







KMP算法
KMP算法是一种字符串匹配算法,用于匹配模式串P在文本串S中出现的所有位置。
例如S=“ababac”,P="aba",那么出现的所有位置是1 3
KMP算法将原本O(n^2)的字符串匹配算法优化到了O(n),其精髓在于next数组,next数组表示此时模式串下标失配时应该移动到的位置,(每次下标失配时,就是i!=j了,j=next[j-1])也表示最长的相同真前后缀的长度。
字符串“aba”这个例子来说的话,前缀(从左往右数)有:a,ab,aba(因为aba与原字符相等,所以不是真前缀)后缀(从右往左):a,ba,aba
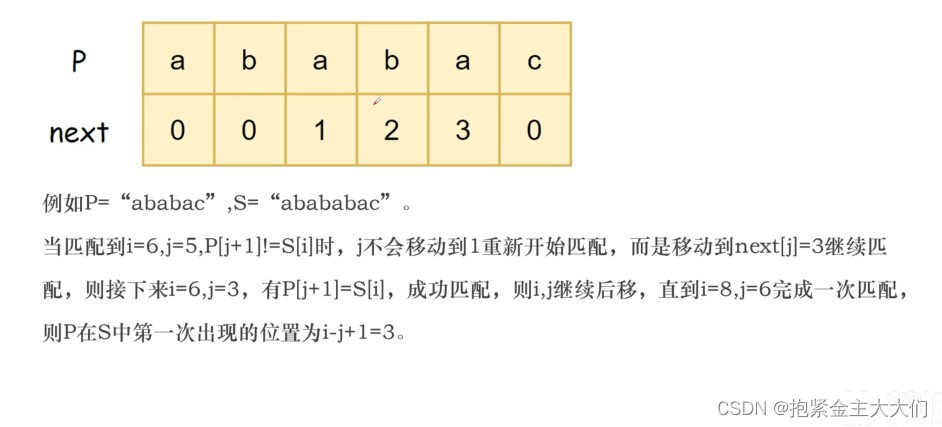
字符串aba
a的真前缀真后缀为0 ab的真前缀为a真后缀为b,所以也为0 aba的最长真前缀真后缀为a(长度设为1)所以aba的真前缀真后缀为1
字符串ababac
abab 的真前缀为 a,ab,aba真后缀有b,ab,bab所以最长真前后缀为ab,即为2
ababa 的真前缀有 a,ab,aba,abab,真后缀有a,ba,aba,baba,所以最长真前后缀为aba,即为3
计算next数组(next数组仅与模式串P有关)的方式就是P自己去匹配自己
KMP算法模板
int[] next=new int[p.length]; next[0]=0; for(in i=1,j=0;i<p.length;i++){ while(j>0&&p[j]!=p[i]){ j=next[j-1];//不断匹配i,j直到p[i]==p[j]或者j==0 } if(p[i]==p[j]){ j++; next[i]=j; } }
通过next数组进行匹配
for(int i=0,j=0;i<n;i++){ while(j>0&&s[i]!=p[j])j=next[j-1]; if(s[i]==p[j])j++; if(j==m)//匹配成功一次 }
字符串Hash算法
(基于进制的)字符串Hash本质上时一个用数字表示一段字符串,从而降低字符串处理的复杂度。
这个数字是一个很大的数字,采用long类型,还需要一个进制数base,用于规定这个数字的进制
Hash数组h[i]表示字符串s[1~i]的Hash值,采用类似前缀和的形式以便求出任意一个字串的Hash值。
(字符串转化成为数字)
字符串Hash初始化
long base=131;//base一般为一个质数(进制数)
long h[N];//h[i]表示s[1~i]的Hash(类似前缀和)
char s[N];//我们的字符串
for(int i=1;i<=n;++i) h[i]=h[i-1]*base+s[i]-'A'+1;//s[i]-‘A’+1表示字符串在我们字母表中的位置
获取字串s[1]~s[r]的Hash
long getHash(int l,int r){
return h[r]-h[l-1]*b[r-l+1];//b[i]表示base的i次方(预处理)
}
例题实战
斤斤计较的小 Z
题目描述
小 Z 同学没天都喜欢斤斤计较,今天他又跟字符串杠起来了。
他看到了两个字符串 S1 S2 ,他想知道 S1 在 S2 中出现了多少次。
现在给出两个串 S1,S2(只有大写字母),求 S1 在 S2 中出现了多少次。
输入描述
共输入两行,第一行为 S1,第二行为 S2。
输出描述
输出一个整数,表示 S1 在 S2 中出现了多少次。
输入输出样例
示例1
输入
LQYK
LQYK
输出
1
代码
kmp实现
public class jinjinjijiao {
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner scan=new Scanner(System.in);
char[] arr1=scan.next().toCharArray();
char[] arr2=scan.next().toCharArray();
int len1=arr1.length;
int len2=arr2.length;
int[] next=new int[len1];
for(int i=1,j=0;i<len1;i++) {
while(j>0&&arr1[i]!=arr1[j]) {
j=next[j-1];
}
if(arr1[i]==arr1[j]) {
j++;
}
next[i]=j;
}
int ans=0;
for(int i=0,j=0;i<len2;i++) {
while(j>0&&arr1[j]!=arr2[i]) {
j=next[j-1];
}
if(arr1[j]==arr2[i]) {
j++;
}
if(j==len1) {
ans++;
j=0;
}
}
System.out.println(ans);
}
}
Hash实现
package shiti;
import java.util.*;
public class Hash {
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner scan=new Scanner(System.in);
char[] arr1=scan.next().toCharArray();
char[] arr2=scan.next().toCharArray();
int m=arr1.length;
int n=arr1.length;
long[] h=new long[n+1];
long[] s=new long[n+1];
long res=0;
long base=131;
for(int i=0;i<m;i++) {//先求arr1的hash值
res=res*base+(arr1[i]-'A'+1);
}
s[0]=1;
for(int i=1;i<=n;i++) {
h[i]=h[i-1]*base+(arr2[i-1]-'A'+1);
s[i]=s[i-1]*base;
}
int ans=0;
for(int i=1;i+m-1<=n;i++) {
long sum=h[i+m-1]-h[i-1]*s[m];
if(sum==res)
ans++;
}
System.out.println(ans);
}
}















 981
981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









