






为分布式应用提供一致性协调服务的中间件
1. 分布式系统的问题:
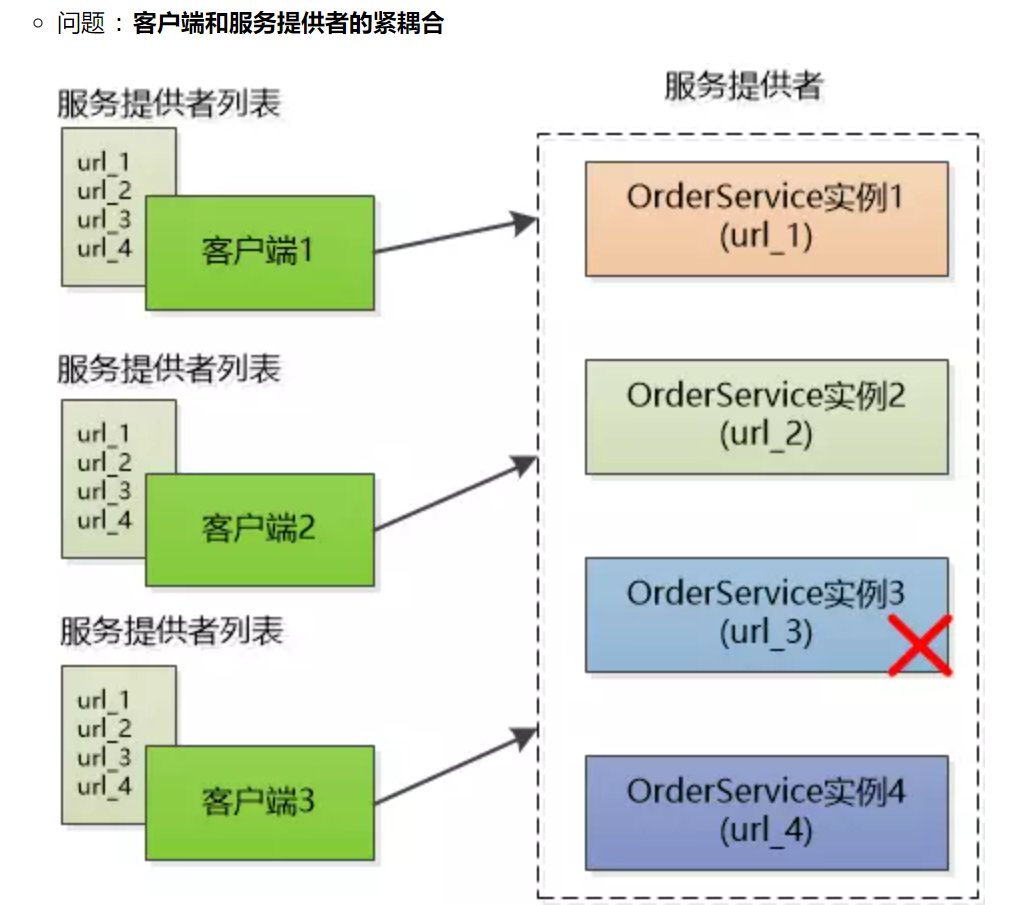
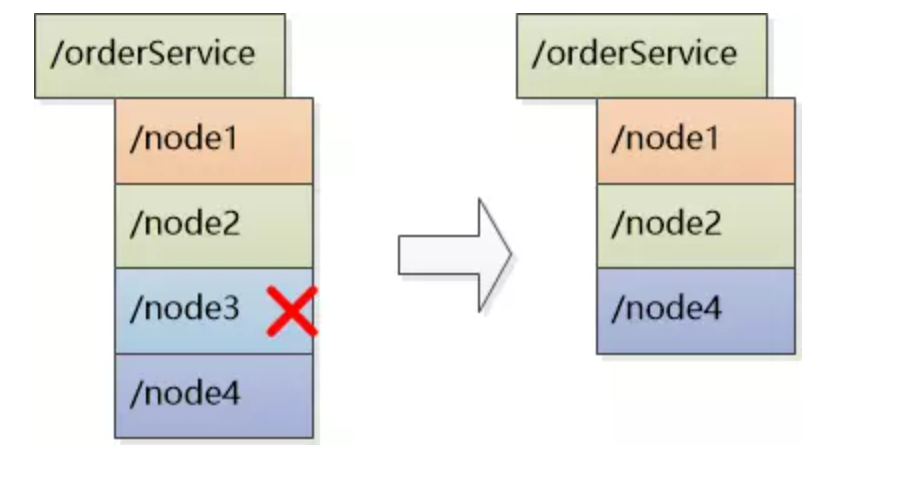
服务的动态注册和发现,为了支持高并发OrderService被部署了4份,每个客户端都保存了一份服务提供者的列表,但这个列表是静态的(在配置文件中写死的),如果服务的提供者发生了变化,例如有些机器down了,或者又新增了OrderService的实例,客户端根本不知道,想要得到最新的服务提供者的URL列表,必须手工更新配置文件,实时性低、很不方便。
2. Zookeeper提供的服务:
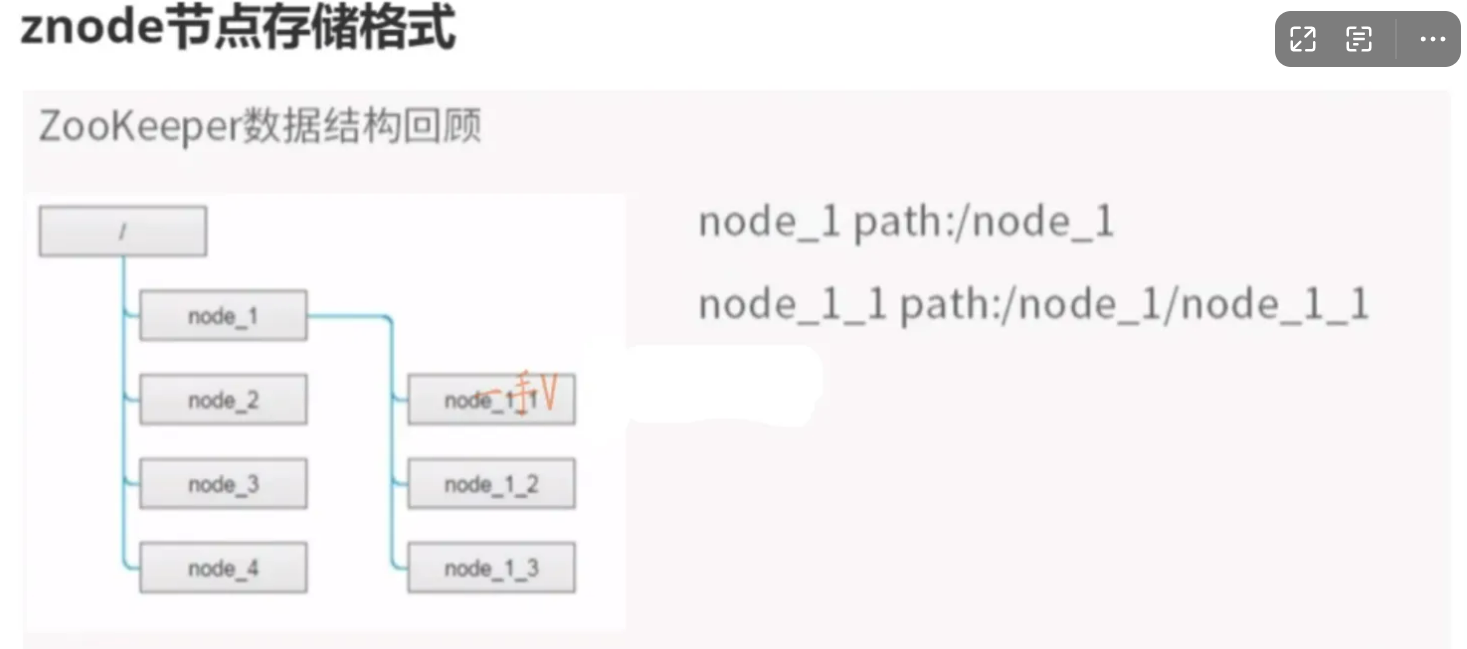
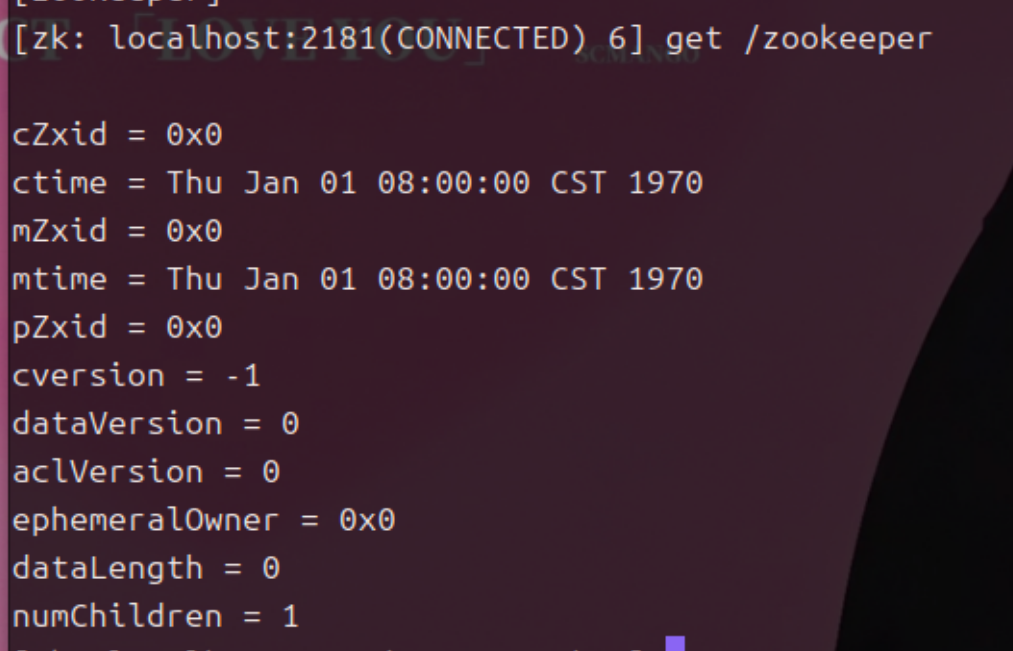
文件系统
Zookeeper提供一个多层级的节点命名空间(节点称为znode)。与文件系统不同的是,这些节点都可以设置关联的数据,而文件系统中只有文件节点可以存放数据而目录节点不行。Zookeeper为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得Zookeeper不能用于存放大量的数据,每个节点的存放数据上限为1M。
通知机制
client端会对某个znode建立一个watcher事件,当该znode发生变化时,这些client会收到zk的变化通知,然后client可以根据znode变化来做出业务上的改变等。
3. 分布式问题的解决方案:
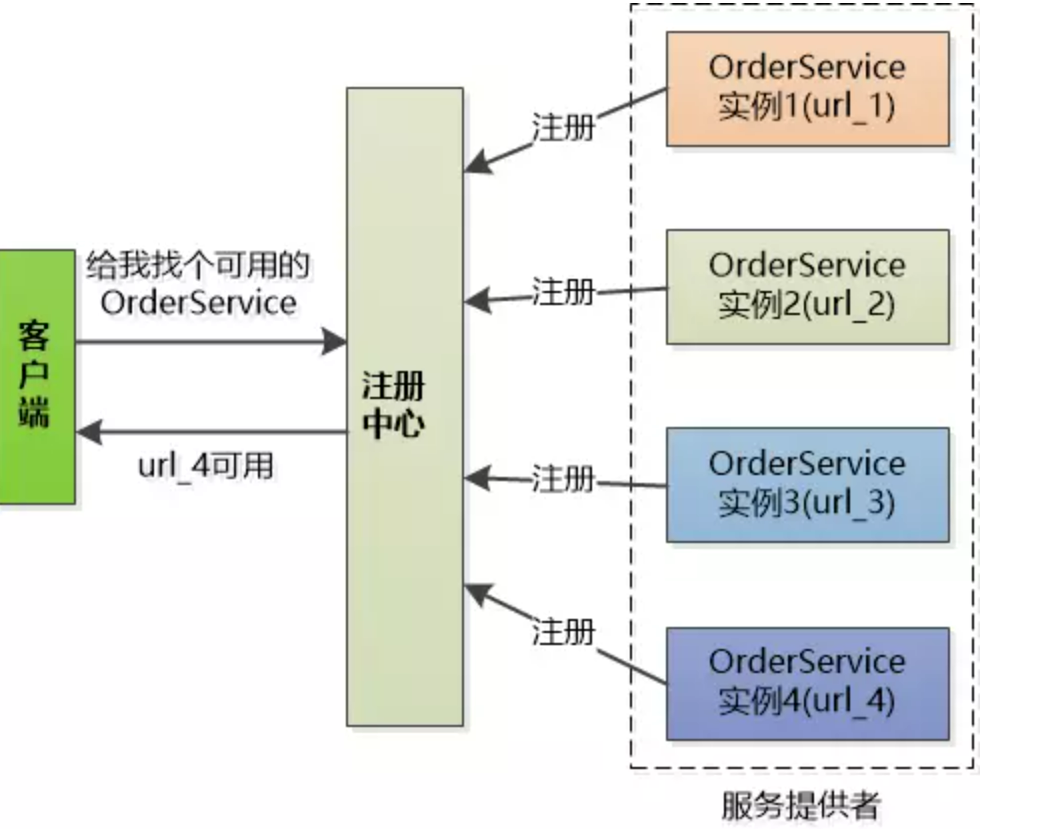
解除耦合,增加一个中间层 -- 注册中心它保存了能提供的服务的名称,以及URL。
- 首先这些服务会在注册中心进行注册
- 当客户端来查询的时候,只需要给出名称,注册中心就会给出一个URL(ip+port)
- 所有的客户端在访问服务前,都需要向这个注册中心进行询问,以获得最新的地址。
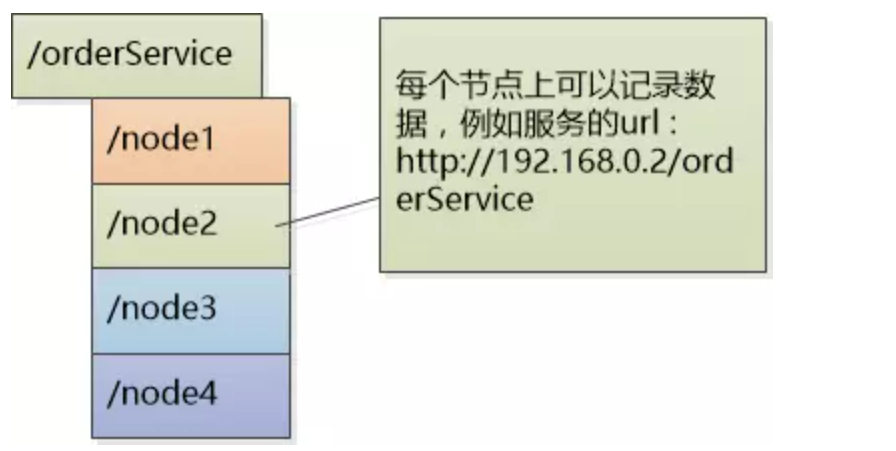
注册中心:
可以是树形结构,每个服务下面有若干节点,每个节点表示服务的实例。
结点心跳机制:
注册中心和各个服务实例直接建立Session保存结点的状态,要求实例们定期发送心跳,一旦Session超时收不到心跳,则认为服务实例挂了,删除该实例(临时性结点:可删除,永久性结点:超时不可删除)。
4. zk客户端常见命令:
ls :查看结点的信息 (只能是绝对路径!)
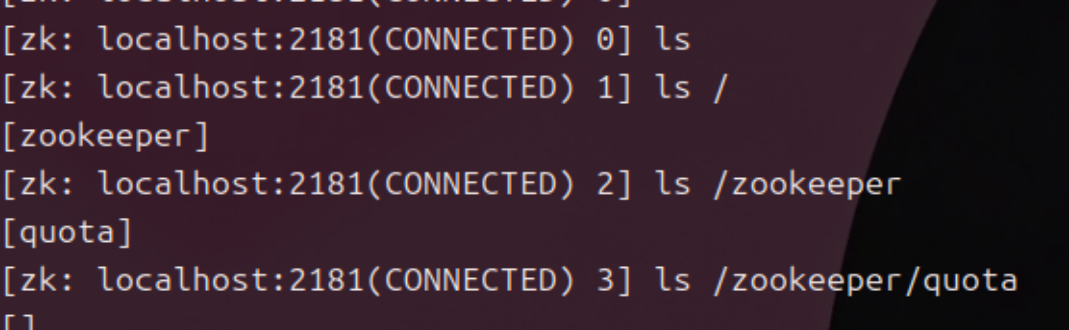
get :获取结点的详细信息
create : 创建结点

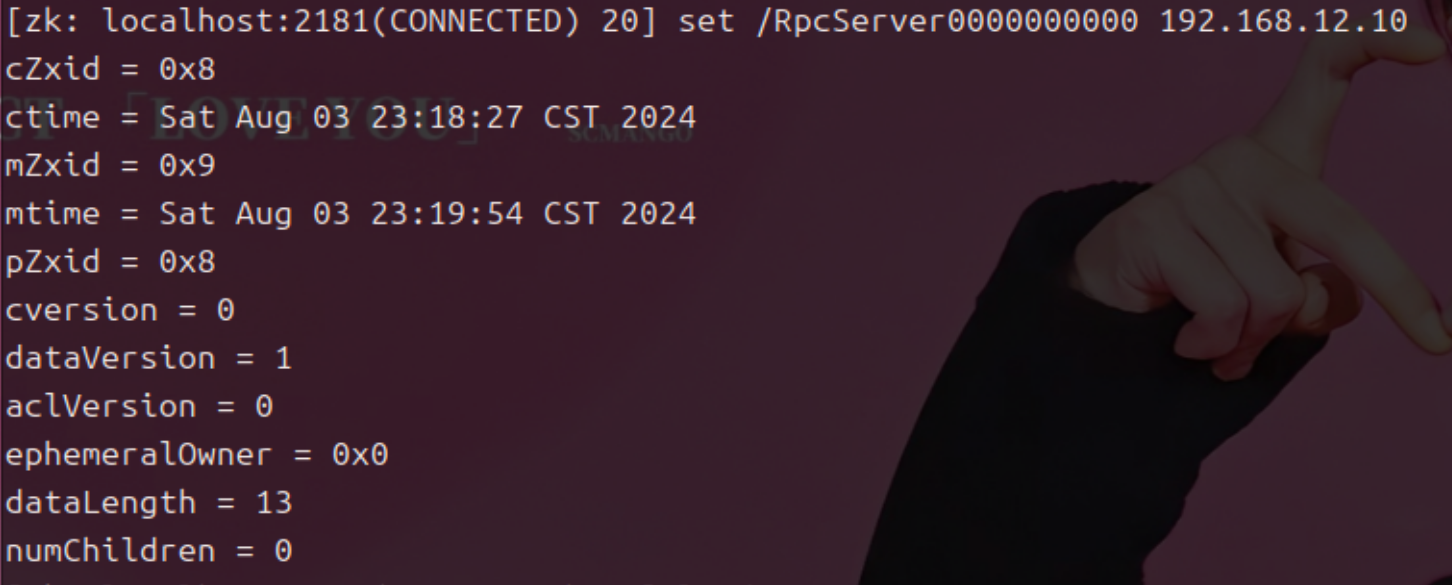
set :向结点内写入数据
delete :删除结点(当该节点含有子节点时无法删除)

5. 原生 zkClient API 存在的问题:
zookeeper原生提供了c和ava的客户端编程接口,但是使用起来相对复杂,几个弱点:
- 不会自动发送心跳消息:即使注册的结点依然正常,由于Session超时依然有可能被删除结点
- 设置监听watcher只能是一次性的:每次触发后需要重复设置,造成大量重复操作
- znode节点只存储简单的byte字节数组,如果存储对象,需要自己转换对象生成字节数组
6. Zookeeper作用:
- master节点选举, 主节点down掉后, 从节点就会接手工作, 并且保证这个节点是唯一的,这也就是所谓首脑模式,从而保证我们集群是高可用的
- 统一配置文件管理, 即只需要部署一台服务器, 则可以把相同的配置文件同步更新到其他所有服务器, 此操作在云计算中用的特别多(例如修改了redis统一配置)
- 数据发布与订阅, 类似消息队列MQ
- 分布式锁,分布式环境中不同进程之间争夺资源,类似于多进程中的锁
- 集群管理, 保证集群中数据的强一致性
7. Zookeeper的特性:
- 一致性: 数据一致性, 数据按照顺序分批入库
- 原子性: 事务要么成功要么失败
- 单一视图: 客户端连接集群中的任意zk节点, 数据都是一致的
- 可靠性:每次对zk的操作状态都会保存在服务端
- 实时性: 客户端可以读取到zk服务端的最新数据















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









