






环境变量
环境变量是什么?
为什么我们自己写的可执行程序在Linux下就需要加./才能运行,但是指令却不需要(指令本身也是可执行程序)
我们可以自己配置自己的环境变量吗?
这是我在学习环境变量之前的三个问题,本篇对于环境变量的叙述也是和这三个问题息息相关的。
但是今天提到的PATH仅仅是一个代表,不是所有的环境变量。
首先认识一下一个指令:echo $PATH
这是在我的默认的未经配置的环境变量,当我在输入ls这个指令之后,就会在这些路径中寻找是否有ls这个可执行程序

创建和删除环境变量
创建环境变量到PATH有两种方法,一种是将可执行文件添加到环境变量的路径下;还有一种就是将可执行程序的文件路径添加到环境变量中。
第一种方法是不推荐的,因为有些时候我们自己写的程序不经过测试查bug的话可能会有一些问题,所以我们一般使用第二种方法:export PATH=$PATH:路径
删除环境变量,如果是自己手动在命令行上对环境变量的修改,一般只在本次对话中被修改,一旦退出登录就无效了。
和环境变量相关的指令:
1.echo:显示某个环境变量值
2.export:设置一个新的环境变量
3.env:显示所有环境变量
4.unset:清除环境变量
5.set:显示本地定义的shell环境变量和环境变量
使用unset可以删除环境变量
通过代码获取环境变量
首先大家思考一个问题:main函数可以带参数吗?如果可以,可以带几个参数呢?
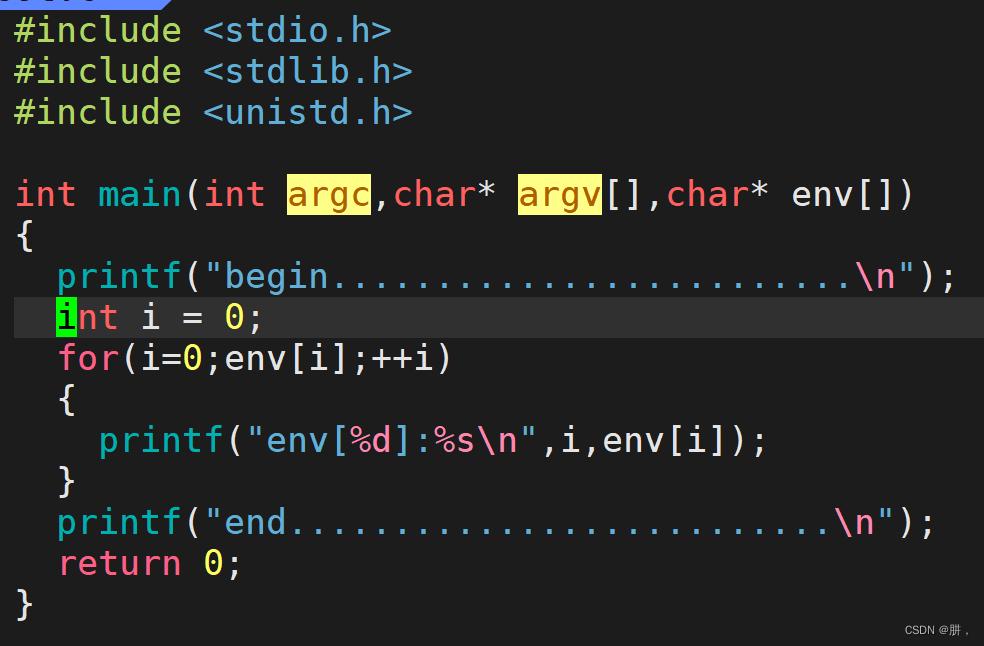
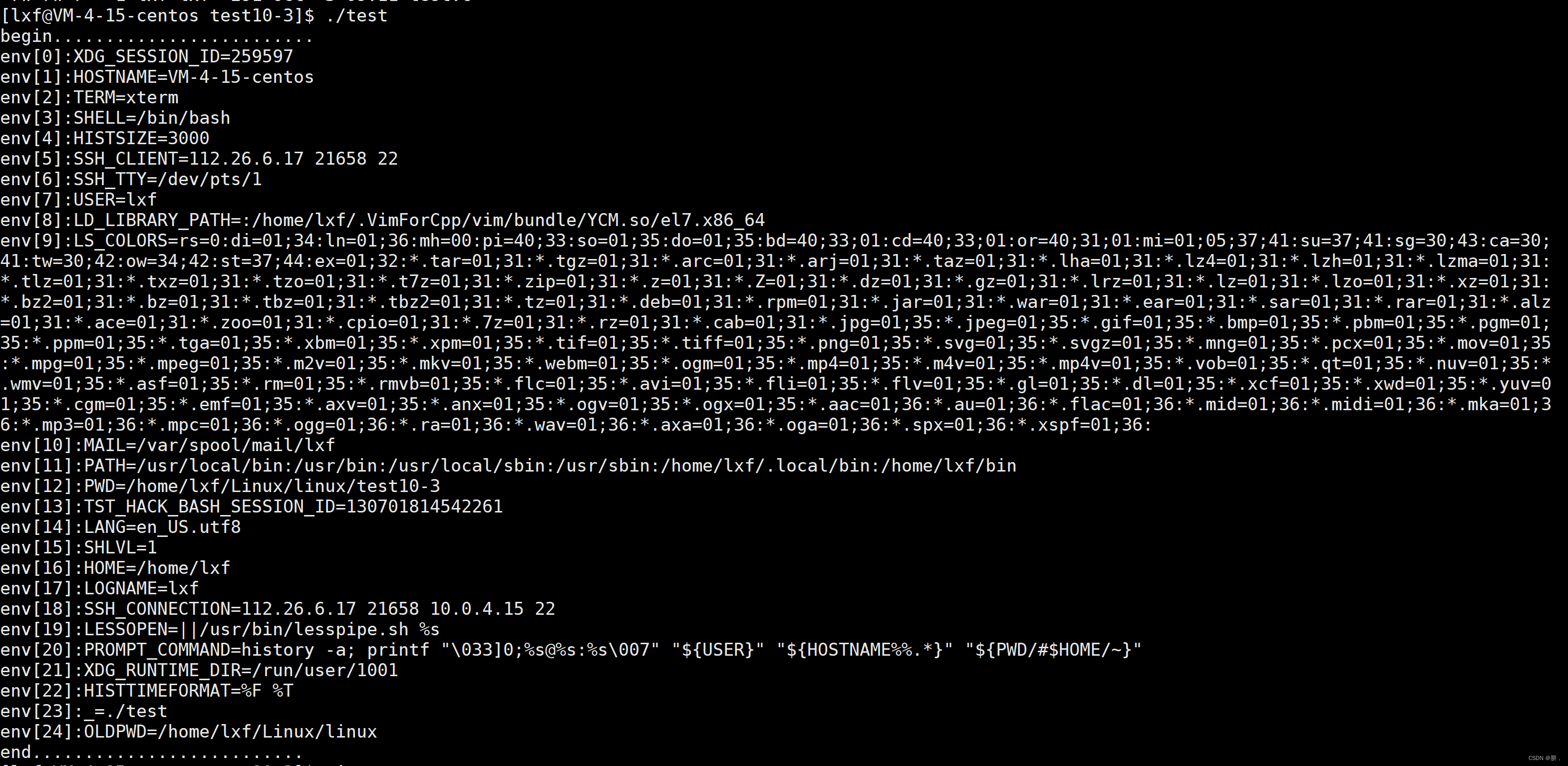
main函数有三个参数,先来介绍最后一个参数env,首先通过参数类型可以知道这是一个指针数组,里面存放的值就是系统传递给进程的环境变量,通过下标可以进行访问,所以函数打印的结果就是:
也可以通过函数getenv来获取到环境变量
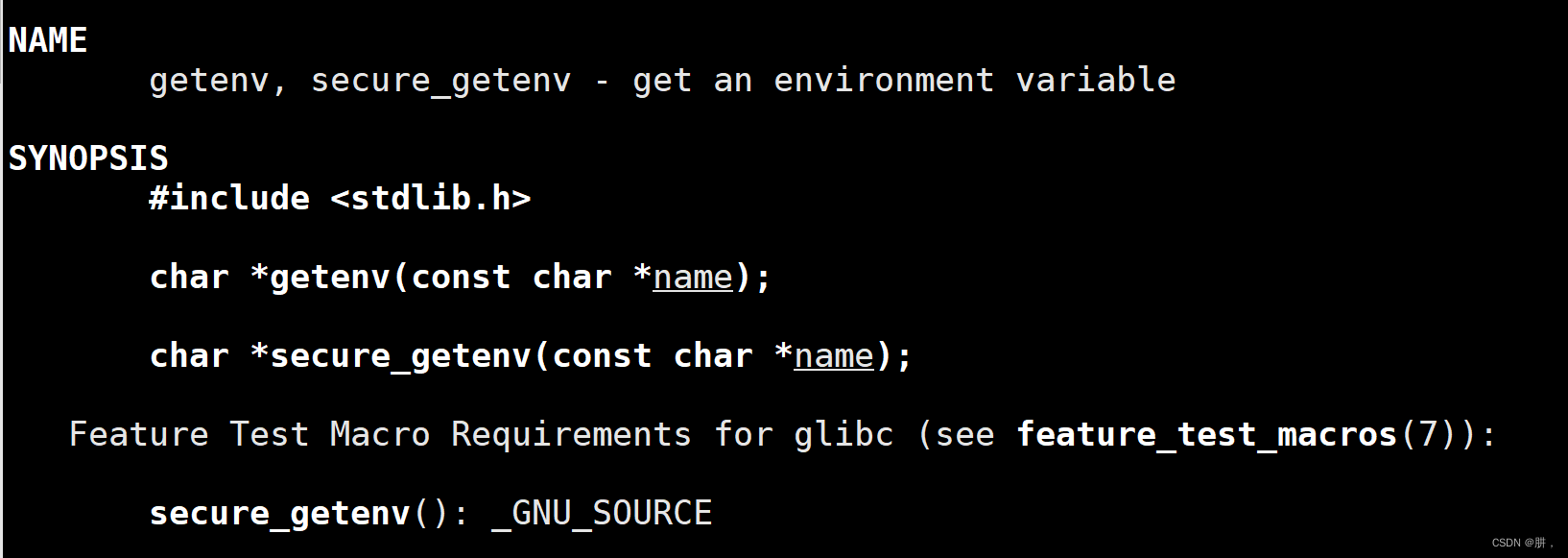
参数name就是环境变量,可以直接找到对应的环境变量的内容。
那么这么多的环境变量究竟是从哪儿来的呢?
环境变量是从父进程那里进程下来的,默认所有的环境变量都可以被子进程继承。所以环境变量具有全局属性!
其实本省在bash层面,创建一个变量
val = 5;
export val = 5;
在bash层面的变量之前加export就可以将变量变为环境变量。
命令行参数
main函数还有两个参数,分别是argc和argv
看一下运行结果:
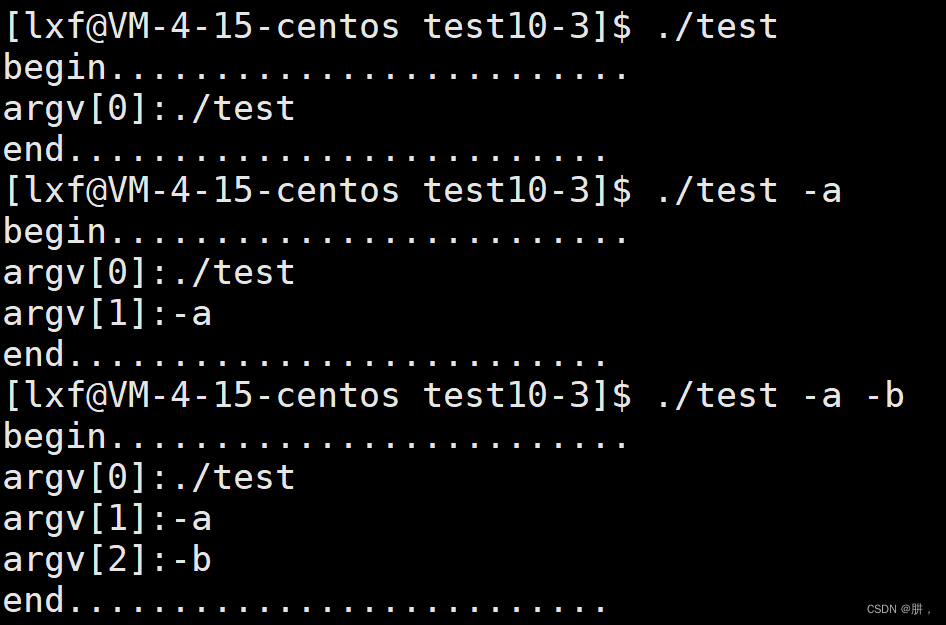
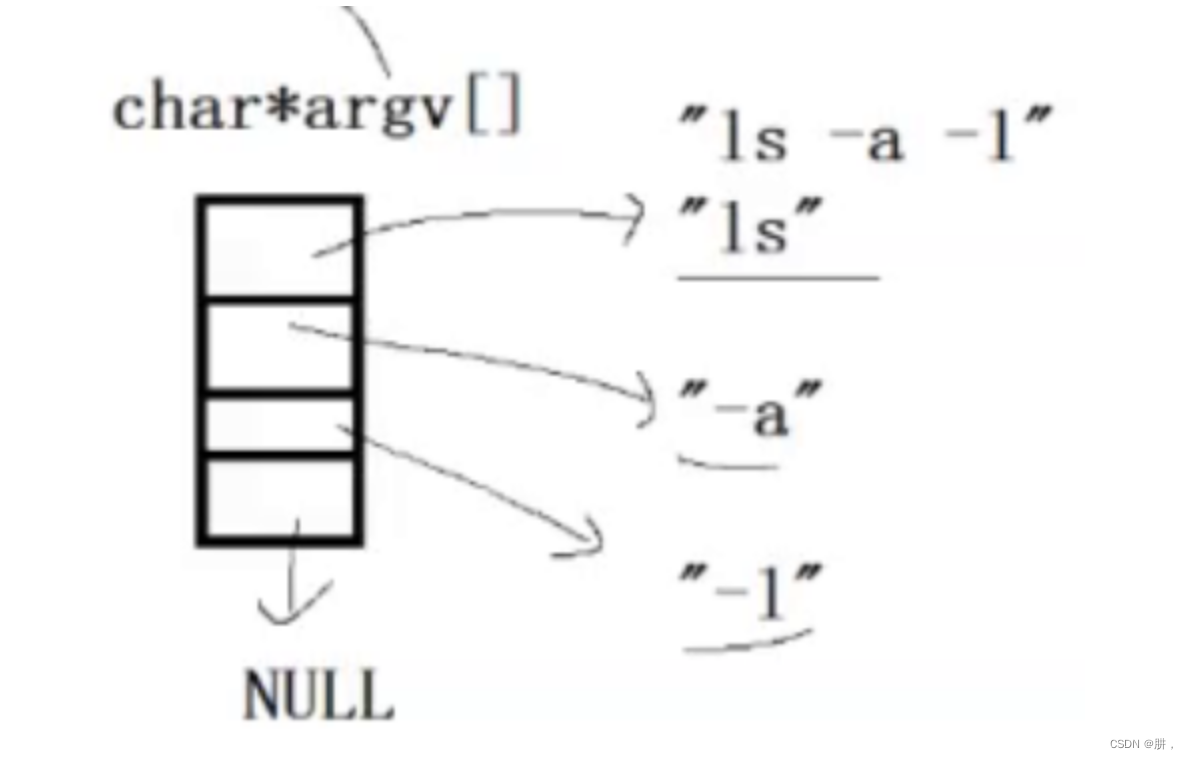
argv就指向一个个传递进来的参数,而argc就决定了argv这个数组有多大。
所以就可以理解,所谓的命令行参数,就是你在Linux的bash下输入的一个一个的参数和选项,父进程先拿到这个参数之后,然后回继承给子进程去执行。
讲到这里,我们总结一下:
什么是环境变量?
环境变量一般是指在操作系统中用来指定操作系统运行环境的一些参数
环境变量通常是具有全局属性的
进程控制
fork深度剖析
之前我们提过fork这个函数,它可以用来创建子进程,有两个返回值,子进程返回0,父进程返回子进程的pid,然后可以用if,else分别让父子进程执行不同的代码。
子进程回继承父进程的一些东西这个大家都知道,而fork创建子进程和父进程共享代码,创建好子进程之后也会共享创建之后的代码,但是如果是数据呢?之前创建的数据是不可以共享的,因为要保证进程的独立性,但是并不是所有的数据都会被修改,如果直接一股脑进行拷贝就会导致造成时间和空间的浪费,所以就有了写时拷贝。
因为有写时拷贝的存在,才使得父子进程得以彻底分离,完成了进程独立的技术保证。写时拷贝是一种延时申请技术,可以提高内存的整体利用效率。为什么延时申请就可以提高利用率?因为这样的话只有当有内存需求的时候才会分配内存就防止了先开辟内存但是却不用的问题。(操作系统有很多设计很巧妙的地方,值得学习)
进程终止
进程终止时,操作系统做了什么 ?
要释放进程申请的相关内核数据结构和对应的数据和代码
进程终止的方式是什么?
- 代码跑完了,结果正确
- 代码跑完了,结果错误
- 代码没跑完程序就崩溃了
其实我们一般写的main函数的返回值,大部分都返回了0,实际上这是不妥的,main函数的返回值本质上是进程的退出码,用来评判该进程的执行结果,而这个退出码可以用来判断程序运行结果的正确与否(前提是程序并没有崩溃),好的程序搭配有经验的程序员可以直接通过进程的退出码判断出代码的问题所在。
查看最近一次进程执行完的退出码指令:echo $?
有一个问题:为什么程序执行结果正确只有一个特定的退出码,但是执行错误却有很多退出码呢?
其实很简单,因为程序执行正确只有一种情况,但是执行错误却可能有很多种情况,所以有不同的退出码进行区分,可以判断不同的错误原因。
当然也可以使用库中的错误码:
//查看错误码
#include<stdio.h>
#include<string.h>
int main()
{
int number=0;
for(number=0;number<150;number++)
{
printf("%d : %s\n",number,strerror(number));
}
return 0;
}
程序崩溃的时候,退出码毫无意义。
进程退出
只有main函数的返回值代表着进程的终止,但是其他函数的返回值是只是函数的返回值。那么如何在函数中就可以退出进程呢?
这里介绍两个函数 exit (int status) 和 _exit (int status) 函数的头文件为是stdlib.h
exit()在任意地方调用,都表示直接终止进程,函数的参数表示退出码,exit()在调用的时候会有冲刷缓冲区,关闭流等的一些操作。
void test()
{
printf("hello,world");
sleep(3);
exit(1);
}
上面这段代码是可以将hello,world打印出来的。
_exit(int status)是一个系统调用接口,和exit功能相似,但是区别在于它退出进程之前不会执行冲刷缓冲区,关闭流等一系列操作。exit底层调用的就是_exit(),所以也可以得出一个重要的结论:缓冲区的维护不是发生在操作系统中,是C标准库为我们维护的。
进程等待
为什么要进行进程等待?
如果父进程不等待子进程,那么子进程昨晚自己的工作之后需要父进程对其回收,而父进程忙着做其他的事情,就会使子进程变成僵尸进程,父进程通过等待的方式,回收子资源,获取子进程退出的信息。
如何等待?
进程等待涉及到两个函数:wait()和waitpid()
//wait的函数原型
#include <sys/types.h>
#include <wait.h>
int wait(int* status);
//waitpid的函数原型
#include <sys/type.h>
#include <wait.h>
pid_t waitpid(pid_t pid,int* status,int options);
等待方式也分为阻塞等待和非阻塞等待。
wait()的参数一般会设置为NULL,父进程调用wait,会阻塞等待子进程发生变化之后再继续。当然有人会问wait的这个参数是干什么用的,这是一个int*类型的指针,可以用于记录进程退出的一些情况,但是一般我们只希望将这个僵尸进程杀掉而不关心是如何杀掉的,所以也就设置为NULL。
如果调用成功,函数会返回子进程的pid,如果调用失败(没有可用于回收的子进程)就返回-1。
waitpid()这个函数有三个参数
1.pid
参数pid为等待的进程的pid但是情况也有很多种:
| 参数 | 说明 |
|---|---|
| pid == -1 | 任意一个子进程 |
| pid > 0 | 等待进程号为pid的进程 |
实际上这个参数还可以小于-1或等于0,这里不多赘述。
2.status
同wait的参数一样,status用于保存子进程的状态信息,一般会在调用函数之前创建一个变量,然后将变量的地址作为参数传入函数中。这个变量被修改之后包含了很多的信息。Linux提供了一些宏来解析这些信息。

3.options
options可以确定等待的方式,阻塞等待还是非阻塞等待。这里提一下阻塞等待和非阻塞等待:
阻塞等待是将进程挂起,在等待期间不可以做其他的事情,只能一直等待子进程被杀掉之后才能执行后序的代码,和wait一样。但是非阻塞等待是在等待期间,父进程可以做自己的事情,父进程可以检测一下子进程的状态,看看子进程是否需要回收,之后继续做自己的事情。
| 值 | 含义 |
|---|---|
| WNOHANG | 非阻塞等待返回值为0 |
| 0 | 阻塞等待,知道子进程的状态发生变化 |
| WUNTRACED | 由pid指定的任意子进程已经被暂停,自暂停一来还未其状态还未报告过,则返回其状态 |
进程等待实际上是访问了子进程的PCB结构体数据,wait和waitpid可以让进程的退出具有一定的顺序性。
进程程序替换
如果一个进程运行起来,我们想让代码执行到一定位置就进行程序替换,去运行其他文件下的可执行程序,这看起来很荒谬,但是通过系统接口,是可以实现的。
先来说一下进程替换的原理:
进程替换就是先找到目标程序,之后调用exec函数,将用户空间代码和数据全部进行替换,替换成新程序的,所以在替换位置之后,原先的代码不会执行,而是去执行被替换进来程序的代码。
这里有六个exec开头的函数:
#include <unistd.h>
int execel(const char* path,const char*arg,...);
int execlp(const char* file,const char*arg,...);
int execle(const char* path,const char*arg,...,char* const envp[]);
int execv(const char* path,const char*argv[]);
int execvp(const char* file,char* const argv[]);
这么多的函数第一眼眼看感觉好头大啊,但是其实是有规律的:
这些函数的第一个参数都是为了找到要替换的可执行程序在哪里,函数名结尾没有‘p’的,就直接跟文件路径即可,如果有‘p’证明会在环境变量中查找,如果是环境变量中有的可执行程序,就不需要带路径。
第二个参数是输入的指令,就像是在bash上输入的指令一样,但是结尾必须是NULL。argv[]是将指令封装在一个数组中进行操作,数组中的最后一个元素也必须是NULL。
函数名和参数之前是有联系的:如果函数名中有‘l’,表示函数中的指令像链表(list)一样串联起来以NULL结尾,如果以‘v’结尾,表示函数中的指令被封装在一个数组(vector)中进行使用,有‘p’就表示从环境变量(PATH)中查找可执行程序,有‘e’表示自己维护环境变量
实际上操作系统值提供了execle这一个函数,其他函数都是通过这个函数变形而来的。
模拟实现一个shell
在模拟shell之前有两个问题:
为什么要创建子进程?
从反面来讲,如果不创建子进程,那么就会导致在进程替换发生之后,当前进程无法执行替换之后的代码,但是创建了子进程,让子进程去替换,就可以解决这个问题。
那么shell的目的也是为了让父进程聚焦于读取数据,分析数据,执行的任务交给子进程。
加载到新程序之前。父子进程之间的代码和数据的关系
加载新的进程之前,父子进程之间代码是共享的,数据是写实拷贝的,但是当新程序被替换进来以后,代码也会发生写时拷贝。















 8266
8266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











