







题一:使用唯一标识码替换员工ID
Employees 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | name | varchar | +---------------+---------+ 在 SQL 中,id 是这张表的主键。 这张表的每一行分别代表了某公司其中一位员工的名字和 ID 。
EmployeeUNI 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | unique_id | int | +---------------+---------+ 在 SQL 中,(id, unique_id) 是这张表的主键。 这张表的每一行包含了该公司某位员工的 ID 和他的唯一标识码(unique ID)。
展示每位用户的 唯一标识码(unique ID );如果某位员工没有唯一标识码,使用 null 填充即可。
你可以以 任意 顺序返回结果表。
返回结果的格式如下例所示。
示例 1:
输入: Employees表: +----+----------+ | id | name | +----+----------+ | 1 | Alice | | 7 | Bob | | 11 | Meir | | 90 | Winston | | 3 | Jonathan | +----+----------+EmployeeUNI表: +----+-----------+ | id | unique_id | +----+-----------+ | 3 | 1 | | 11 | 2 | | 90 | 3 | +----+-----------+ 输出: +-----------+----------+ | unique_id | name | +-----------+----------+ | null | Alice | | null | Bob | | 2 | Meir | | 3 | Winston | | 1 | Jonathan | +-----------+----------+ 解释: Alice and Bob 没有唯一标识码, 因此我们使用 null 替代。 Meir 的唯一标识码是 2 。 Winston 的唯一标识码是 3 。 Jonathan 唯一标识码是 1 。
方法一(Employees 表左连接(left join xxx on xxx)EmployeeUNI表):1167ms
select es.name,eu.unique_id
from Employees as es left join EmployeeUNI as eu
on es.id = eu.id方法二(使用using自动匹配具有相同列名的列):1127ms
select unique_id, name
from Employees left join
EmployeeUNI using(id)题二:产品销售分析 I
销售表 Sales:
+-------------+-------+ | Column Name | Type | +-------------+-------+ | sale_id | int | | product_id | int | | year | int | | quantity | int | | price | int | +-------------+-------+ (sale_id, year) 是销售表 Sales 的主键(具有唯一值的列的组合)。 product_id 是关联到产品表 Product 的外键(reference 列)。 该表的每一行显示 product_id 在某一年的销售情况。 注意: price 表示每单位价格。
产品表 Product:
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | +--------------+---------+ product_id 是表的主键(具有唯一值的列)。 该表的每一行表示每种产品的产品名称。
编写解决方案,以获取 Sales 表中所有 sale_id 对应的 product_name 以及该产品的所有 year 和 price 。
返回结果表 无顺序要求 。
结果格式示例如下。
示例 1:
输入:
Sales 表:
+---------+------------+------+----------+-------+
| sale_id | product_id | year | quantity | price |
+---------+------------+------+----------+-------+
| 1 | 100 | 2008 | 10 | 5000 |
| 2 | 100 | 2009 | 12 | 5000 |
| 7 | 200 | 2011 | 15 | 9000 |
+---------+------------+------+----------+-------+
Product 表:
+------------+--------------+
| product_id | product_name |
+------------+--------------+
| 100 | Nokia |
| 200 | Apple |
| 300 | Samsung |
+------------+--------------+
输出:
+--------------+-------+-------+
| product_name | year | price |
+--------------+-------+-------+
| Nokia | 2008 | 5000 |
| Nokia | 2009 | 5000 |
| Apple | 2011 | 9000 |
+--------------+-------+-------+方法(Sales表左连接(left join xxx on xxx)Product 表):1146ms
# Write your MySQL query statement below
select s.year ,s.price ,p.product_name
from Sales as s left join Product as p
on s.product_id = p.product_id 题三:进店未进行交易的顾客
表:Visits
+-------------+---------+ | Column Name | Type | +-------------+---------+ | visit_id | int | | customer_id | int | +-------------+---------+ visit_id 是该表中具有唯一值的列。 该表包含有关光临过购物中心的顾客的信息。
表:Transactions
+----------------+---------+ | Column Name | Type | +----------------+---------+ | transaction_id | int | | visit_id | int | | amount | int | +----------------+---------+ transaction_id 是该表中具有唯一值的列。 此表包含 visit_id 期间进行的交易的信息。
有一些顾客可能光顾了购物中心但没有进行交易。请你编写一个解决方案,来查找这些顾客的 ID ,以及他们只光顾不交易的次数。
返回以 任何顺序 排序的结果表。
返回结果格式如下例所示。
示例 1:
输入: Visits+----------+-------------+ | visit_id | customer_id | +----------+-------------+ | 1 | 23 | | 2 | 9 | | 4 | 30 | | 5 | 54 | | 6 | 96 | | 7 | 54 | | 8 | 54 | +----------+-------------+Transactions+----------------+----------+--------+ | transaction_id | visit_id | amount | +----------------+----------+--------+ | 2 | 5 | 310 | | 3 | 5 | 300 | | 9 | 5 | 200 | | 12 | 1 | 910 | | 13 | 2 | 970 | +----------------+----------+--------+ 输出: +-------------+----------------+ | customer_id | count_no_trans | +-------------+----------------+ | 54 | 2 | | 30 | 1 | | 96 | 1 | +-------------+----------------+ 解释: ID = 23 的顾客曾经逛过一次购物中心,并在 ID = 12 的访问期间进行了一笔交易。 ID = 9 的顾客曾经逛过一次购物中心,并在 ID = 13 的访问期间进行了一笔交易。 ID = 30 的顾客曾经去过购物中心,并且没有进行任何交易。 ID = 54 的顾客三度造访了购物中心。在 2 次访问中,他们没有进行任何交易,在 1 次访问中,他们进行了 3 次交易。 ID = 96 的顾客曾经去过购物中心,并且没有进行任何交易。 如我们所见,ID 为 30 和 96 的顾客一次没有进行任何交易就去了购物中心。顾客 54 也两次访问了购物中心并且没有进行任何交易。
方法一(左连接找到transaction_id 为null的然后再将customer_id 分组进行统计次数):
select v.customer_id,count(*) as count_no_trans
from Visits as v left join Transactions as t
on v.visit_id = t.visit_id
where t.transaction_id is null
group by v.customer_id方法二(使用left join, 可以把b.visit_id为null的筛选出来, 然后sum(if(b.visit_id is null, 1, 0))可以对 为 null 的计数, 最后having count_no_trans > 0 把白嫖空调的筛选出来):
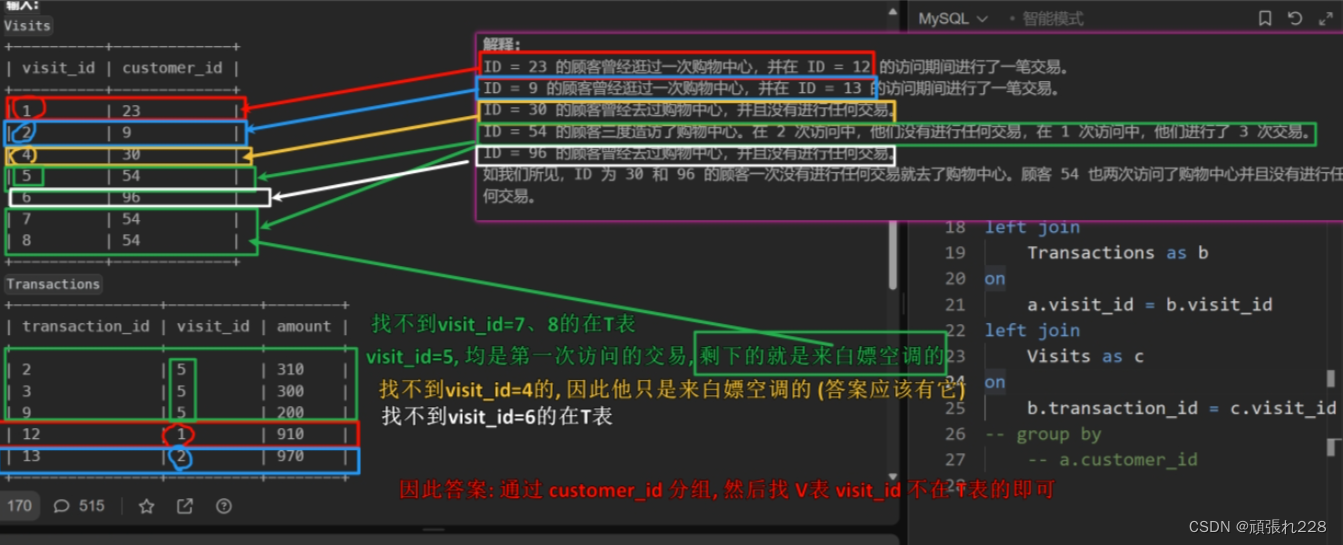
select
a.customer_id as customer_id,
sum(if(b.visit_id is null, 1, 0)) as count_no_trans
from
Visits as a
left join
Transactions as b
on
a.visit_id = b.visit_id
group by
a.customer_id
having
count_no_trans > 0
题四:上升的温度
表: Weather
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | recordDate | date | | temperature | int | +---------------+---------+ id 是该表具有唯一值的列。 没有具有相同 recordDate 的不同行。 该表包含特定日期的温度信息
编写解决方案,找出与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 无顺序要求 。
结果格式如下例子所示。
示例 1:
输入: Weather 表: +----+------------+-------------+ | id | recordDate | Temperature | +----+------------+-------------+ | 1 | 2015-01-01 | 10 | | 2 | 2015-01-02 | 25 | | 3 | 2015-01-03 | 20 | | 4 | 2015-01-04 | 30 | +----+------------+-------------+ 输出: +----+ | id | +----+ | 2 | | 4 | +----+ 解释: 2015-01-02 的温度比前一天高(10 -> 25) 2015-01-04 的温度比前一天高(20 -> 30)
提示:datediff可以统计日期、金额差
方法一(用内连接,避免产生笛卡尔积,数据量大的时候,这种效率更高,datediff可以统计日期差):486ms
SELECT w1.id
FROM weather w1
JOIN weather w2 ON datediff(w1.recorddate, w2.recorddate) = 1 #相邻日期差值是1
WHERE w1.temperature > w2.temperature;方法二(直接让日期 =日期 +1):
SELECT w1.id
FROM weather w1
JOIN weather w2 ON w1.recorddate = w2.recorddate + INTERVAL 1 DAY
WHERE w1.temperature > w2.temperature;题五:每台机器的进程平均运行时间
表: Activity
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| machine_id | int |
| process_id | int |
| activity_type | enum |
| timestamp | float |
+----------------+---------+
该表展示了一家工厂网站的用户活动。
(machine_id, process_id, activity_type) 是当前表的主键(具有唯一值的列的组合)。
machine_id 是一台机器的ID号。
process_id 是运行在各机器上的进程ID号。
activity_type 是枚举类型 ('start', 'end')。
timestamp 是浮点类型,代表当前时间(以秒为单位)。
'start' 代表该进程在这台机器上的开始运行时间戳 , 'end' 代表该进程在这台机器上的终止运行时间戳。
同一台机器,同一个进程都有一对开始时间戳和结束时间戳,而且开始时间戳永远在结束时间戳前面
现在有一个工厂网站由几台机器运行,每台机器上运行着 相同数量的进程 。编写解决方案,计算每台机器各自完成一个进程任务的平均耗时。
完成一个进程任务的时间指进程的'end' 时间戳 减去 'start' 时间戳。平均耗时通过计算每台机器上所有进程任务的总耗费时间除以机器上的总进程数量获得。
结果表必须包含machine_id(机器ID) 和对应的 average time(平均耗时) 别名 processing_time,且四舍五入保留3位小数。
以 任意顺序 返回表。
具体参考例子如下。
示例 1:
输入: Activity table: +------------+------------+---------------+-----------+ | machine_id | process_id | activity_type | timestamp | +------------+------------+---------------+-----------+ | 0 | 0 | start | 0.712 | | 0 | 0 | end | 1.520 | | 0 | 1 | start | 3.140 | | 0 | 1 | end | 4.120 | | 1 | 0 | start | 0.550 | | 1 | 0 | end | 1.550 | | 1 | 1 | start | 0.430 | | 1 | 1 | end | 1.420 | | 2 | 0 | start | 4.100 | | 2 | 0 | end | 4.512 | | 2 | 1 | start | 2.500 | | 2 | 1 | end | 5.000 | +------------+------------+---------------+-----------+ 输出: +------------+-----------------+ | machine_id | processing_time | +------------+-----------------+ | 0 | 0.894 | | 1 | 0.995 | | 2 | 1.456 | +------------+-----------------+ 解释: 一共有3台机器,每台机器运行着两个进程. 机器 0 的平均耗时: ((1.520 - 0.712) + (4.120 - 3.140)) / 2 = 0.894 机器 1 的平均耗时: ((1.550 - 0.550) + (1.420 - 0.430)) / 2 = 0.995 机器 2 的平均耗时: ((4.512 - 4.100) + (5.000 - 2.500)) / 2 = 1.456
提示:round方法设置小数点位数、avg计算平均值
方法一(SUM求和,当进程为end是加上该时间戳,start时减去该时间戳,由于是根据machine_id进行GROUP BY的,所以要*2,ROUND方法对结果位数进行限制):226ms
SELECT
a.machine_id,
ROUND(SUM(CASE WHEN activity_type = 'end' THEN a.timestamp ELSE -a.timestamp END) / COUNT(1) * 2, 3) AS processing_time
FROM activity a
GROUP BY a.machine_id方法二(CASE+小数ROUND+COUNT+SUM):336ms
SELECT
machine_id,
ROUND(SUM(CASE WHEN activity_type = 'end' THEN timestamp ELSE -timestamp END) /
count(distinct process_id), 3) AS processing_time
FROM activity
GROUP BY machine_id方法三(交叉连接也就是求笛卡尔积,然后过滤满足条件的):208ms
select
a1.machine_id,
round(avg(a2.timestamp -a1.timestamp ),3) as processing_time
from Activity as a1 join Activity as a2 on
a1.machine_id=a2.machine_id and
a1.process_id=a2.process_id and
a1.activity_type ='start' and
a2.activity_type ='end'
group by machine_id;















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









