SELECT sal FROM emp WHERE deptno=30)
AND deptno!=30
#另一种思路直接比较30部门工资最低的即可
SELECT ename, sal, deptno FROM emp
WHERE sal>(SELECT MIN(sal) FROM emp WHERE deptno=30)
AND deptno!=30
-- 请思考:显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
#思路:要求使用all
SELECT ename, sal, deptno FROM emp
WHERE sal>ALL(SELECT sal FROM emp WHERE deptno=30)
AND deptno!=30
#使用MAx
SELECT ename, sal, deptno FROM emp
WHERE sal>(SELECT MAX(sal) FROM emp WHERE deptno=30)
AND deptno!=30
代码实例2
-- 多列子查询
-- 练习1:请思考如何查询与ALLEN的部门和岗位完全相同的所有雇员(并且不含smith本人)
# 思路:
#1.先查到ALLEN在哪个部门,然后通过它的部门和岗位进行查询比较
# 查询他的部门号
# 细节:字符串数据记得加双引号
SELECT * FROM emp WHERE `ename` = 'ALLEN'
#查询他的岗位和部门
SELECT deptno,job FROM emp WHERE `ename` = 'ALLEN'
#通过多列进行比较获取和他同部门和同岗位的员工
#把上面的查询当做子查询来使用,并且使用多列子查询的语法进行匹配
SELECT * FROM emp WHERE (deptno,job) =
(SELECT deptno,job FROM emp WHERE `ename` = 'ALLEN')
AND `ename` != 'ALLEN'
#细节:多个字段要用括号括起来
-- (字段1, 字段2 ...) = (select 字段1,字段2 from 。
-- 练习2:请查询和宋江数学,英语,语文完全相同的学生
SELECT * FROM student WHERE `name`='宋江'
#查询三科的字段对应的数据
SELECT chinese,english,math FROM student WHERE `name`='宋江'
#使用上面的字段数据作为子查询条件
#细节:被查询的子查询条件不要忘记括号
SELECT * FROM student WHERE (chinese,english,math)=(
SELECT chinese,english,math FROM student WHERE `name`='宋江')
子查询综合练习
练习1
-- 在from子句中使用子查询subquery03.sql
-- 请思考:查找每个部门工资高于本部门平均工资的人的资料
-- 这里要用到数据查询的小技巧,把一个子查询当作一个临时表使用
#思路:
# 1.先查询部门的平均工资,当然也要进行分组
# 2.使用where子句筛选本部门工资大于平均工资的
# 3.进行比较是要对应条件
SELECT deptno,AVG(sal) FROM emp GROUP BY deptno
#以上作为子查询作为临时表
#细节:字段和字段不能进行比较
#最蠢的办法把结果查出来
SELECT * FROM emp temp WHERE (sal >
(SELECT AVG(sal) FROM emp WHERE deptno=10 GROUP BY deptno)
AND temp.deptno=10 )OR
(sal >
(SELECT AVG(sal) FROM emp WHERE deptno=20 GROUP BY deptno)
AND temp.deptno=20 )OR
(sal >
(SELECT AVG(sal) FROM emp WHERE deptno=30 GROUP BY deptno)
AND temp.deptno=30 )
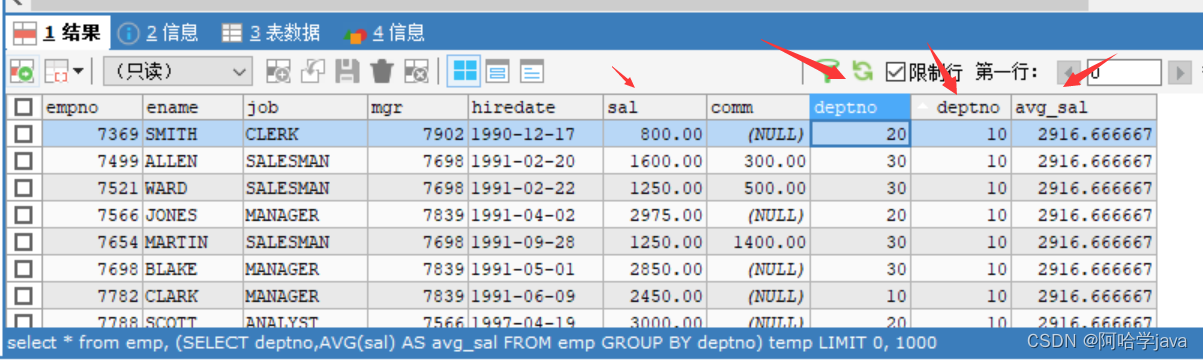
#最好的办法是使用多表查询,把表和临时表进行组合
SELECT deptno,AVG(sal) AS avg_sal FROM emp GROUP BY deptno #作为临时表
#组合起来,之后进行判断
#条件就是部门号相等,工资少于平均工资
SELECT * FROM emp,
(SELECT deptno,AVG(sal) AS avg_sal FROM emp GROUP BY deptno) temp
WHERE emp.`deptno`=temp.deptno AND emp.`sal`>temp.avg_sal
#细节1:把子查询结果作为临时表进行多表查询可以组合成一个新表
#细节2:因为即使字段名相同并不会覆盖,而是作为新列存在
#细节3:所以把字段的数据进行条件判断就可以获取需要查询结果
练习2
-- 请思考:查找每个部门工资最高的人的详细资料
#思路:
#分组查询每一组员工
#先查出每一组最高工资的金额
#然后作为临时表去匹配部门员工
SELECT MAX(sal) FROM emp GROUP BY deptno #查出每部门最高工资
#子查询的结果作为临时表匹配
#在源表emp中用员工的工资匹配到最高工资的就算查到
SELECT * FROM emp ,(SELECT MAX(sal) AS max_sal FROM emp GROUP BY deptno) temp
WHERE emp.`sal`=temp.max_sal
练习3
-- 查询每个部门的信息(包括:部门名;编号,地址)和人员数量,我们一起完成。
#思路:
#1.查询每一个部门的人数
#2.查出来的人数使用部门号去匹配部门表即可加入
SELECT deptno ,COUNT(*) FROM emp GROUP BY deptno #查出每一个部门的人数
#把每一个部门的人数和编号进行匹配
#细节1:表.*表示把该表的全部字段显示出来,可以简化sql语句
#细节2:在多表查询中,当多个表的列名不重复,才能直接写列名,不然就要表名.列名或者先起个别名
SELECT dept.*, num FROM dept,
(SELECT deptno AS temp_no ,COUNT(*) AS num FROM emp GROUP BY deptno) temp
WHERE dept.`deptno`=temp.temp_no
练习4
-- ●自我复制数据(蠕虫复制)
-- 有时,为了对某个sql语句进行效率测试,我们需要海量数据时,可以使用此法为表创建
-- 海量数据。coyptab.sql
-- 思路
-- 1.创建新表,不过建议列名对应旧表的表名
DESC emp
CREATE TABLE tab_test (
ename VARCHAR(20),
job VARCHAR(9),
sal DECIMAL(7,2))
-- 2.把旧表的查询结果作为value值insert到新表
#细节:插入一个表的数据不用value关键字
INSERT INTO tab_test (ename,job,sal)
SELECT ename,job,sal FROM emp
#或者直接去掉被插入表的列名也可以
INSERT INTO tab_test
SELECT ename,job,sal FROM emp
-- 3.之后把新表查询结果作为插入值,重复多次
INSERT INTO tab_test SELECT * FROM tab_test
练习5
-- 如何删除一个表的重复数据
-- 思路:
-- 1.先把该表进行distinc关键字去重
SELECT DISTINCT * FROM tab_test #去重后只有13行,不去重前有1000行
-- 2.把去重后的表复制给一个临时表
#细节1:可以通过like关键字直接复制创建一个新表
CREATE TABLE temp_tab LIKE tab_test
DESC temp_tab
INSERT INTO temp_tab SELECT DISTINCT * FROM tab_test
SELECT * FROM temp_tab #临时表数据复制完后只有13行 正确
-- 3.把原表的数据清除后,再把临时表数据复制回去就可
-- 方法1 删除数据:DELETE FROM 表名 [ WHERE 条件 ];
DELETE FROM tab_test #删除数据
-- 方法2 删除表后重新创建
TRUNCATE TABLE tab_test #删除表后重新创建表
DESC tab_test
INSERT INTO tab_test SELECT * FROM temp_tab #复制临时表数据
-- 4.删除临时表
DROP TABLE temp_tab
-- 5.去重成功
SELECT * FROM tab_test #13行数据
合并查询
合并查询介绍
有时在实际应用中,为了合并多个select语句的结果,可以使用集合操作符号union , union all
1. union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会取消重复行。
select ename,sal,job from emp where sal> 2500 union
select ename,sal,job from emp where job= 'MANAGER'
2. union
该操作赋与union all相似,但是会自动去掉结果集中重复行
select ename,saljob from emp where sal> 2500
union all select ename,saljob from emp where
job= 'manager';
代码实例
-- 合并查询
-- union all 同时查询两个表,数据不去重
SELECT * FROM emp WHERE sal>2500#5行
UNION ALL #合并之后9行
SELECT * FROM emp WHERE deptno = 20 # 4行
-- union 合并查询结果,数据去重
SELECT * FROM emp WHERE sal>2500#5行
UNION #合并之后6行
SELECT * FROM emp WHERE deptno = 20 # 4行
外连接
3.使用左连接(显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号,成绩显示为空)
select .. from 表1 left join 表2 on 条件 [表1:就是左表 表2:就是右表]
4.使用右外连接(显示所有成绩,如果没有名字四配,显示空)
select .. from 表1 right join 表2 on 条件[表1:就是左表 表2:就是右表]
代码实例
-- mysql表外连接
-- ●课堂练习
-- 列出部门名称和这些部门的员工信息(名字和工作),同时列出那些没有员工的部门。
-- 1.使用左外连接实现
#左边的表没有匹配上的就显示
SELECT ename,job,dname
FROM dept LEFT JOIN emp
ON emp.`deptno`=dept.`deptno`
-- 2.使用右外连接实现
#右边的表没有匹配的数据也可显示
SELECT ename,job,dname
FROM emp RIGHT JOIN dept
ON emp.`deptno`=dept.`deptno`
MySQL约束
主键约束(primary key)
基本使用
字段名 字段类型 primary key
用于唯一的标示表行的数据,当定义主键约束后,该列不能重复
细节说明
- primary key不能重复而且不能为null.
- 一张表最多只能有一个主键,但可以是复合主键
- 主键的指定方式有两种
- 直接在字段名后指定
字段名 primakry key - 在表定义最后写
primary key(列名)
- 使用desc表名,可以看到primary key的情况
- 注:在实际开发中,每个表往往都会设计一个主键
代码实例
-- primary key(主键)-细节说明
-- 1.primary key不能重复而且不能为null.
-- 2.一张表最多只能有一个主键,但可以是复合主键
-- 3.主键的指定方式有两种
-- ●直接在字段名后指定:字段名primakry key
#把name列设置为主键
CREATE TABLE t5 (`name` VARCHAR(32) PRIMARY KEY ,age INT)
INSERT INTO t5 VALUE ('jack',18)
#name相同就会报错,因为主键表示只有一个
INSERT INTO t5 VALUE ('jack',19) #Duplicate entry 'jack' for key 'PRIMARY'
#设为主键的列也不能为空
INSERT INTO t5 VALUE (NULL,18) #Column 'name' cannot be null
-- ●在表定义最后写primary key(列名);
#把id和name设置为复合主键
CREATE TABLE t6 (id INT, `name` VARCHAR(32),age INT ,PRIMARY KEY(id,`name`))
# 细节:当设置成为复合主键的多个字段,满足同时重复才报错
INSERT INTO t6 (id,`name`, age) VALUE (1,'tom',18)#添加第一行数据
INSERT INTO t6 (id,`name`, age) VALUE (2,'tom',18) #添加第二行数据 即使名字重复也成功
INSERT INTO t6 (id,`name`, age) VALUE (2,NULL,18)#主键不能为空,一个都不行
INSERT INTO t6 (id,`name`, age) VALUE (2,'tom',18)#同时重复,报错Duplicate entry '2-tom' for key 'PRIMARY'
DESC t6
-- 4.使用desc表名,可以看到primary key的情况.
-- 5.老师提醒:在实际开发中,每个表往往都会设计一个主键.
唯一约束(unique)
- not null(非空)
如果在列上定义了not null,那么当插入数据时,必须为列提供数据。
字段名 字段类型 not null - unique(唯一 )
当定义了唯一约束后,该列值是不能重复的。
字段名 字段类型 unique - unique 细节
- 如果没有指定not null,则unique字段可以有多个null
- 一张表可以有多个unique字段
代码实例
-- unique 表示唯一,该列值是不能重复的
#把id设置成unique
CREATE TABLE t7 (id INT UNIQUE, `name` VARCHAR(32),age INT )
#添加数据
INSERT INTO t7 (id,`name`, age) VALUE (1,'tom',18)
#id重复就报错
INSERT INTO t7 (id,`name`, age) VALUE (1,'jack',18)#Duplicate entry '1' for key 'id'
-- 细节1:若果没有指定not null ,unique字段可以有多个null
-- 细节2:unique not null等价为 primary key 不可重复并且不能为空
INSERT INTO t7 (id,`name`, age) VALUE (NULL,'tom',18) #给id添加null成功
-- 细节3:一张表可以有多个unique字段
CREATE TABLE t8 (id INT UNIQUE, `name` VARCHAR(32) UNIQUE ,age INT )
DESC t8 #在key字段显示有两个uni
外键约束(foreign key)
foreign key(外键)
用于定义主表和从表之间的关系:外键约束要定义在从表上,主表则必须具有主键约束或是unique约束,当定义外键约束后,要求外键列数据必须在主表的主键列存在或是为null (学生/班级图示)
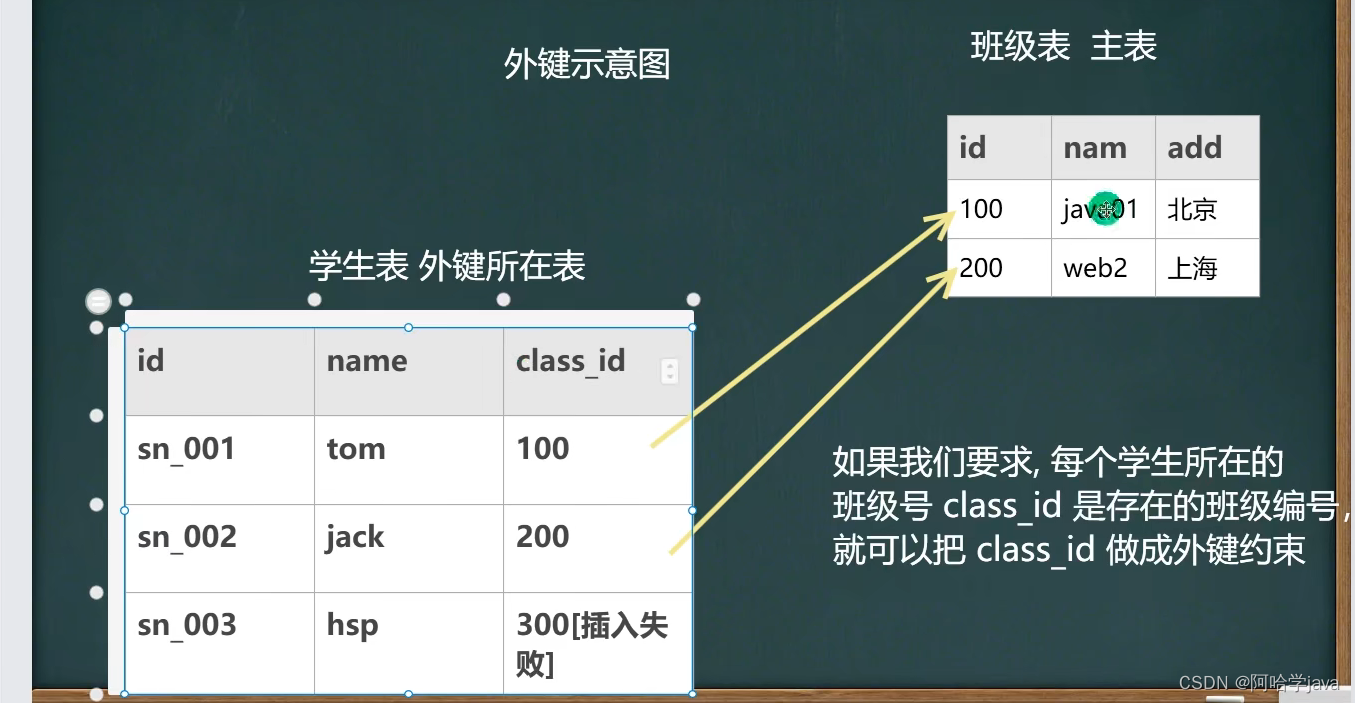
细节说明
-
外键指向的表的字段, 要求是primary key或者是unique
-
表的类型是innodb, 这样的表才支持外键 (5条消息) Mysql中查看表的类型InnoDB_荒–的博客-CSDN博客_表类型 innodb
-
外键字段的类型要和主键字段的类型一致(长度可以不同)
-
外键字段的值,必须在主键字段中出现过,或者为null [前提是外键字段允许为nul]
-
一旦建立主外键的关系,数据不能随意删除,需要先删除主表对应的所有从表的外键约束的字段,才可以删除主表字段
代码实例
-- 外键演示
-- 创建主表 my_class
CREATE TABLE my_class (
id INT PRIMARY KEY,#班级编号
`name` VARCHAR(32) NOT NULL DEFAULT '');
-- 创建从表
CREATE TABLE my_stu (
id INT PRIMARY KEY, #学生编号
`name` VARCHAR(32) NOT NULL DEFAULT '',
class_id INT, #对应的班级编号
#指定外键关系
#细节:1.外键指向的表的字段,要求是primary key或者是unique
FOREIGN KEY(class_id) REFERENCES my_class(id));
-- 测试数据
#给班级表 主表 添加数据
INSERT INTO my_class VALUE(100,'java'),(200,'web')
#给学生表 从表 添加数据
INSERT INTO my_stu VALUE(1,'jack',100),(2,'tom',200)
#当从表想添加不存在的班级id 就会失败
# 300班在主表是不存在的,所以从表受到主表的约束,这就叫外键约束
INSERT INTO my_stu VALUE(3,'jack',300)
-- 2.表的类型是innodb, 这样的表才支持外键
#MyISAM引擎不支持外键,InnoDB支持外键
-- 3.外键字段的类型要和主键字段的类型一致(长度可以不同)
#都是int 型
-- 4.外键字段的值,必须在主键字段中出现过,或者为null [前提是外键字段允许为nul]
INSERT INTO my_stu VALUE(3,'aha',NULL) #成功,因为外键字段创建的时候允许为空
-- 5.一旦建立主外键的关系,数据不能随意删除
#需要先删除主表对应的所有从表的外键约束的字段,才可以删除主表字段
check
- check用于强制行数据必须满足的条件。
oracle、sql server 和Mysql8.0.16均支持check ,但是mysql 5.7 目前还不支持check ,只做语法校验,但不会生效。 - 基本语法:
列名类型 check (check条件) user表 - 在mysql中实现check的功能,一般是在程序中控制,或者通过触发器完成。
代码实例
-- 基本语法:列名类型 check (check条件)
CREATE TABLE t9 (
`name` VARCHAR(32),
sex VARCHAR(6) CHECK (sex IN('man','woman')));#check约束
INSERT INTO t9 VALUE('阿哈','oo')#更新数据依然成功了,因为我的版本是5.7
商店售货系统表设计案例
代码实例
-- 商店售货系统表设计案例[先练再评10min]
-- 现有一个商店的数据库shop_db,记录客户及其购物情况,由下面三个表组成:
-- 商品goods ( 商品号goods_ id,商品名goods_ name,单价unitprice,商品类别category,供应商provider);
-- 客户customer (客户号customer_ id,姓 名name,住址address,电邮email性别sex,身份证card_ ld);
-- 购买purchase (购买订单号order_ id, 客户号customer_ id,商 品号goods_ id,购买数量nums);
-- 1建表,在定义中要求声明[进行合理设计]:
-- (1)每个表的主外键;
-- (2)客户的姓名不能为空值;
-- (3)电邮不能够重复;
-- (4)客户的性别[男|女] check枚举..
-- (5)单价unitprice在1.0 - 9999.99之间check
#创建数据库
CREATE DATABASE shop_db
-- 商品goods ( 商品号goods_id,商品名goods_name,单价unitprice,商品类别category,供应商provider);
CREATE TABLE goods (
goods_id INT PRIMARY KEY,
goods_name VARCHAR(32) NOT NULL UNIQUE,
#(5)单价unitprice在1.0 - 9999.99之间check
unitprice DOUBLE NOT NULL CHECK (unitprice >1.0 AND unitprice<9999.99) ,
category VARCHAR(32) NOT NULL DEFAULT '',
provider VARCHAR(32)NOT NULL DEFAULT ''
)
SELECT * FROM goods
-- 客户customer (客户号customer_ id,姓名name,住址address,电邮email,性别sex,身份证card_ld);
CREATE TABLE customer(
customer_id INT PRIMARY KEY,#约束主键
`names` VARCHAR(32) NOT NULL DEFAULT '',
address VARCHAR(32) ,
email VARCHAR(32) UNIQUE,
#(4)客户的性别[男|女] check,枚举..
#使用枚举就是要求只能在这些条件里面添加数据
sex ENUM('man','woman') NOT NULL,
card_id VARCHAR(32) UNIQUE
)
SELECT * FROM customer
-- 购买purchase (购买订单号order_id, 客户号customer_ id,商品号goods_id,购买数量nums);
#客户号是被客户表的id外键约束,商品号是被商品表的商品号外键约束的
#订单号也是唯一的,购买数量应该随机
CREATE TABLE purchase(
order_id INT PRIMARY KEY,#约束主键
customer_id INT ,
goods_id INT ,
nums INT,
#指定外键关系
FOREIGN KEY(customer_id) REFERENCES customer(customer_id),
FOREIGN KEY(goods_id) REFERENCES goods(goods_id)
);
DESC purchase
SELECT * FROM purchase
自增长
- 自增长基本介绍
在某张表中,存在一个id列(整数),我们希望在添加记录的时候,该列从1开始,自动的增长,怎么处理?
字段名 整型 primary key auto_ increment
- 添加自增长的字段方式
insert into xXx (字段1,字段.... values(null, '值'...)
insert into XXX (字段... values('值1'; '值'....);
insert into XXX values(null, '值1 .....)
代码实例
-- 演示自增长
-- insert into xXx (字段1,字段.... values(null, '值'...)
-- insert into XXX (字段... values('值1'; '值'....);
-- insert into XXX values(null, '值1 .....)
-- 创建表
CREATE TABLE t10(
id INT PRIMARY KEY AUTO_INCREMENT,#自增长配合主键PRIMARY KEY或者unique一起食用
`name` VARCHAR(32)
)
CREATE TABLE t11(
id INT UNIQUE AUTO_INCREMENT,#自增长配合主键PRIMARY KEY或者unique一起食用
`name` VARCHAR(32)
)
#添加数据
-- insert into xXx (字段1,字段.... values(null, '值'...)
INSERT INTO t10(id,`name`) VALUE(NULL,'aha') #1 aha
INSERT INTO t10(id,`name`) VALUE(3,'aha3') #3 aha
INSERT INTO t10 VALUE(NULL,'aha4') #4 aha
#修改自增长开始值
ALTER TABLE t11 AUTO_INCREMENT=100
INSERT INTO t11(id,`name`) VALUE(NULL,'aha100') #100 aha100
#细节1:自增长是配合主键约束和unique一起食用的,所以肯定是唯一的
#细节2:自增长字段也可以自定义数据
#细节3:自增长默认从1开始,每次自增都是找到最大值+1
#细节4:也可修改自增长开始值
自增长使用细节
- 一般来说自增长是和primary key配合使用的
- 自增长也可以单独使用[但是需要配合一个unique]
- 自增长修饰的字段为整数型的(虽然小数也可以但是非常非常少这样使用
- 自增长默认从1开始,你也可以通过如下命令修改
alter table 表名 auto_increment =新的开始值; - 如果你添加数据时,给自增长宇段(列)指定的有值,则以指定的值为准
MySQL索引
索引优化速度
-
说起提高数据库性能,索引是最物美价廉的东西。
不用加内存,不用改程序,不用调sql,查询速度就可能提高百倍干倍。
这里我们举例说明索引的好处[构建海量表8000000] -
提出问题:是不是建立一个索引就能解决所有的问题?ename 上没有建立索引会怎样?
select * from emp where ename='axJxC'
代码实例
SELECT * FROM emp WHERE ename='axJxC' #未添加索引前查询时间5.7秒
#创建索引
-- create index 索引名 on 表名(字段列名)
CREATE INDEX ename_index ON emp(ename) #创建索用了25秒
SELECT * FROM emp WHERE ename='axJxC' #创建索引后查询时间0.002秒
索引原理
-
没有索引为什么会慢?
因为要进行全表扫描。 -
使用索引为什么会快?
形成一个索引的数据结构,比如二叉树。
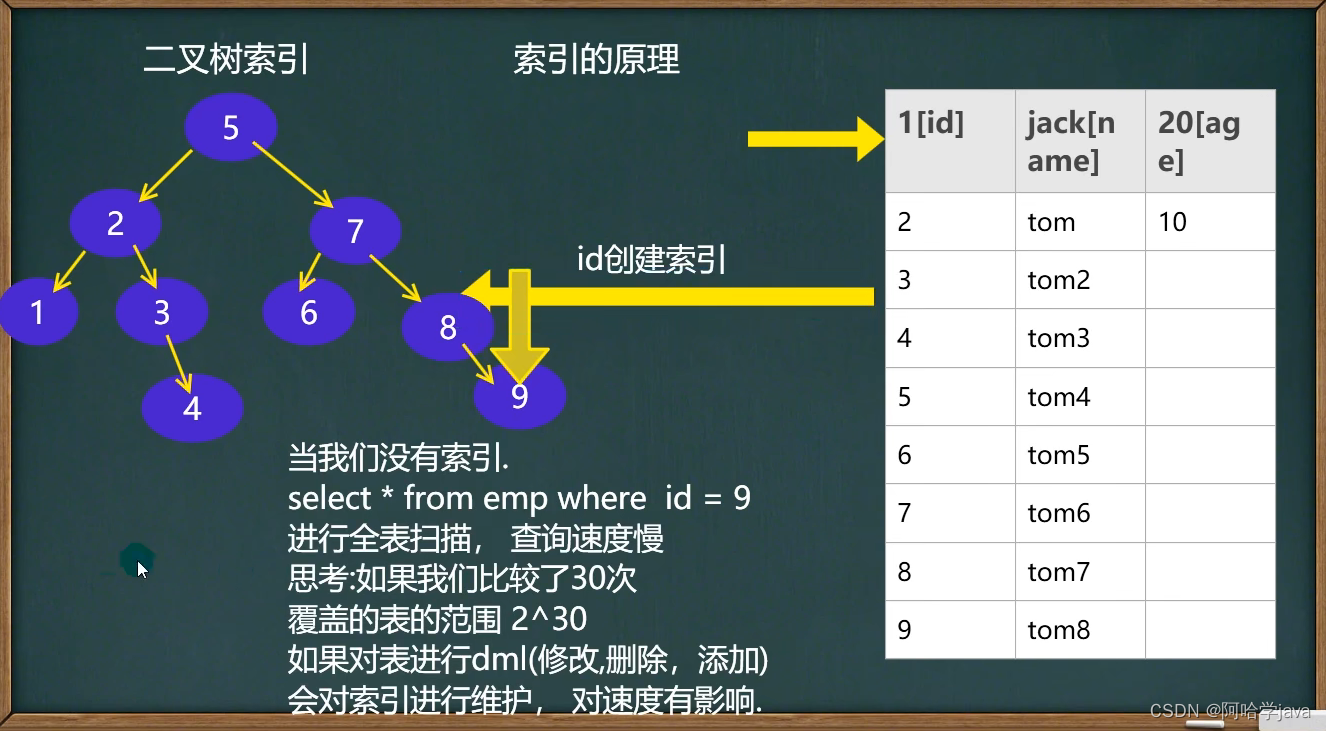
索引的代价
- 磁盘占用
- 增加dml(update delete insert)语句的效率影响。
在我们项目中, select[90%]比update,delete,insert**[10%**]操作多。
索引的类型
- 主键索引,主键自动的为主索引(类型Primary key)
- 唯一索引(UNIQUE)
- 普通索引(INDEX)
- 全文索引(FULLTEXT) [适用于MyISAM]
开发中考虑使用:全文搜索Solr和ElasticSearch (ES) - 查询索引:SHOW INDEX FROM 表名
创建索引
举个栗子
create table t1 (
id int primary key, #主键,同时也是索引,称为主键索引.
name varchar(32));
create table t2(
id int unique, #id是唯一的, 同时也是索引,称为unique索引.
nam varchar(32));
代码实例
-- 添加索引演示
-- 添加主键索引
#添加主键索引方法1:直接在创建的时候添加PRIMARY KEY
CREATE TABLE t12(
id INT PRIMARY KEY,
`name` VARCHAR(32)
)
#创建新表时没有添加主键
CREATE TABLE t13(
id INT ,
`name` VARCHAR(32)
)
#添加主键索引方法2:在创建表的时候没有添加,就另外alter
ALTER TABLE t13 ADD PRIMARY KEY (id)
-- 添加唯一索引
#方法1
CREATE UNIQUE INDEX id_index ON t13(id)
#方法2:在创建表的时候添加unique关键字
CREATE TABLE t14(
id INT UNIQUE,
`name` VARCHAR(32)
)
#查询索引
SHOW INDEXES FROM t13 # id是主键索引,name是唯一索引
-- 添加普通索引
# 方法1
CREATE INDEX id_index ON t12(id)
# 方法2
ALTER TABLE t12 ADD INDEX id_index (id)
删除索引
代码实例
-- 删除索引演示
#删除普通索引
DROP INDEX id_index ON t12
#删除主键索引
#细节1:以这种方式 drop index primary key on t12 是删除不了主键索引
ALTER TABLE t12 DROP PRIMARY KEY #正确删除主键索引的方式~
#删除唯一索引 同理
DROP INDEX id_index ON t12
修改索引
- 修改索引就只能通过删除之后再添加索引
查询索引
代码实例
-- 查询索引
#方法1
SHOW INDEX FROM 表名
#方法2
SHOW INDEXES FROM 表名
#方法3
SHOW KEYS FROM 表名
#方法4 :不够精确
DESC 表名
索引综合练习
代码实例
添加主键索引
-- 建立索引(主键)课后练习
-- 要求:
-- 1.创建一张订单表order (id号,商品名,订购人,数量). 要求id号为主键,请使
-- 用2种方式来创建主键. (提示:为练习方便,可以是order1 , order2 )
#创建主键方法1,直接创建表的同时添加主键
CREATE TABLE order1(
id INT PRIMARY KEY,
goods_name VARCHAR(32),
customer VARCHAR(32),
num INT
)
#创建表
CREATE TABLE order2(
id INT,
goods_name VARCHAR(32),
customer VARCHAR(32),
num INT
)
#创建主键索引方法2
#细节:不要忘记ADD,这是添加索引哦,添加的英语就是add哦~
ALTER TABLE order2 ADD PRIMARY KEY(id)
添加唯一索引
-- 建立索引(唯一)课后练习
-- 要求:
-- 1.创建一张特价菜谱表menu (id号,菜谱名,厨师,点餐人身份证,价
-- 格).要求id号为主键,点餐人身份证是unique请使用两种方式来创建
-- unique.(提示:为练习方便,可以是menu1 , menu2)
#添加唯一索引方法1
CREATE TABLE menu1(
id INT PRIMARY KEY,#直接添加主键
menu_name VARCHAR(32),
customer_id VARCHAR(64) UNIQUE #直接添加唯一索引,索引的名字也会是customer_id
)
#查询索引
SHOW KEYS FROM menu1
#创建表
CREATE TABLE menu2(
id INT PRIMARY KEY,
menu_name VARCHAR(32),
customer_id VARCHAR(64)
)
#添加唯一索引方法2
ALTER TABLE menu2 ADD UNIQUE INDEX cus_id (customer_id)
#添加唯一索引方法3
CREATE UNIQUE INDEX cust_id ON menu2(customer_id)
添加普通索引
#创建运动员表
CREATE TABLE sportman1(
id INT PRIMARY KEY,
`name` VARCHAR(32)
)
CREATE TABLE sportman2(
id INT PRIMARY KEY,
`name` VARCHAR(32)
)
#创建普通索引方法1
CREATE INDEX `name_indx` ON sportman1(`name`)
#创建普通索引方法2
ALTER TABLE sportman2 ADD INDEX `nameindex` (`name`)
#创建普通索引方法3,直接在表后名添加INDEX(字段名)
CREATE TABLE sportman3(
id INT PRIMARY KEY,
`name` VARCHAR(32),
INDEX(`name`)
)
SHOW INDEX FROM sportman3
索引使用场合
- 较频繁的作为查询条件字段应该创建索引,例如序号
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件,例如性别
- 更新非常频繁的字段不适合创建索引,例如登录次数
- 不会出现在WHERE子句中字段不该创建索引
MySQL事务
什么是事务
-
事务用于保证数据的一致性,它由一组相关的DML语句组成, 该组的dml语句要么全部成功,要么全部失败。如: 转账就要用事务来处理,用以保证数据的一致性。
-
数据库的**事务(Transaction)**是一种机制、一个操作序列,包含了一组数据库操作命令。事务把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令要么都执行,要么都不执行,因此事务是一个不可分割的工作逻辑单元。
在数据库系统上执行并发操作时,事务是作为最小的控制单元来使用的,特别适用于多用户同时操作的数据库系统。例如,航空公司的订票系统、银行、保险公司以及证券交易系统等。
事务和锁
- 当执行事务操作时(dml语句) ,mysql会在表上加锁,防止其它用户改表的数据。
- 回退事务
保存点(savepoint)是事务中的点,用于取消部分事务,当结束事务时(commit) ,会自动的删除该事务所定义的所有保存点。当执行回退事务时,通过指定保存点可以回退到指定的点 - 提交事务
使用commit语句可以提交事务.当执行commit语句后,会确认事务的变化、结束事务、删除保存点、释放锁,数据生效。当使用commit语句结束事务后,其它会话[其他连接]将可以查看到事务变化后的新数据[所有数据就正式生效] - 锁定用于确保事务完整性和数据库一致性。 锁定可以防止用户读取其他用户正在更改的数据,并防止多个用户同时更改相同的数据。 如果不使用锁定,数据库中的数据可能在逻辑上变得不正确,而针对这些数据进行查询可能会产生想不到的结果。
- 在计算机科学中,锁是在执行多线程时用于强行限制资源访问的同步机制,即用于在并发控制中保证对互斥要求的满足。在数据库的锁机制中介绍过,在DBMS中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和页级锁(BDB引擎 )。
事务操作
MySQL数据库控制台事务的几个重要操作
| 操作 | 作用 |
|---|---|
| start transaction | 开始一个事务 |
| savepoint 保存点名 | 设置保存点 |
| rollback to 保存点名 | 回退事务 |
| rollback | 回退全部事务 |
| commit | 提交事务,所有的操作生效,不能回退 |

代码实例
-- 事务操作
#创建表
CREATE TABLE t15(
id INT,
`name` VARCHAR(32)
)
#开始一个事务
START TRANSACTION #直接运行即可
#设置保存点
# 语法 :SAVEPOINT 保存点名字
SAVEPOINT save1
#操作表,更新表的数据
INSERT INTO t15 VALUE(1,'aha')
#设置保存点把数据保存
SAVEPOINT save2
INSERT INTO t15 VALUE(2,'aha2')
#查询表有两条数据
SELECT * FROM t15
#回退事务
#回退到我第一次保存的只有一条数据的点
# ROLLBACK TO 表名
ROLLBACK TO save2 #回退成功
#也可直接回退到指定的保存点
#直接回退到save1
ROLLBACK TO save1
#不指定名字回退全部事务
ROLLBACK #回到空表状态
#提交事务,所有操作生效,不能回退
#commit
COMMIT
事务细节
- 如果不开始事务,默认情况下,dml操作是自动提交的,不能回滚。
- 如果开始一个事务,你没有创建保存点,,你可以执行``rollback`,默认就是回退到你事务开始的状态。
- 你也可以在这个事务中(还没有提交时),创建多个保存点.比如:
savepoint aaa;执行dml ,savepoint bbb;。 - 你可以在事务没有提交前,选择回退到哪个保存点。
- mysql的事务机制需要innodb的存储引擎才可以使用,myisam不好使。
- 开始一个事务的两种语法:
start transaction;;set autocommit= off;
事务隔离
不考虑隔离性引发的问题
-
脏读(dirty read): 当一个事务读取另一个事务尚未提交的改变(update,insert,delete)时,产生脏读。
-
不可重复读(nonrepeatable read): 同一查询在同一事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生不可重复读。
-
幻读(phantom read): 同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻读。
MySQL隔离级别
概念 : MySQL隔离级别定义了事务与事务之间的隔离程度。
| MySQL隔离级别(4种) | 脏读 | 不可重复读 | 幻读 | 加锁读 |
|---|---|---|---|---|
| 读未提交(Read uncommitted) | √ | √ | √ | 不加锁 |
| 读已提交(Read committed) | × | √ | √ | 不加锁 |
| 可重复读(Repeatable read) | × | × | × | 不加锁 |
| 可串行化(Serializable) | × | × | × | 加锁 |
查看事务隔离级别:查看当前会话隔离级别 select @@tx_isolation;
代码实例
这里使用两个控制台(作为客户端)演示
一、测试读未提交 (READ UNCOMMITTED)隔离级别
-- 1.使用管理员身份打开两个命令行控制台
#通过以下命令行分别在两个控制台登录数据库
mysql -u root -p
-- 查看当前MySQL的隔离级别
#命令行中输入SELECT @@tx_isolation
SELECT @@tx_isolation #默认为可重复读 REPEATABLE-READ
-- 查询结果
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 ROW IN SET, 1 warning (0.00 sec)
-- 2.把控制台2设置成读未提交级别 READ UNCOMMITTED
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;#设置成功Query OK, 0 rows affected (0.00 sec)
-- 3.调用数据库(两个都要)
USE yjm_db02
-- 4.创建表(只需一个控制台执行)
CREATE TABLE tab(
id INT,
`name` VARCHAR(32)
) #创建成功 Query OK, 0 rows affected (0.05 sec)
-- 5.启动事务(两个控制台都要启动)
START TRANSACTION #Query OK, 0 rows affected (0.00 sec)
-- 6.在控制台1添加数据
INSERT INTO tab VALUE(1,'张三');
-- 7.在控制台2进行查询可以看到控制台1新添加的数据
SELECT * FROM tab; #可以看到控制台1未提交的数据这叫脏读
-- 8.在控制台修改表1的数据
UPDATE tab SET id = 100 WHERE id =1;
-- 9.在控制台1插入数据
INSERT INTO tab VALUE(20,'李四');
-- 10.控制台1把8,9步骤事务提交commit
COMMIT; #Query OK, 0 rows affected (0.00 sec)
-- 11.控制台2未commit而进行查询
#不可重复读(nonrepeatable read):能看到控制台1提交事务所做的修改(把id 1改成100的数据结果)
#幻读(phantom read):能看到控制台1提交事务所做的插入操作结果(20,'李四')
#总结:控制台2的隔离级别为读未提交(Read uncommitted)就会出现脏读,不可重复读,幻读三种问题
二、测试读已提交(READ COMMITTED)隔离级别
-- 1.重新开始启动事务
START TRANSACTION;
-- 2.修改控制台2的隔离级别为READ COMMITTED并开启事务
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 3.在控制台1进行更新数据
INSERT INTO tab VALUE(300,'王五');
-- 4.在控制台2进行查询
SELECT * FROM tab;
#未能查询到控制台1更新的数据(300,'王五'),说明没有出现脏读
-- 5.控制台1 进行commit之后
COMMIT;
#控制台2再次查询可以看到(300,'王五')说明还有不可重复读和幻读
三、测试可重复读(REPEATABLE READ)隔离级别
-- 1.修改控制台2隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
#查询确认
SELECT @@tx_isolation;
-- 2. 控制1和2都提交commit上一次事务并重新开始事务
START TRANSACTION;
-- 3.控制台1更行数据,赵六的id原本是400
UPDATE tab SET id = 600 WHERE `name`='赵六';
-- 4.控制台2查询数据未查询到VALUE(600,'赵六')
#没出现脏读
-- 5.控制台1进行commit,而控制台2再次查询没有出现(id = 600,`name`='赵六')
COMMIT;
#说明没有出现不可重复读和幻读
四、测试可串行化(SERIALIZABLE) 隔离级别
-- 1.修改控制台2隔离级别为SERIALIZABLE
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- 2. 控制1和2都提交commit上一次事务并重新开始事务
COMMIT;
START TRANSACTION;
-- 3.控制台1可以正常对表进行操作
-- 4.控制台2无法对表进行任何操作
INSERT INTO tab VALUE(1000,'阿哈');#enter键无反应
#控制台2报错:1205 (HY000): Lock wait timeout exceeded; try restarting transaction
-- 5.只有等控制台1commit提交事务之后控制台2才能正常操作
INSERT INTO tab VALUE(1000,'阿哈');#成功回车
设置隔离
- 查看当前会话隔离级别
select @@tx_isolation; - 查看系统当前隔离级别
select @@global.tx_isolation; - 设置当前会话隔离级别
set session transaction isolation level 隔离级别; - 设置系统当前隔离级别
set global transaction isolation level 隔离级别; - mysql 默认的事务隔离级别是
repeatable read,一般情况下,没有特殊要求,没有必要修改(因为该级别可以满足绝大部分项目需求)
代码实例
-- 查看当前会话隔离级别
-- `select @@tx_isolation;`
SELECT @@tx_isolation; #默认为REPEATABLE-READ(可重复读)
-- 查看系统当前隔离级别
-- `select @@global.tx_isolation;`
SELECT @@global.tx_isolation #默认为REPEATABLE-READ
-- 设置当前会话隔离级别
-- `set session transaction isolation level 隔离级别;`
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; #设置为可重复读
-- 设置系统当前隔离级别
-- `set global transaction isolation level 隔离级别;`
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ; #设置为可重复读
全局修改事务隔离级别
-
修改my.ini配置文件,在文件最后加上下面语句
transaction-isolation = REPEATA BLE-READ#修改为可重复读 -
可选参数有:
READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ,SERIALIZABLE注:非必要不修改
事务的ACID特性
- 原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 - 一致性 (Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。 - 隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一-个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 - 持久性(Durability)
持久性是指一个事务一旦被提交, 它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
存储引擎
mysql表类型和存储引擎
基本介绍
- MySQL的表类型由存储引擎(Storage Engines) 决定,主要包括MyISAM、innoDB、Memory等。
- MySQL 数据表主要支持六种类型,分别是: CSV、Memory、ARCHIVE、MRG_MYISAM、MYISAM、 InnoDB。
- 这六种又分为两类:
- 一类是”事务安全型”(transaction-safe), 比如:InnoDB;
- 其余都属于第二类,称为”非事务安全型”(non-transaction-safe) [myisam和memory]。
-
查询当前数据库支持的存储引擎的语句:
show engines; -
查看某个库下指定表使用的存储引擎
show table status from 库名 wherename='表名';
主要的存储引擎/表类型特点
| 特点 | Myisam | InnoDB | Memory | Archive |
|---|---|---|---|---|
| 批量插入的速度 | 高 | 低 | 高 | 非常高 |
| 事务安全 | 支持 | |||
| 全文索引 | 支持 | |||
| 锁机制 | 表锁 | 行锁 | 表锁 | 行锁 |
| 存储限制 | 没有 | 64TB | 有 | 没有 |
| B树索引 | 支持 | 支持 | 支持 | |
| 哈希索引 | 支持 | 支持 | ||
| 集群索引 | 支持 | |||
| 数据缓存 | 支持 | 支持 | ||
| 索引缓存 | 支持 | 支持 | 支持 | |
| 数据可压缩 | 支持 | 支持 | ||
| 空间使用 | 低 | 高 | N/A | 非常低 |
| 内内存使用 | 低 | 高 | 中等 | 低 |
| 支持外键 | 支持 |
三种常用引擎细节
- MyISAM不支持事务、 也不支持外键,但其访问速度快,对事务完整性没有要求
- InnoDB存储引擎提供 了具有提交、回滚和崩溃恢复能力的事务安全。但是比起MyISAM存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
- MEMORY存储引擎使用存在内存中的内容来创建表。每个MEMORY表只实际对应一个磁盘文件。MEMORY类型的表访问非常得快,因为它的数据是放在内存中的,并且默认使用HASH索引。但是一旦服务关闭,表中的数据就会丢失掉,表的结构还在。
- 手动修改存储引擎:
ALTER TABLE 表名 ENGINE = 储存引擎;
代码实例
-- 存储引擎演示
#查询当前MySQL支持的存储引擎
SHOW ENGINES;#七种支持
-- InnoDB存储引擎
#优点:1.支持事务. 2.支持外键. 3支持行级锁
-- MyISAM存储引擎
-- 1.添加速度快 2.不支持外键和事务 3.支持表级锁
#创建表,MyISAM存储引擎
CREATE TABLE t20(
id INT,
`name` VARCHAR(32)) ENGINE MYISAM;
#开启事务
START TRANSACTION;
#设置保存点
SAVEPOINT save1;
#添加数据
INSERT INTO t20 VALUE(1,'Aha')
#试图回退到保存点1
ROLLBACK TO savel;
SELECT * FROM t20; #(1,'Aha') 回滚失败,MYISAM不支持事务
-- MEMORY存储引擎
-- 1.数据存储在内存中(关闭MySQL服务数据就丢失,但是表结构还在)
-- 2.执行速度非常快(没有IO读写)
-- 3.默认支持索引(hash表)
#创建表 引擎为 MEMORY
CREATE TABLE t21(
id INT,
`name` VARCHAR(32)) ENGINE MEMORY;
#添加数据
INSERT INTO t21 VALUE(1,'Aha')
#查询数据
SELECT * FROM t21;#数据添加成功
#使用DOS命令窗口关闭数据库
#net STOP mysql57 自己安装的数据库名
net STOP mysql57
#开启数据库
net START mysql57
# 重新查询表
SELECT * FROM t21;#数据1,'Aha'丢失,只剩下表结构
#查看某个库下指定表使用的存储引擎
#语法:show table status from 库名 where `name`='表名';
SHOW TABLE STATUS FROM yjm_db02 WHERE `name`='t20';
补充:开启失败(或)停止失败(或)服务名无效
启动/停止mysql两种方法:
方法一:搜索栏搜索“服务”,进入“服务”找到mysql手动开启。
方法二:以“管理员”身份开启cmd,输入命令“net start mysql”即可开启。
问题:开启失败(或)停止失败(或)服务名无效?
搜索栏搜索“服务”,进入“服务”找到你的mysqlxx,比如我的mysql叫做“mysql57”,所以命令改为“net start mysql57”即可。你的mysql实际上叫什么,你就改成什么。
存储引擎使用场合
- 如果你的应用不需要事务,处理的只是基本的CRUD操作,那么MyISAM是不二选择,速度快。
- 如果需要支持事务*,选择InnoDB。
- Memory 存储引擎就是将数据存储在内存中,由于没有磁盘l/O的等待,速度极快。但由于是内存存储引擎,所做的任何修改在服务器重启后都将消失。(经典用法用户的在线状态)
视图(VIEW)
视图和真实表的关系

视图的基本使用
1.创建视图:create view 视图名 as select 视图需要的列 FROM 基表名;
2.修改视图的字段:alter view 视图名 as select 视图需要的列 FROM 基表名;
3.查询视图如何创建:SHOW CREATE VIEW 视图名;
4.#删除视图:``drop view 视图名1,视图名2… `
代码实例
-- 视图演示
#创建视图
-- 1.create view 视图名 as select 视图需要的列 FROM 基表名;
CREATE VIEW emp_view AS SELECT empno,ename,job,deptno FROM emp; #创建视图成功
#修改视图的字段
-- 2.alter view 视图名 as select 视图需要的列 FROM 基表名;
ALTER VIEW emp_view AS SELECT empno,ename,job FROM emp;
SELECT * FROM emp_view;
#查询视图如何创建
-- 3.SHOW CREATE VIEW 视图名;
SHOW CREATE VIEW emp_view;
#删除视图
-- 4.drop view 视图名1,视图名2
DROP VIEW emp_view;
-- 视图中还可创建视图
#创建视图emp_view1
CREATE VIEW emp_view1 AS SELECT empno,ename,job,deptno FROM emp;
#基于emp_view1创建emp_view2
CREATE VIEW emp_view2 AS SELECT empno,ename FROM emp_view1;
#细节1:无论视图如何套娃,数据都来源于基表
#细节2:视图的变化影响基表,基表的变化也影响视图
#细节3:视图只有一个视图结构文件(形式:视图名.frm),并没有数据文件
视图细节
-
细节1:视图中还可使用视图,无论视图如何套娃,数据都来源于基表
-
细节2:视图的变化影响基表,基表的变化也影响视图
-
细节3:视图只有一个视图结构文件(形式:视图名.frm),并没有数据文件
视图最佳实践
- 安全。一些数据表有着重要的信息。有些字段是保密的,不能让用户直接看到。这时就可以创建一个视图,在这张视图中只保留一部分字段。这样,用户就可以查询自己需要的字段,不能查看保密的字段。
- 性能。关系数据库的数据常常会分表存储,使用外键建立这些表的之间关系。这时,数据库查询通常会用到连接(JOIN) 。这样做不但麻烦,效率相对也比较低。如果建立一个视图,将相关的表和字段组合在一起,就可以避免使用JOIN查询数据。
- 灵活。如果系统中有一张旧的表,这张表由于设计的问题,即将被废弃。然而,很多应用都是基于这张表,不易修改。这时就可以建立一张视图,视图中的数据直接映射到新建的表。这样,就可以少做很多改动,也达到了升级数据表的目的。
代码实例
-- 视图的课堂练习
-- 针对emp,dept,和salgrade张三表.创建一个视图 emp_ view03,
-- 可以显示雇员编号,雇员名,雇员部门名称和薪水级别[即使用三张表,构建一个视图]
#思路
#1.先把需要的字段通过多表查询查出来
#1.1同时查询三个表的所有字段会得到笛卡尔集,这是不可取
#1.2所以要通过条件去筛选出来对应的表
#2.再把查询出来的表创建成视图即可
SELECT * FROM emp,dept,salgrade;#笛卡尔集,260行数据
#通过条件去筛选字段,三个表至少需要两个条件确定
#1.emp表的员工的部门号肯定对应dept表的部门号
#2.工资等级表的工资范围肯定对应员工表的工资
SELECT * FROM emp,dept,salgrade
WHERE emp.`deptno`=dept.`deptno`
AND (emp.`sal` BETWEEN salgrade.losal AND salgrade.hisal)
#把查询出来的表创建成视图即可
#显示雇员编号,雇员名,雇员部门名称和薪水级别
CREATE VIEW emp_view0
AS
SELECT empno,ename,dname,grade FROM emp,dept,salgrade
WHERE emp.`deptno`=dept.`deptno`
AND (emp.`sal` BETWEEN salgrade.losal AND salgrade.hisal);
SELECT * FROM emp_view0
MySQL用户管理
补充: localhost是什么?
localhost就是本地主机,具体参考以下文章。
localhost,127.0.0.1,本机IP,三者的区别 - CarterLee - 博客园 (cnblogs.com)
MysQL用户
MysQL中的用户,都存储在系统数据库MysQL中user表中。
其中user表的重要字段说明:
-
host: 允许登录的 “位置”;,localhost表示该用户只允许本机登录,也可以指定ip地址,比如:192. 168.1.100
-
user: 用户名;
-
authentication string : 密码;是通过MysQL的password( ) 函数加密之后的密码。
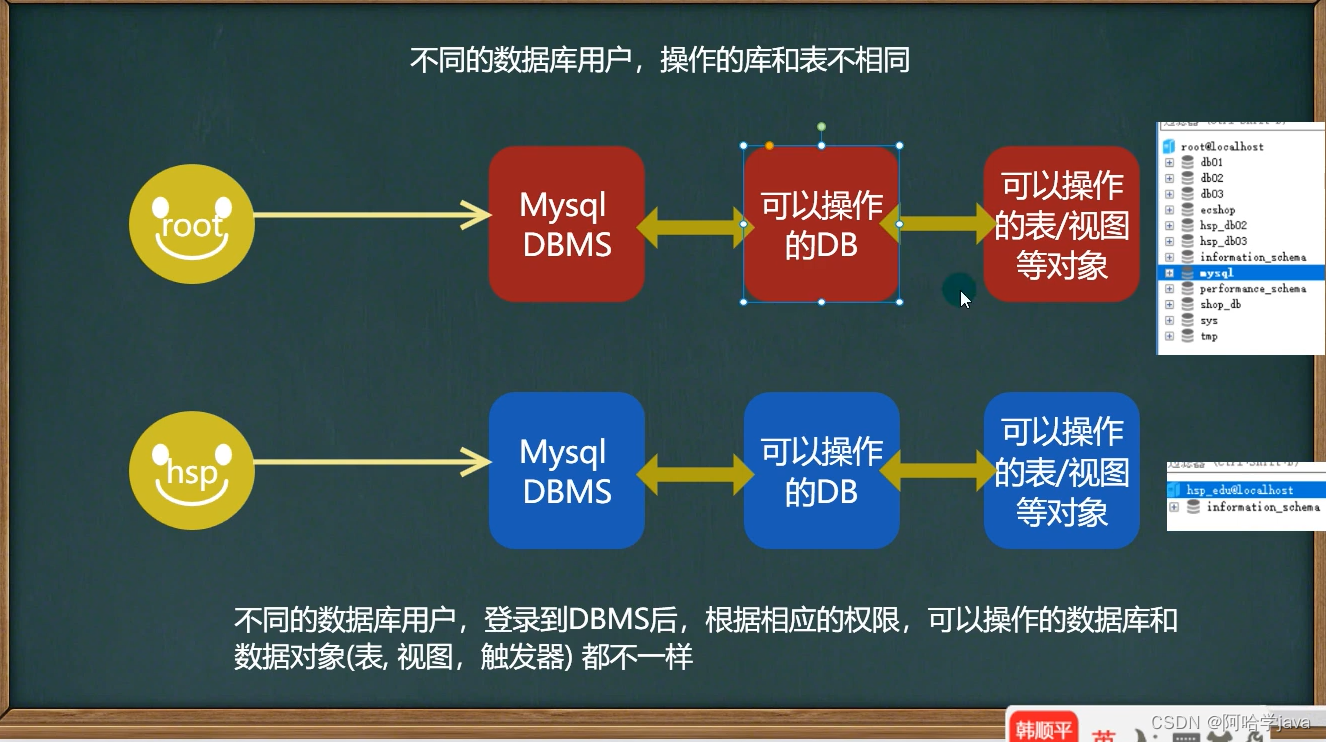
进行用户的管理的原因: 当我们做项目开发时,可以根据不同的开发人员,赋给他相应的Mysql操作权限;所以Mysql数据库管理人员(root),根据需要创建不同的用户,赋给相应的权限,供人员使用
基本操作
-
创建用户
CREATE USER '用户名'@'允许登录位置' IDENTIFIED BY '密码'说明:创建用户,同时指定密码
-
删除用户
DROP USER '用户名'@'允许登录位置'; -
修改密码
修改自己的密码:set password = password('密码');
修改他人的密码(需要有修改用户密码权限):set password for '用户名'@'登录位置' = password('密码');
代码实例
-- 创建用户
-- create user '用户名'@'允许登录位置' identified by '密码'
-- 说明:创建用户,同时指定密码
-- 删除用户
-- drop user '用户名'@'允许登录位置';
#创建一个名为Aha,密码为123,登录地址为本地主机的用户
CREATE USER 'Aha'@'localhost' IDENTIFIED BY '123';#成功
#可以尝试一下登录
#新建会话登录
#删除用户
DROP USER 'Aha'@'localhost';
-- 用户修改密码
-- 修改自己的密码:
-- set password = password('密码');
-- 修改他人的密码(需要有修改用户密码权限)
-- set password for '用户名'@'登录位置' = password('密码');
#演示修改他人的密码(需要有修改用户密码权限)
SET PASSWORD FOR 'Aha'@'localhost' = PASSWORD('123456');
权限管理
常用权限:
| 权限 | 说明 |
|---|---|
| ALL, ALL PRIVILEGES | 所有权限 |
| SELECT | 查询数据 |
| INSERT | 插入数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| ALTER | 修改表 |
| DROP | 删除数据库/表/视图 |
| CREATE | 创建数据库/表 |
更多权限请看权限一览表
基本语法
授予权限:
grant 权限列表 on 数据名库.表名 to '用户名'@'登录位置' [identified by '密码']
或者不指定密码的 grant 权限列表 on 数据名库.表名 to '用户名'@'登录位置'
说明:
-
权限列表,多个权限用逗号分开
grant select on...
grant select, delete, create on ...
grant all [privileges] on ...//表示赋予该用户在该对象上的所有权限 -
特别说明
*.*: 代表本系统中的所有数据库的所有对象(表, 视图,存储过程)
库名.*:表示某个数据库中的所有数据对象(表,视图,存储过程等) -
identified by不需要就可以省略,写出表示
(1)如果用户存在,就是修改该用户的密码。
(2)如果该用户不存在,就是创建新用户。
查询权限:
SHOW GRANTS FOR '用户名'@'登录位置';
撤销权限:
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'登录位置';
注意事项
- 多个权限用逗号分隔
- 授权时,数据库名和表名可以用 * 进行通配,代表所有
代码实例
-- 用户管理练习题
-- 1.创建一个用户(你的名字,拼音),密码123, 并且只可以从本地登录,不让远程登录mysql
CREATE USER 'Aha01'@'localhost' IDENTIFIED BY '123';#在root下创建
-- 2.创建库testdb和该库下的news表,要求:使用root用户创建
#创建库
CREATE DATABASE testdb;
#创建表
CREATE TABLE news(
id INT,
`name` VARCHAR(32)
);
-- 3.给用户分配查看news表和添加数据的权限
#给用户Aha分配权限
GRANT SELECT,INSERT ON testdb.news TO 'Aha01'@'localhost';
#显示Aha01得到的权限GRANT SELECT, INSERT ON `testdb`.`news` TO 'Aha01'@'localhost'
INSERT INTO news VALUE(1,'Aha01')
-- 4.测试看看用户是否只有这几个权限
#SHOW GRANTS FOR '用户名'@'登录位置';
SHOW GRANTS FOR 'Aha01'@'localhost';
#也可使用其他会话登录新用户测试
-- 5.修改密码为abc , 要求:使用root用户完成
-- 修改别人的密码set password for '用户名'@'登录位置' = password('密码');
SET PASSWORD FOR 'Aha01'@'localhost' = PASSWORD('abc');
-- 6. 给用户增加权限
#就是再使用赋予权限的语句把需要增加的权限赋值给用户即可
#增加更新数据的权限
GRANT UPDATE ON testdb.news TO 'Aha01'@'localhost';
-- 7.撤销用户权限
#REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'登录位置';
REVOKE UPDATE ON testdb.news FROM 'Aha01'@'localhost';
-- 8.使用root用户删除你的用户
DROP USER 'Aha01'@'localhost';
细节说明
-
在创建用户的时候,如果不指定Host,直接
create user XXX;Host则为% , %表示表示所有IP都有连接权限 -
你也可以这样指定
create user 'xx'@'192.168.1.%'表示xxx用户在192.168.1.*的ip可以登录MySQL -
在删除用户的时候,如果host不是%,需要明确指定
'用户'@'host值'
代码实例
-- 1. 在创建用户的时候,如果不指定Host,直接`create user XXX;` Host则为% , %表示表示所有IP都有连接权限
CREATE USER Aha;
#可以从mysql系统表user下查询用户
SELECT `user`,`host` FROM mysql.`user`;
#Aha 用户的host显示为 %
-- 2. 你也可以这样指定``create user 'xx'@'192.168.1.%'``表示xxx用户在``192.168.1.*``的ip可以登录MySQL
CREATE USER 'Aha02'@'192.168.1.%';
SELECT `user`,`host` FROM mysql.`user`;
#Aha01 用户的host显示为 192.168.1.%
-- 3. 在删除用户的时候,如果host不是%,需要明确指定 '用户'@'host值'
#如果host是%就直接删除用户名
DROP USER Aha;
#否则创建了什么就要删除什么
DROP USER 'Aha02'@'192.168.1.%';
剧终综合作业
作业一
1.选择题
(1).以下哪条语句是错误的? [D]
A. SELECT empno,ename NAME,sal salary FROM emp;
B. SELECT empno,ename NAME,sal AS salary FROM emp;
C. SELECT ename,sal*12 AS 'Annual Salary' FROM emp;
D. SELECT ename,sal*12 Annual Salary FROM emp;
#细节:起别名可以不用AS
#D选项的Annual Salary之间带有空格,只能识别到前面Annual作为别名,后面Salary作为新的字段
(2).某用户希望显示补助非空的所有雇员信息,应该使用哪条语句? [B]
A. SELECT ename, sal,comm FROM emp WHERE comm<> NULL;
B. SELECT ename,sal,comm FROM emp WHERE comm IS NOT NULL;
C. SELECT ename,sal,comm FROM emp WHERE comm<>0;
#空和非空只能用is
(3).以下哪条语句是错误的? [C]
A. SELECT ename,sal salary FROM emp ORDER BY sal;
B. SELECT ename,sal salary FROM emp ORDER BY salary;
C. SELECT ename,sal salary FROM emp ORDER BY 3;
#排序字段列表 可以识别别名排序,但是不能自己添加数字
作业二
…作业有空再补
权限一览表
具体权限的作用详见官方文档
GRANT 和 REVOKE 允许的静态权限
| Privilege | Grant Table Column | Context |
|---|---|---|
ALL [PRIVILEGES] | Synonym for “all privileges” | Server administration |
ALTER | Alter_priv | Tables |
ALTER ROUTINE | Alter_routine_priv | Stored routines |
CREATE | Create_priv | Databases, tables, or indexes |
CREATE ROLE | Create_role_priv | Server administration |
CREATE ROUTINE | Create_routine_priv | Stored routines |
CREATE TABLESPACE | Create_tablespace_priv | Server administration |
CREATE TEMPORARY TABLES | Create_tmp_table_priv | Tables |
CREATE USER | Create_user_priv | Server administration |
CREATE VIEW | Create_view_priv | Views |
DELETE | Delete_priv | Tables |
DROP | Drop_priv | Databases, tables, or views |
DROP ROLE | Drop_role_priv | Server administration |
EVENT | Event_priv | Databases |
EXECUTE | Execute_priv | Stored routines |
FILE | File_priv | File access on server host |
GRANT OPTION | Grant_priv | Databases, tables, or stored routines |
INDEX | Index_priv | Tables |
INSERT | Insert_priv | Tables or columns |
LOCK TABLES | Lock_tables_priv | Databases |
PROCESS | Process_priv | Server administration |
PROXY | See proxies_priv table | Server administration |
REFERENCES | References_priv | Databases or tables |
RELOAD | Reload_priv | Server administration |
REPLICATION CLIENT | Repl_client_priv | Server administration |
REPLICATION SLAVE | Repl_slave_priv | Server administration |
SELECT | Select_priv | Tables or columns |
SHOW DATABASES | Show_db_priv | Server administration |
SHOW VIEW | Show_view_priv | Views |
SHUTDOWN | Shutdown_priv | Server administration |
SUPER | Super_priv | Server administration |
TRIGGER | Trigger_priv | Tables |
UPDATE | Update_priv | Tables or columns |
USAGE | Synonym for “no privileges” | Server administration |
GRANT 和 REVOKE 允许的动态权限
| Privilege | Context |
|---|---|
APPLICATION_PASSWORD_ADMIN | Dual password administration |
AUDIT_ABORT_EXEMPT | Allow queries blocked by audit log filter |
AUDIT_ADMIN | Audit log administration |
AUTHENTICATION_POLICY_ADMIN | Authentication administration |
BACKUP_ADMIN | Backup administration |
BINLOG_ADMIN | Backup and Replication administration |
BINLOG_ENCRYPTION_ADMIN | Backup and Replication administration |
CLONE_ADMIN | Clone administration |
CONNECTION_ADMIN | Server administration |
ENCRYPTION_KEY_ADMIN | Server administration |
FIREWALL_ADMIN | Firewall administration |
FIREWALL_EXEMPT | Firewall administration |
FIREWALL_USER | Firewall administration |
FLUSH_OPTIMIZER_COSTS | Server administration |
FLUSH_STATUS | Server administration |
FLUSH_TABLES | Server administration |
FLUSH_USER_RESOURCES | Server administration |
GROUP_REPLICATION_ADMIN | Replication administration |
GROUP_REPLICATION_STREAM | Replication administration |
INNODB_REDO_LOG_ARCHIVE | Redo log archiving administration |
NDB_STORED_USER | NDB Cluster |
PASSWORDLESS_USER_ADMIN | Authentication administration |
PERSIST_RO_VARIABLES_ADMIN | Server administration |
REPLICATION_APPLIER | PRIVILEGE_CHECKS_USER for a replication channel |
REPLICATION_SLAVE_ADMIN | Replication administration |
RESOURCE_GROUP_ADMIN | Resource group administration |
RESOURCE_GROUP_USER | Resource group administration |
ROLE_ADMIN | Server administration |
SESSION_VARIABLES_ADMIN | Server administration |
SET_USER_ID | Server administration |
SHOW_ROUTINE | Server administration |
SYSTEM_USER | Server administration |
SYSTEM_VARIABLES_ADMIN | Server administration |
TABLE_ENCRYPTION_ADMIN | Server administration |
VERSION_TOKEN_ADMIN | Server administration |
XA_RECOVER_ADMIN | Server administration |
图形化界面工具
- Workbench(免费): http://dev.mysql.com/downloads/workbench/
- navicat(收费,试用版30天): https://www.navicat.com/en/download/navicat-for-mysql
- Sequel Pro(开源免费,仅支持Mac OS): http://www.sequelpro.com/
- HeidiSQL(免费): http://www.heidisql.com/
- phpMyAdmin(免费): https://www.phpmyadmin.net/
- SQLyog: https://sqlyog.en.softonic.com/
修改MySQL的字符集
- 找到MySQL的配置文件
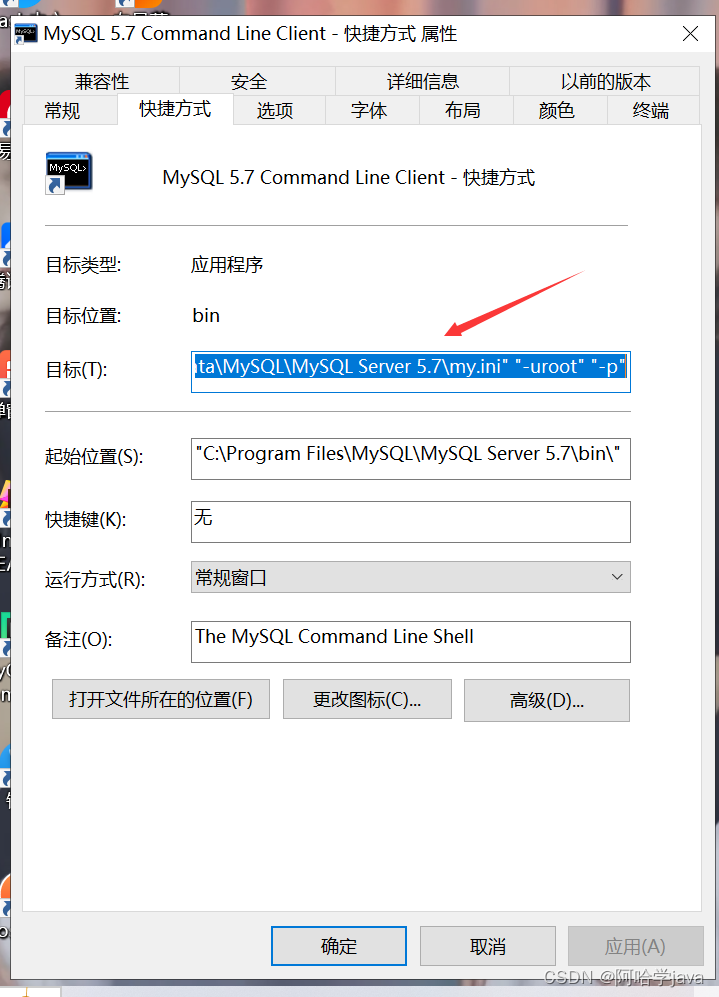
- 左键点击MySQL的属性查看my.ini文件目标路径
“C:\Program Files\MySQL\MySQL Server 5.7\bin\mysql.exe” “–defaults-file=C:\ProgramData\MySQL\MySQL Server 5.7\my.ini” “-uroot” “-p”
由此找到ini文件的路径,然后就去文件夹找就行了
如果找不到就是被隐藏了,我的ProgramData还被隐藏了,隐藏就勾选隐藏文件~
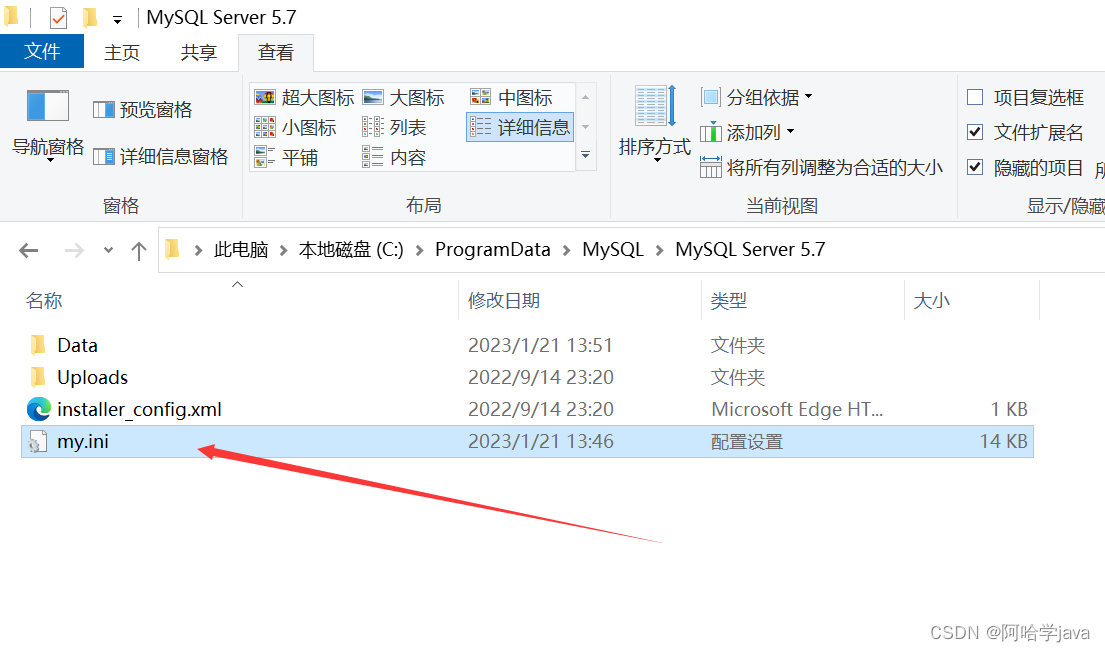
细节来了:建议使用vscode或者其他编辑器打开(没有就下一个
因为有其他b友反应使用记事本打开修改之后就出错了~
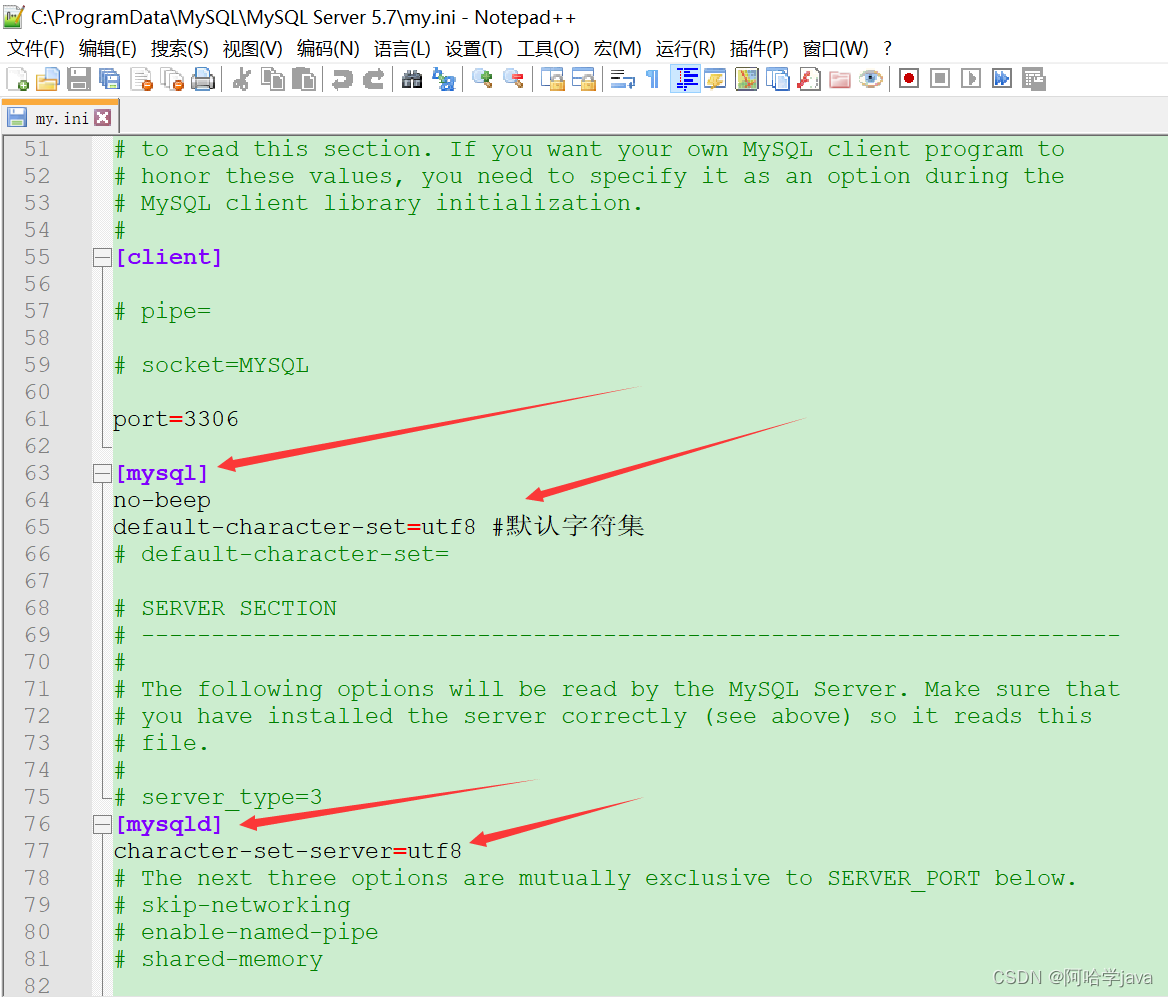
- 找到[mysql]和[mysqld]
分别添加65行和77行代码之后保存即可
- 重启MySQL
方法一直接重启电脑
方法二如下:
在桌面打开 此电脑 点击 管理

点击服务 找到MYSQL 左键鼠标重启 MySQL

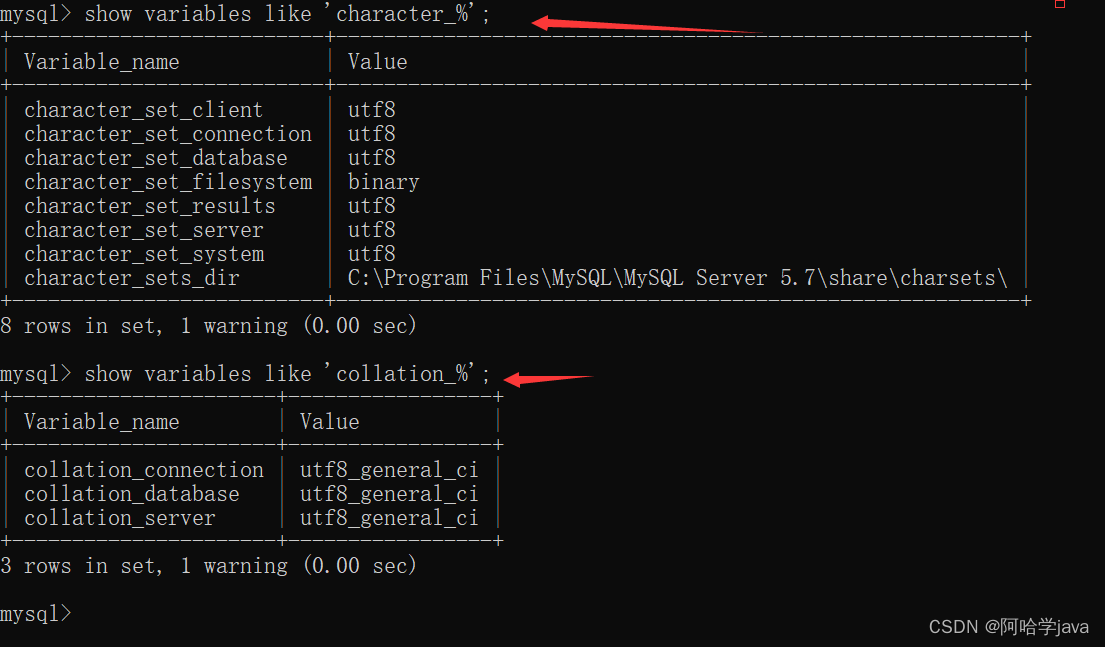
- 重启成功后重新打开MySQL分别输入这两句就能查看修改成功
问题:不能连接数据库
Can't connect to MySQL server on 'localhost' (10061)
运行cmd重新启动数据库的时候发生系统错误5,由于默认情况下cmd是以用户身份运行的,出现此类问题是由于没有权限。运行cmd时需要以管理员身份运行发
以管理员身份运行后再输入命令net start mysql57















 7067
7067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









