







lxml解析数据,在使用parse加载本地的html文件的时候出现报错
报错分析:

我们查看代码发现是没有任何问题的,但报错显示:开始和结束标记不匹配。
lxml.etree.XMLSyntaxError: Opening and ending tag mismatch

这是因为???
html:因为html是超文本标记语言,代码不规范也能解析。
python:python是编程语言,代码不规范则解析不了。
html代码书写不规范,不符合xml解析器的使用规范
解决方案!!!
我们只要给python指定解析器,他是不是能解析出网页呢?
parser = etree.HTMLParser(encoding="utf-8") #parser:解析器。
文件名+网页类型+解析器(指定编码)
把parser解析器放到tree = etree.parse("a.html")里面:tree = etree.parse("a.html", parser=parser)
则可获得到lxml.etree._ElementTree类型的数据
即可进行之后的解析
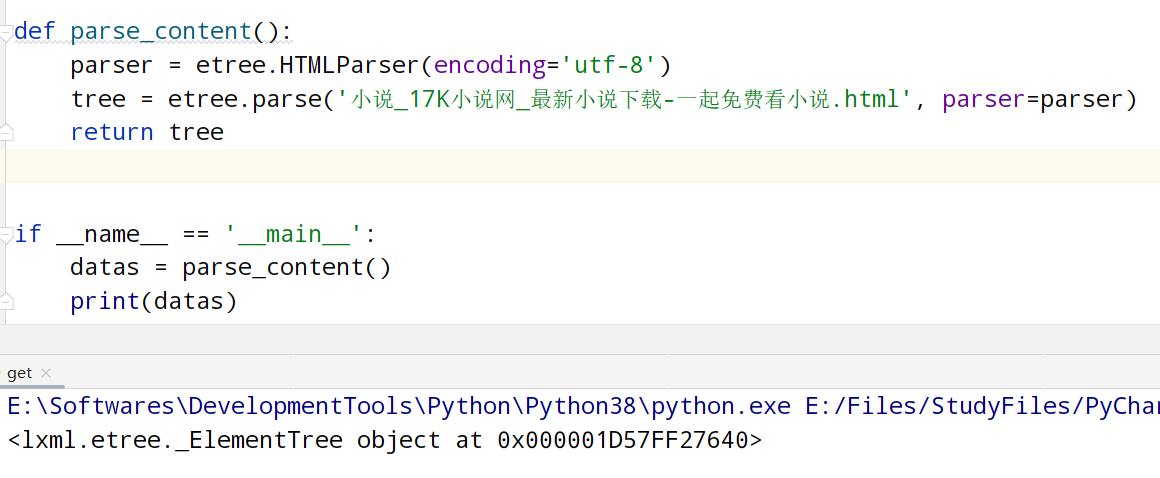
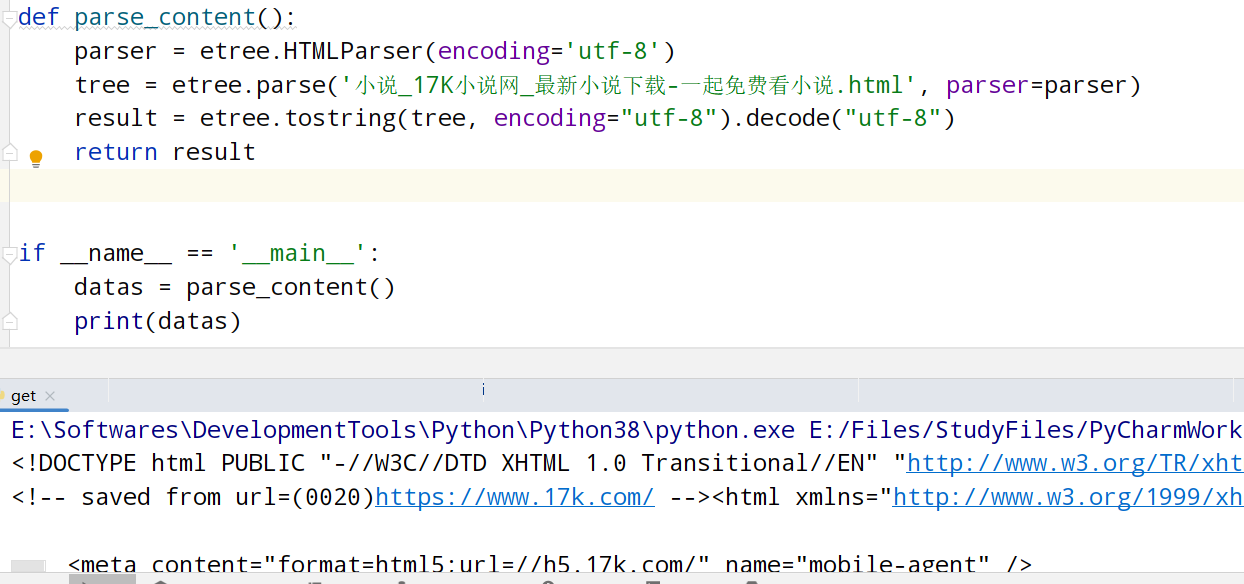
若要查看HTML源码则
指定类型解码:etree.tostring(tree, encoding="utf-8").decode("utf-8")















 4664
4664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









