







 本文详细介绍了HDFS集群的启停命令,包括一键脚本和独立进程方式;阐述了HDFS文件系统的基本操作,如创建文件夹、上传下载文件等,并介绍了JetBrains产品中的BigDataTools插件以及如何通过NFS网关将HDFS挂载到本地系统。
本文详细介绍了HDFS集群的启停命令,包括一键脚本和独立进程方式;阐述了HDFS文件系统的基本操作,如创建文件夹、上传下载文件等,并介绍了JetBrains产品中的BigDataTools插件以及如何通过NFS网关将HDFS挂载到本地系统。
目录
前言
Hadoop Distributed File System (HDFS) 是一个分布式文件系统,用于存储和处理大规模数据集。HDFS具有高可扩展性、高容错性和高吞吐量的特点,是Apache Hadoop框架的核心组件之一。
HDFS提供了一个命令行界面(Shell),用于管理和操作文件系统中的文件和目录。使用HDFS的Shell,用户可以执行各种文件系统操作,如创建目录、上传文件、下载文件、删除文件等。
HDFS的Shell操作类似于Linux的命令行操作,用户可以使用一系列命令来完成各种操作。Shell命令包括一些基本的文件系统操作命令,如ls(列出文件和目录)、mkdir(创建目录)、put(上传文件)、get(下载文件)、rm(删除文件)等。此外,HDFS的Shell还提供了一些其他有用的命令,如chown(修改文件所有者)、chgrp(修改文件所属组)、chmod(修改文件权限)等。
用户可以通过在终端中输入hdfs命令来启动HDFS的Shell。在Shell中,用户可以使用上述命令来管理和操作HDFS文件系统中的文件和目录。通过简单的命令,用户可以轻松地完成HDFS文件系统的常见操作。
HDFS的Shell操作简单方便,适用于对文件进行基本的管理和操作。对于更复杂的操作,如数据分析和处理,用户通常会使用其他工具,如Hadoop MapReduce或Spark等。但对于一些简单的文件系统操作,HDFS的Shell是十分有用的。
一、HDFS集群启停命令
1.一键启停脚本可用
- $HADOOP_HOME/sbin/strat-dfs.sh
- $HADOOP_HOME/sbin/stop.sh
由于在前置设置中已经配置好了环境,所以只需要执行红色代码即可。
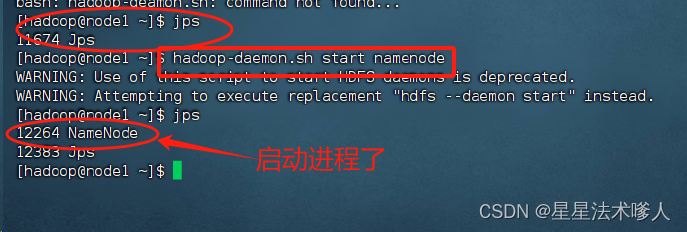
2.独立进程启停可用
- $HADOOP_HOME/sbin/hadoop-deamon.sh
- $HADOOP_HOME/sbin/hdfs --daemon

二、文件系统操作命令
关于HDFS文件系统的操作命令,Hadoop提供了2套命令体系
- hadoop命令(老版本用法),用法:hadoop fs [generic options]
- hdfs命令(新版本用法),用法:hdfs dfs [generic options]
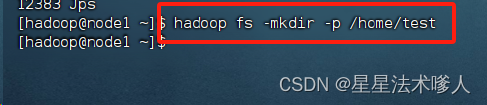
1、创建文件夹
- hadoop fs -mkdir [-p] <path> .......
- hdfs dfs -mkdir [-p] <path>......
path为待创建的目录
-p选项的行为与Linux mkdir -p一致,它会沿着路径创建父目录
2、查看指定目录下内容
- hadoop fs -ls [-h] [-R] <path> .......
- hdfs dfs -ls [-h] [-R] <path>......
-h人性化显示文件size
-R递归查看指定目录及其子目录
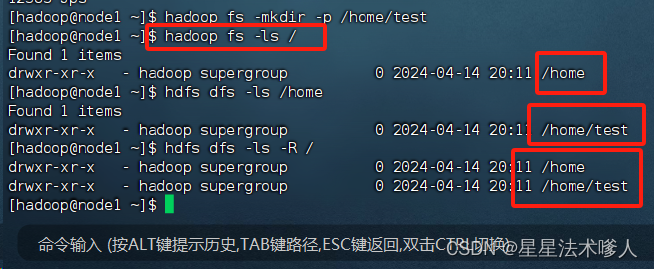
可以查看到我们之前所创建的文件夹。
3、上传文件到HDFS指定目录下
- hadoop fs -put [-f] [-p] <localsrc> ....... <dst>
- hdfs dfs -put [-f] [-p] <localsrc> ....... <dst>
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限
localsrc 本地文件系统(客户端所在机器)
dst 目标文件系统(HDFS)

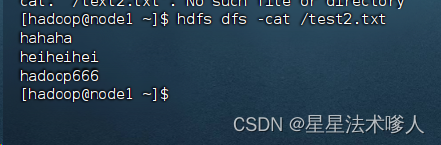
4、查看HDFS文件内容
读取指定文件全部内容,显示在标准输出控制台。
- hadoop fs -cat <src> .......
- hdfs dfs -cat <src> .......
读取大文件可以使用管道符配合more
- hadoop fs -cat <src> | more
- hdfs dfs -cat <src> | more
5、下载HDFS文件
下载文件到本地文件系统指定目录,localdst必须是目录
- hadoop fs -get [-f] [-p] <src> ....... <localdst>
- hdfs dfs -get [-f] [-p] <src> ....... <localdst>
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限

6、拷贝HDFS文件
- hadoop fs -cp [-f] <src> ....... <dst>
- hdfs dfs -cp [-f] <src> ....... <dst>

将文件test.txt复制到/home目录下。
7、追加数据到HDFS文件中
- hadoop fs -appendToFile <localsrc> ....... <dst>
- hdfs dfs -appendToFile <localsrc> ....... <dst>
将所有给定本地文件的内容追加到给定dst文件。
dst如果文件不存在,将创建该文件。
如果<localSrc>为-,则输入为从标准输入中读取。

8、HDFS数据移动操作
- hadoop fs -mv <src> ....... <dst>
- hdfs dfs -mv <src> ....... <dst>
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称。
9、HDFS数据删除
- hadoop fs -rm -r [-skipTrash] URI [URI ......]
- hdfs dfs -rm -r [-skipTrash] URI [URI ......]
删除指定路径的文件或文件夹
-skipTrash 跳过回收站,直接删除。

<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>! HDFS WEB浏览
除了使用命令操作HDFS文件系统外,在HDFS的WEB UI 上也可以查看到HDFS系统的内容。
http://node1:9870
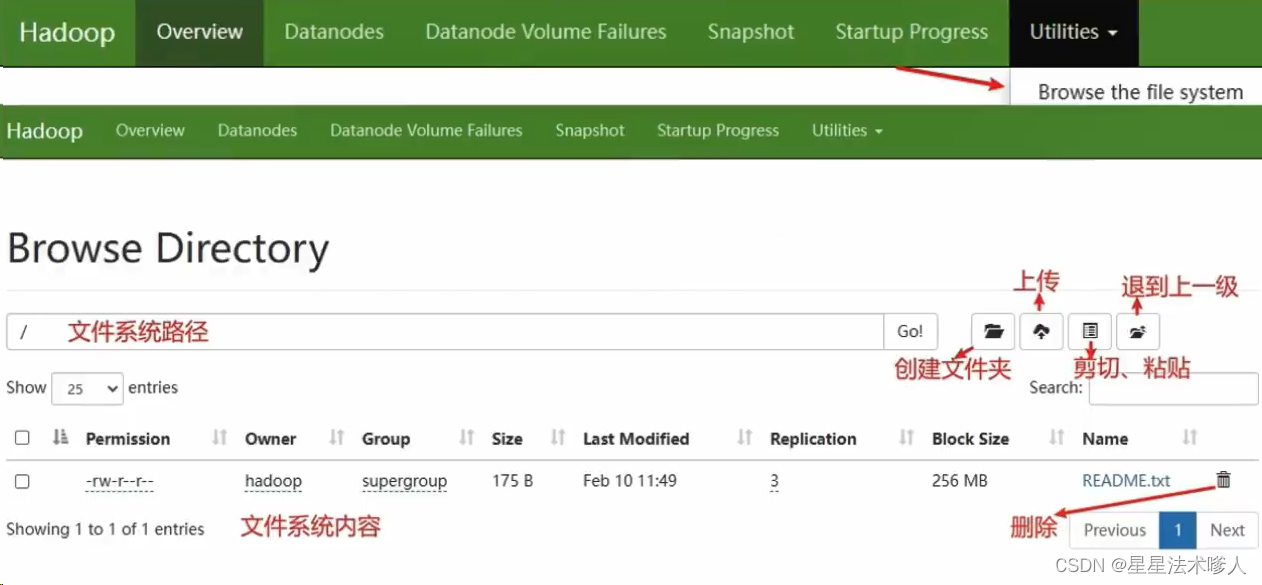
使用WEB浏览操作文件系统,一般会遇到权限问题
这是因为WEB浏览器中是以用户(dr,who)登录的,其只有只读权限,多数操作是做不了的。如果需要以特权用户在浏览器中进行操作,需要配置core-site.xml并重启集群,但是,不推荐这样做。
补充:修改权限
在HDFS中,可以使用和Linux一样的授权语句,即chown和chmod
- 修改所属用户和组:
root:用户 supergroup:组
hadoop fs -chown [-R] root:supergroup /xxx.txt
hdfs dfs -chown [-R] root:root /xxx.txt
- 修改权限:
hadoop fs -chown [-R] 777 /xxx.txt
hdfs dfs -chown [-R] 777 /xxx.txt
三、HDFS客户端 - jetbrians产品插件
1.Big Data Tools插件
在jetbrains的产品中,均可以安装插件,其中:Big Data Tools插件可以帮助我们方便的操作HDFS,比如:
- Intellij IDEA(java IDE)
- pyCharm(Python IDE)
- DataGrip(SQL IDE)
均可以支持Bigdata Tools插件
设置-> plugins(插件)-> Marketplace(市场),搜索Big Data Tools

2、配置Windows
需要对Windows系统做一些基础设置,配合插件使用
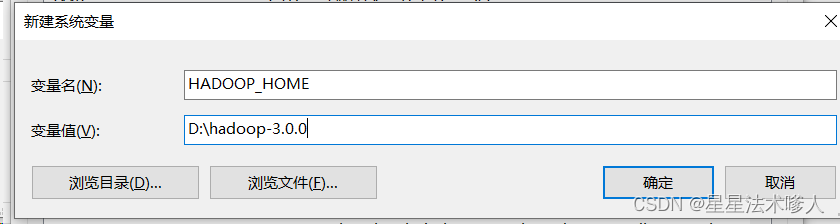
- 解压Hadoop安装包到Windows系统,如解压到:D:\hadoop-3.0.0
- 设置$HADOOP-HOME环境变量指向:D:\hadoop-3.0.0
- 下载
- hadoop.dll(https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/hadoop.dll)
- winutils.exe(https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/winutils.exe)
- 将hadoop.dll和winutils.exe放入$HADOOP_HOME/bin中

3、配置Big Data Tools插件
打开插件

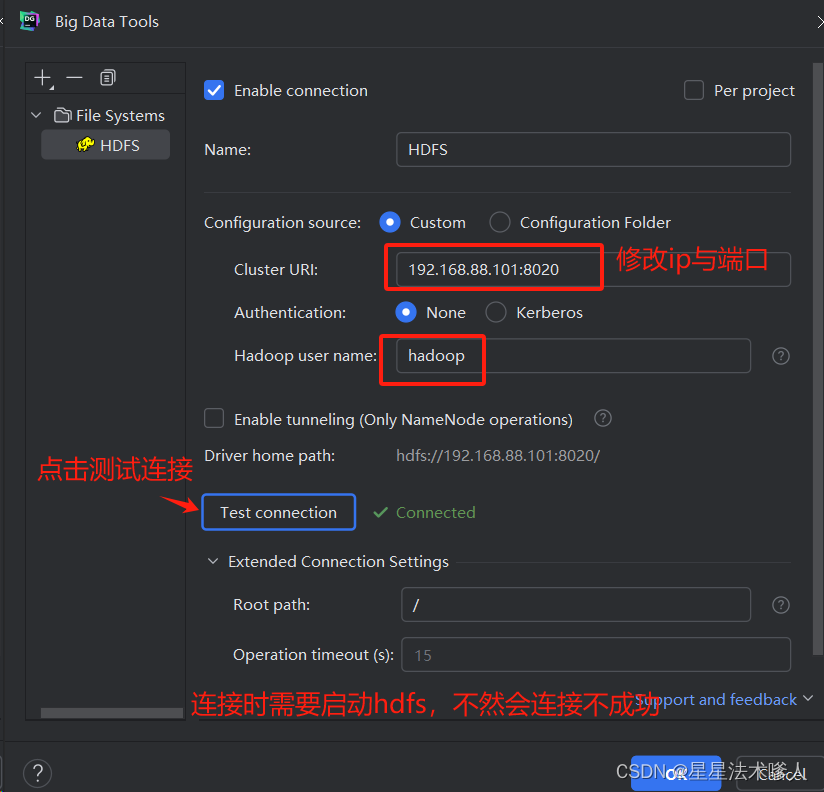
点击🆗,连接成功,如果hdfs里没有文件会在连接的时候一直转圈圈,可以先在hdfs里创建一个文件。
可以从磁盘上传文件到hdfs
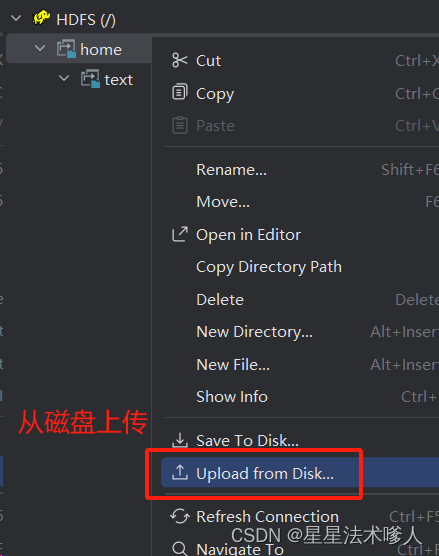
如果上述方法连接不成功,可以使用以下方法。
需要在虚拟机上打包配置好的Hadoop配置文件,将Windows中hadoop配置环境中的/etc目录下全部换成打包好的文件。
cd /export/server/hadoop/etc/hadoop
tar -zcvf etc.tar.gz *
sz etc.tar.gz 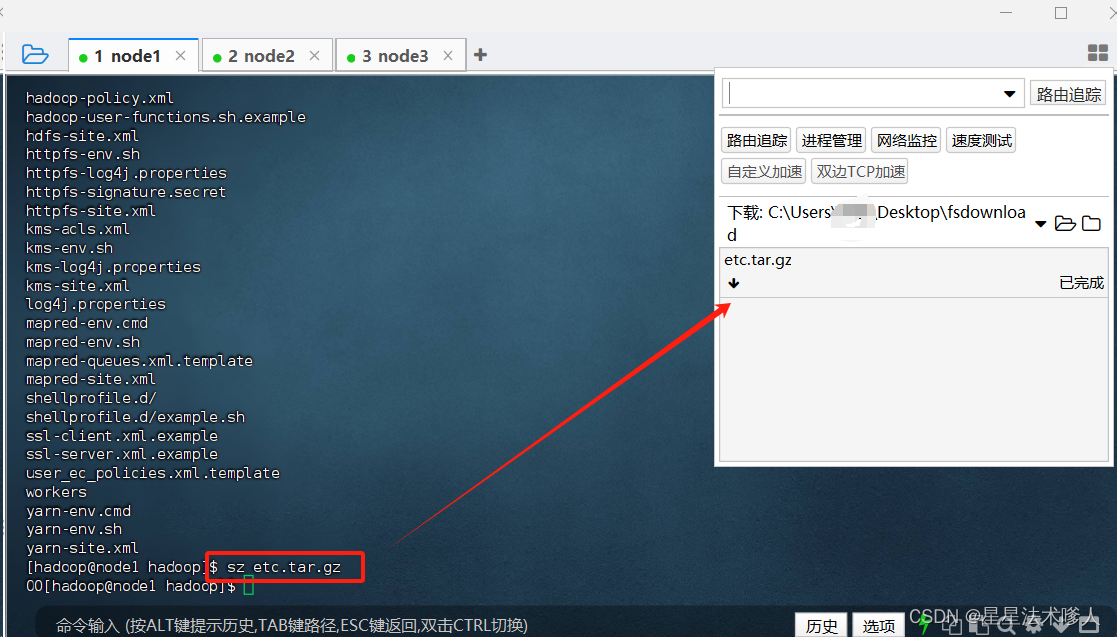
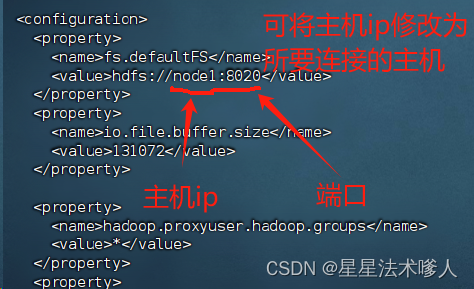
此方法就是去找到配置好了的core-site.xml文件,将主机ip修改为要连接的ip即可,因为在前置配置中已经在hosts文件上,配置好了主机映射,所以此处用node1代替。

四、HDFS客户端 - NFS
4.1使用NFS网关功能将HDFS挂载到本地系统
4.1.1、HDFS NFS Gateway
HDFS提供了基于NFS(Network File System)的插件,可以对外提供NFS网关,供其他系统挂载使用。NFS网关支持NFSv3,并允许将HDFS作为客户机本地文件的一部分挂载,现在支持:
- 上传、下载、删除、追加内容。
4.1.2、配置NFS
配置HDFS需要配置如下内容:
- core-site.xml,新增配置项以及hdfs-site.xml,新增配置项
- 开启portmap、nfs3两个新进程
在node1进行如下操作:在/export/server/hadoop/etc/hadoop/下
1.在core-site.xml内新增如下两项
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>- 项目:hadoop.proxyuser.hadoop.groups 值:*
允许hadoop用户代理任何其他用户组
- 项目:hadoop.proxyuser.hadoop.hosts 值:*
允许代理任何服务器的请求
2、在hdfs-site.xml中新增如下项
<property>
<name>nfs.superuser</name>
<value>hadoop</value>
</property>
<property>
<name>nfs.dump.dir</name>
<value>/tmp/.hdfs-nfs</value>
</property>
<property>
<name>nfs.exports.allowed.hosts</name>
<value>192.168.88.1 rw</value>
</property>- nfs.suerpser:NFS操作HDFS系统,所使用的超级用户(hdfs的启动用户为超级用户)
- nfs.dump.dir:NFS接收数据上传时使用的临时目录
- nfs.export.allowed.hosts:NFS允许连接的客户端IP和权限,rw表示只读,IP整体或部分可以以*代替。
4.1.3、启用NFS功能
1、将配置好将配置好的core-site.xml和hdfs-site.xml分发到node2和node3.

2、重启Hadoop HDFS集群(先stop-dfs.sh,后start-dfs.sh)
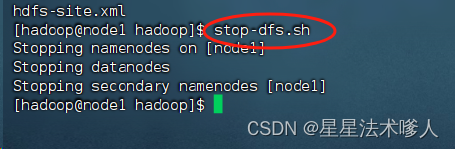
3、停止系统的NFS相关进程,(必须以root执行):
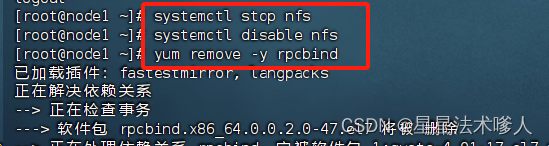
a).systemctlstop nfs; systemctldisable nfs 关闭系统nfs并关闭其开机自启
b).yum remove-yrpcbind 卸载系统自带rpcbind(因为要使用hdfs自带的rpcbind功能)
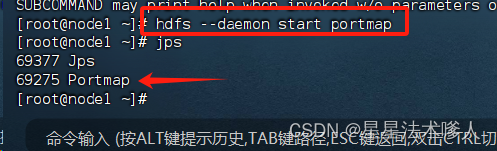
4、启动portmap(HDFS自带的rpcbind功能)(必须以root执行):
hdfs --daemon start portmap
5、启动nfs(HDFS自带的nfs功能)(必须以hadoop用户执行):
hdfs--daemon start nfs3

4.1.4、检查NFS是否正常
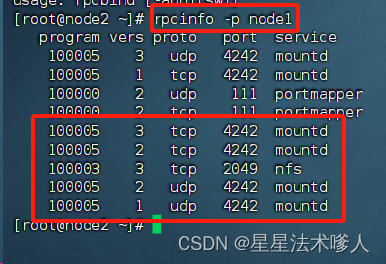
以下操作在node2或node3执行(因为node1卸载了rpcbind,缺少了必要的2个命令)
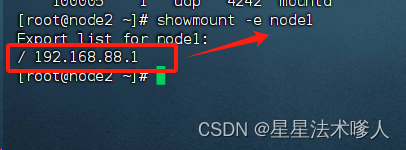
- 执行:rpcinfo -p node1,正常输出如下:有mountd和nfs出现
- 执行:showmount -e node1,可以看到 /192.168.88.1
4.1.5、在windows挂载HDFS文件系统
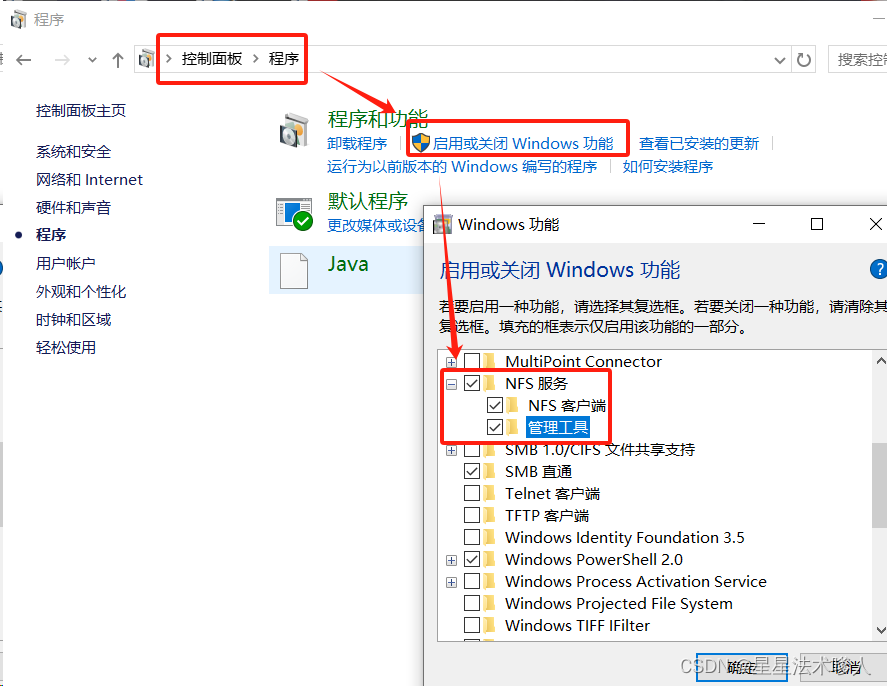
1、开启Windows的NFS功能
此功能需要专业版,如果是家庭版windows需要升级为专业版
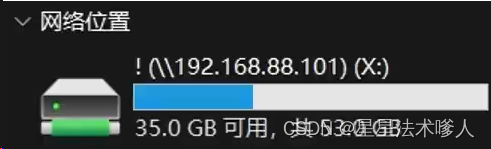
2、在Windows命令提示符(CMD)内输入:net use X:\\192.168.88.101\!
3、完成后即可在文件管理器中看到盘符为X的网络位置
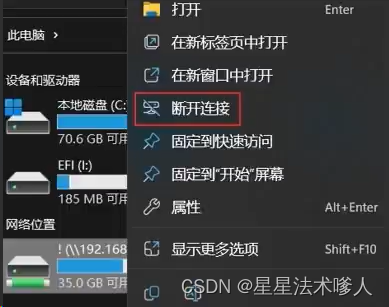
4、点击右键客户断开连接















 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









