






此文档连接MySQL,TDengine(时序库)
Maven:
<!-- TDengine 依赖 -->
<dependency>
<groupId>com.taosdata.jdbc</groupId>
<artifactId>taos-jdbcdriver</artifactId>
<version>3.2.4</version>
</dependency>
<!--Druid 方便控制台查看-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.16</version>
</dependency>
<!-- hutool工具 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.5</version>
</dependency>
<!-- mybatis plus 动态数据源 多数据源 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
YML配置:
spring:
lifecycle:
timeout-per-shutdown-phase: 30s #设置缓冲时间 默认也是30s
# Mysql配置
datasource:
druid:
# 接下来(one,two)其实就都是自定义配置了,springBoot是识别不了的(当然你也可以另起其它行,到其它位置),我们需要将这些配置映射到对应的类上,springBoot不会帮我们做
one:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xxx.xxx.xxx.xxx:3306/xxx?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
username: root
password: xxxx
type: com.alibaba.druid.pool.DruidDataSource
name: mysqlDataSource # 在druid 内数据源的名称
# springboot2.0整合了hikari ,据说这是目前性能最好的java数据库连接池,但是 druid 有控制面板方便查看
# 手动配置数据源
validation-query: SELECT 1 FROM DUAL # 连接是否有效的查询语句
validation-query-timeout: 60000 # 连接是否有效的查询超时时间
# 建议 连接数 = ((核心数 * 2) + 有效磁盘数)
initial-size: 40 #初始化时建立物理连接的个数,初始化发生在显示调用 init 方法,或者第一次 getConnection 时
min-idle: 40 # 最小连接池数量
max-active: 100 #最大连接池数量
test-on-borrow: false #申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-return: false #归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
time-between-eviction-runs-millis: 60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
min-evictable-idle-time-millis: 300000 # 配置一个连接在池中最小生存的时间,单位是毫秒
two:
driver-class-name: com.taosdata.jdbc.TSDBDriver
# 这里指定了具体的数据库 需要注意,
# 如果换成不指定具体数据库名称 jdbc:TAOS://192.168.172.129:6030?charset=UTF-8&locale=en_US.UTF-8&timezone=UTC-8 则在sql中使用必须要指定数据库的名称 dba.table_b
url: jdbc:TAOS://xxx.xxx.xxx.xxx:6041/dev?charset=UTF-8&locale=en_US.UTF-8&timezone=UTC-8
username: root
password: xxxx
type: com.alibaba.druid.pool.DruidDataSource
name: tdengineDataSource # 在druid 内数据源的名称
# springboot2.0整合了hikari ,据说这是目前性能最好的java数据库连接池,但是 druid 有控制面板方便查看
# 手动配置数据源
validation-query: select server_status() # 连接是否有效的查询语句
validation-query-timeout: 60000 # 连接是否有效的查询超时时间
# 建议 连接数 = ((核心数 * 2) + 有效磁盘数)
# initial-size 该属性只有在调用接口初始化init方法的时候才会建立连接
# initial-size: 10 #初始化时建立物理连接的个数,初始化发生在显示调用 init 方法,或者第一次 getConnection 时
min-idle: 10 # 最小连接池数量
max-active: 20 #最大连接池数量
test-on-borrow: false #申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-return: false #归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
time-between-eviction-runs-millis: 60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
min-evictable-idle-time-millis: 300000 # 配置一个连接在池中最小生存的时间,单位是毫秒
配置类:
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Primary;
import org.springframework.stereotype.Component;
import javax.servlet.Filter;
import javax.sql.DataSource;
/**
* 多数据源配置
*/
@Component
@Slf4j
public class DataSourceConfig {
public static final String MYSQL_DATA_SOURCE = "mysqlDataSource";
public static final String TDENGINE_DATA_SOURCE = "tdengineDataSource";
/**
* http://127.0.0.1:8090/druid/index.html
* 配置Druid的监控视图
*
* @return
*/
@Bean
public ServletRegistrationBean<StatViewServlet> druidStatViewServlet() {
ServletRegistrationBean<StatViewServlet> registrationBean =
new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
// 配置Druid监控页面的登录用户名和密码
registrationBean.addInitParameter("loginUsername", "admin");
registrationBean.addInitParameter("loginPassword", "123456");
// 设置 IP 白名单,允许访问的 IP,多个 IP 用逗号分隔
registrationBean.addInitParameter("allow", "127.0.0.1");
// 设置 IP 黑名单,拒绝访问的 IP,多个 IP 用逗号分隔(当 IP 在黑名单中同时又在白名单中时,优先于白名单)
// servletRegistrationBean.addInitParameter("deny", "192.168.1.100");
// 是否能够重置数据
registrationBean.addInitParameter("resetEnable", "false");
return registrationBean;
}
/**
* 配置Druid的WebStatFilter
*
* @return
*/
@Bean
public FilterRegistrationBean<Filter> druidWebStatFilter() {
FilterRegistrationBean<Filter> registrationBean = new FilterRegistrationBean<>();
registrationBean.setFilter(new WebStatFilter());
// 添加过滤规则
registrationBean.addUrlPatterns("/*");
// 配置不拦截的路径
registrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
return registrationBean;
}
/**
* 自动配置的数据源,使用Druid连接池
* druid 会管理这数据源
*
* @return
*/
@Bean(name = MYSQL_DATA_SOURCE)
@Primary
@ConfigurationProperties(prefix = "spring.datasource.druid.one")
public DataSource dataSource() {
return new DruidDataSource();
}
/**
* 手动配置的数据源,也使用Druid连接池
* druid 会管理这数据源
* <p>
* 这里不直接集成tdengine 到 mybatisPlus 的原因有两个
* 1、集成到 mybatisPlus 时需要多数据源,无论是使用dynamic-datasource的方案,还是自己去写,都需要去处理做逻辑代码,可能后期需要版本的维护就又要考虑这个维护
* 2、就是无论这个tdengine 如何发展,它一定会支持 jdbc 的方案,但是可能不会支持 mybatis和 springBoot,
* 3、效率问题
*
* @return
*/
@Bean(name = TDENGINE_DATA_SOURCE)
@ConfigurationProperties(prefix = "spring.datasource.druid.two")
public DataSource customDataSource() {
return new DruidDataSource();
}
}多数据源连接监控:
http://127.0.0.1:8090/druid/datasource.html
MySQL: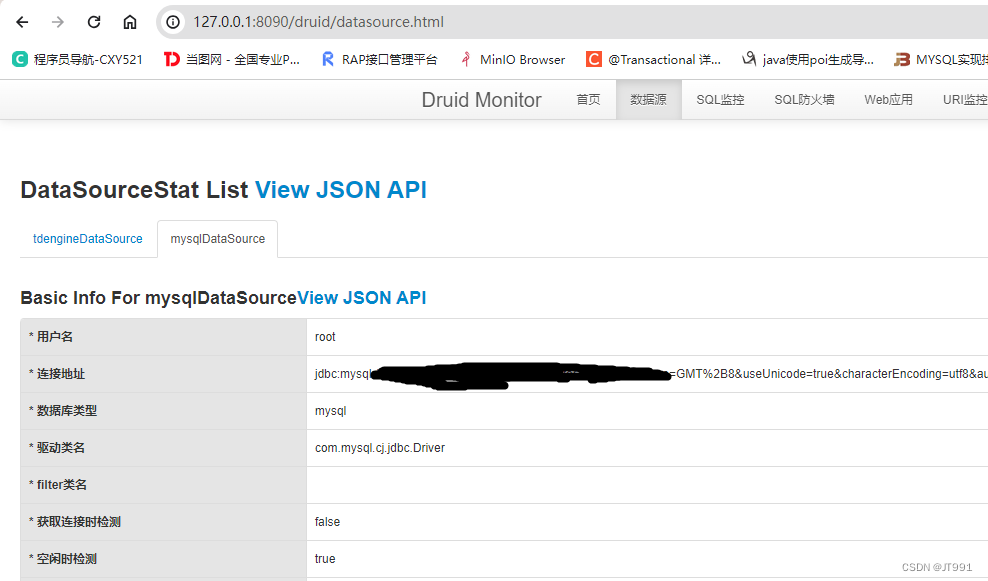
TDengine: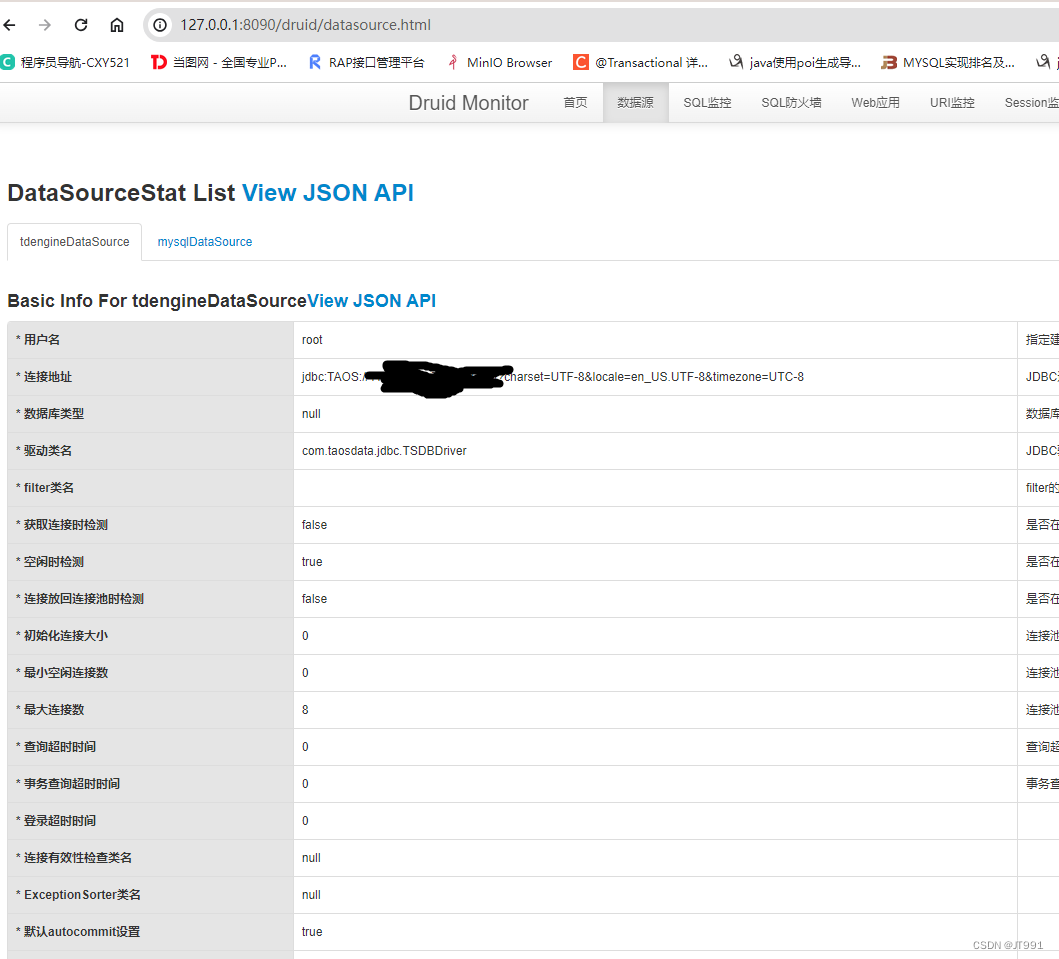
错误解决:
spring cloud项目集成可能会以下错误找不到数据源
### Error querying database. Cause: java.sql.SQLSyntaxErrorException: Table 'xxx.dev' doesn't exist
### The error may exist in file [E:\workspace\xxxxxx\target\classes\mapper\tdengine\DevMapper.xml]
### The error may involve defaultParameterMap
### The error occurred while setting parameters
### SQL: select * from dev;
### Cause: java.sql.SQLSyntaxErrorException: Table 'xxx.dev' doesn't exist
; bad SQL grammar []; nested exception is java.sql.SQLSyntaxErrorException: Table 'xxx.dev' doesn't exist] with root cause
java.sql.SQLSyntaxErrorException: Table 'xxx.dev' doesn't exist需要绑定默认数据源@Primary
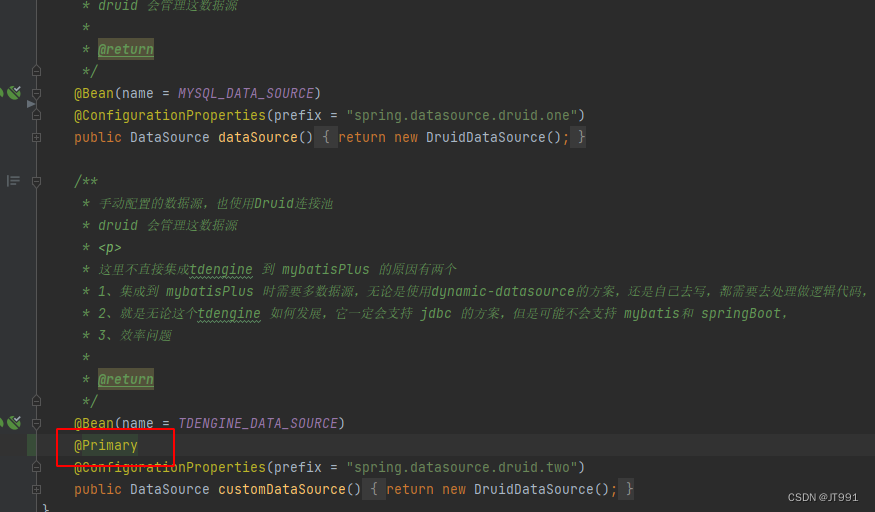
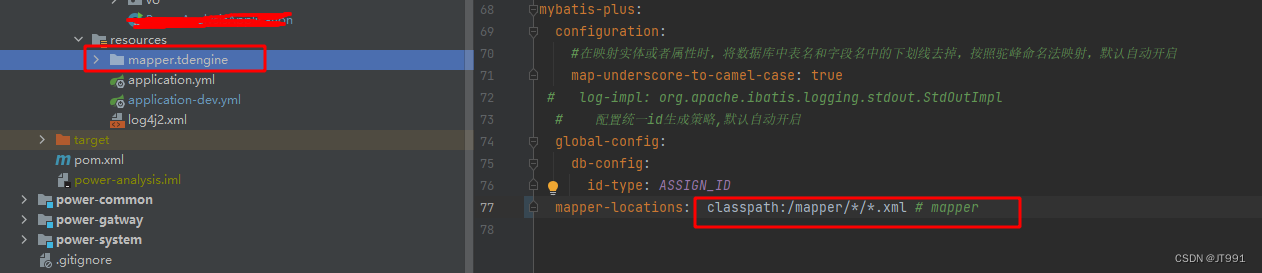
也需要注意mapper的层级















 3554
3554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









