






准备数据集
安装labelimg
输入如下命令进行安装:
pip install labelimg在base环境安装可能会遇到下面问题
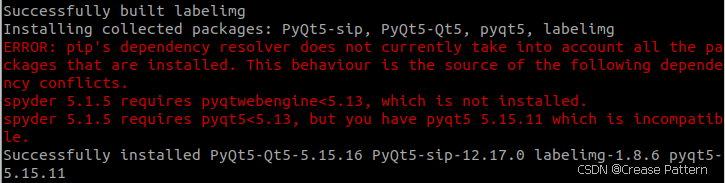
所以我就在虚拟环境安装了,最后没有报错
![]()

使用labelimg
输入
labelImg来打开该软件,注意这里i要大写
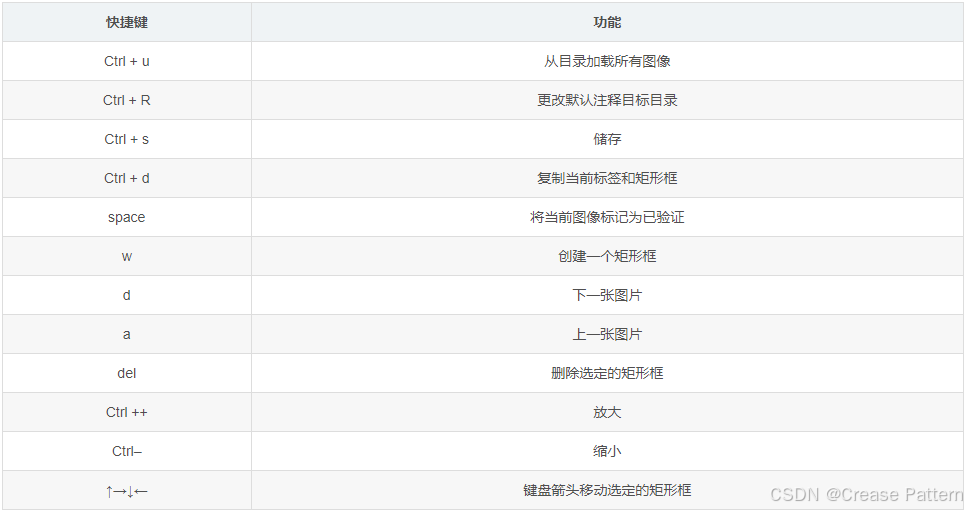
常用的快捷键有:
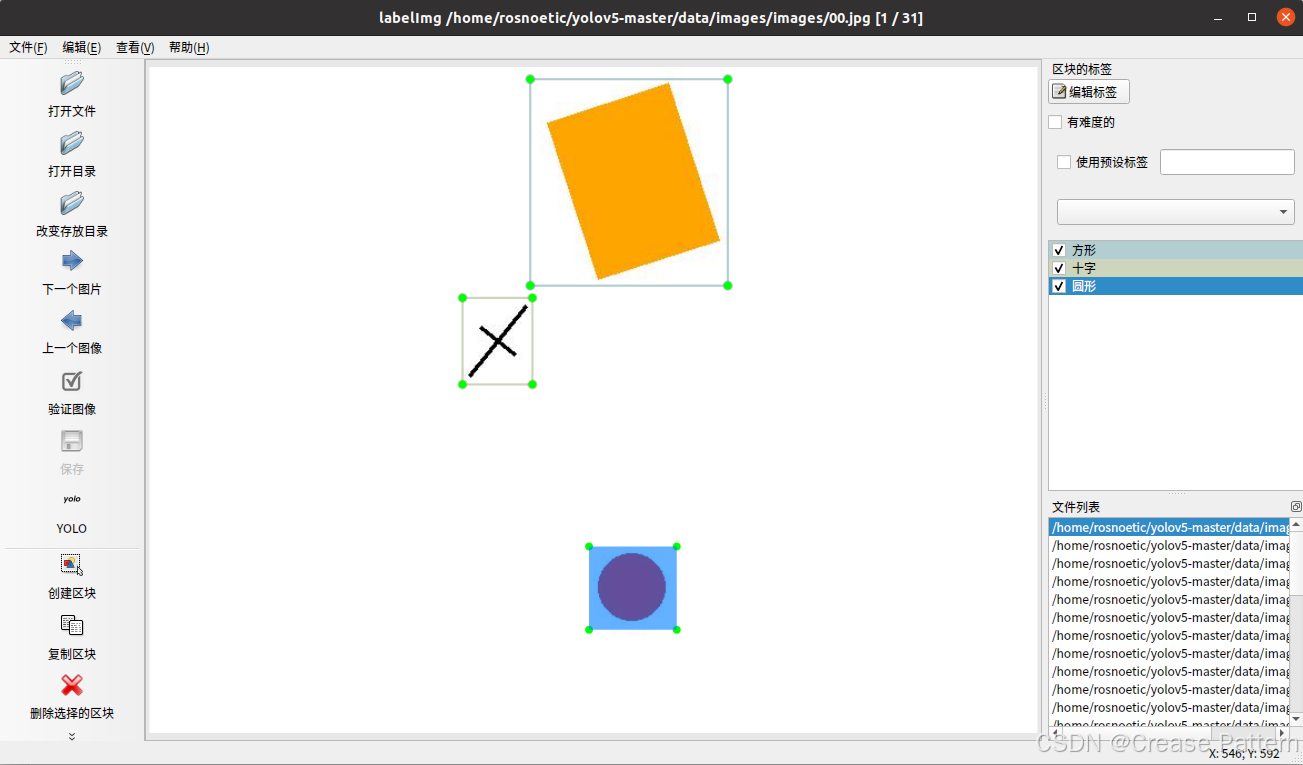
我这里分别创建了 images 和Annotations文件夹,前一个用来存放样本图片,后一个用来存放标记文件
点击打开目录,打开样本所在的文件夹
可以点击创建区块也可以用快捷键来框选目标的范围
框选好后,选择存为YOLO格式(即将标记的信息保存为.txt格式)
先改变存放目录,选定一个文件夹来存放标记好的txt,点击“Save”来保存标记好后的第一张图(这里是灰色是因为已经保存过了)
注意:保存的文件名要与原始图片的文件名保持一致。每标记一张图都要记得保存!
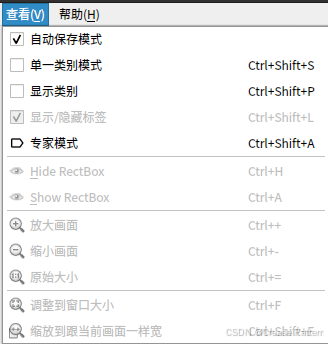
可以设置自动保存
训练模型
首先新建训练集和验证集文件夹,分别命名为“train”和“val”
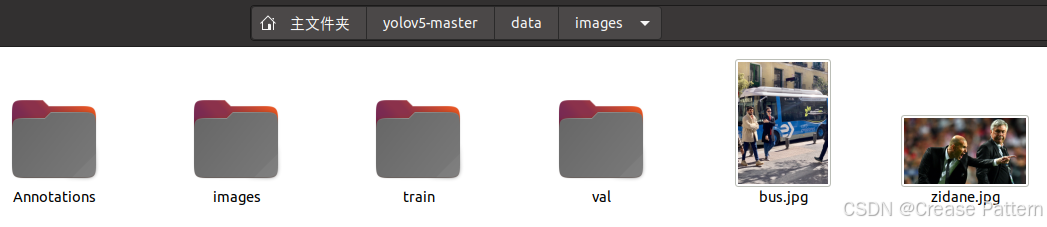
“train”和“val”文件夹都需包含“images”和“labels”文件夹。其中,“images”文件夹用于存放图片,“labels”文件夹用来存放txt

将刚才标注好的约75%的图片和标签分别放入“train”中的“images”和“labels”,用作训练集
注意:图片和标签必需一一对应
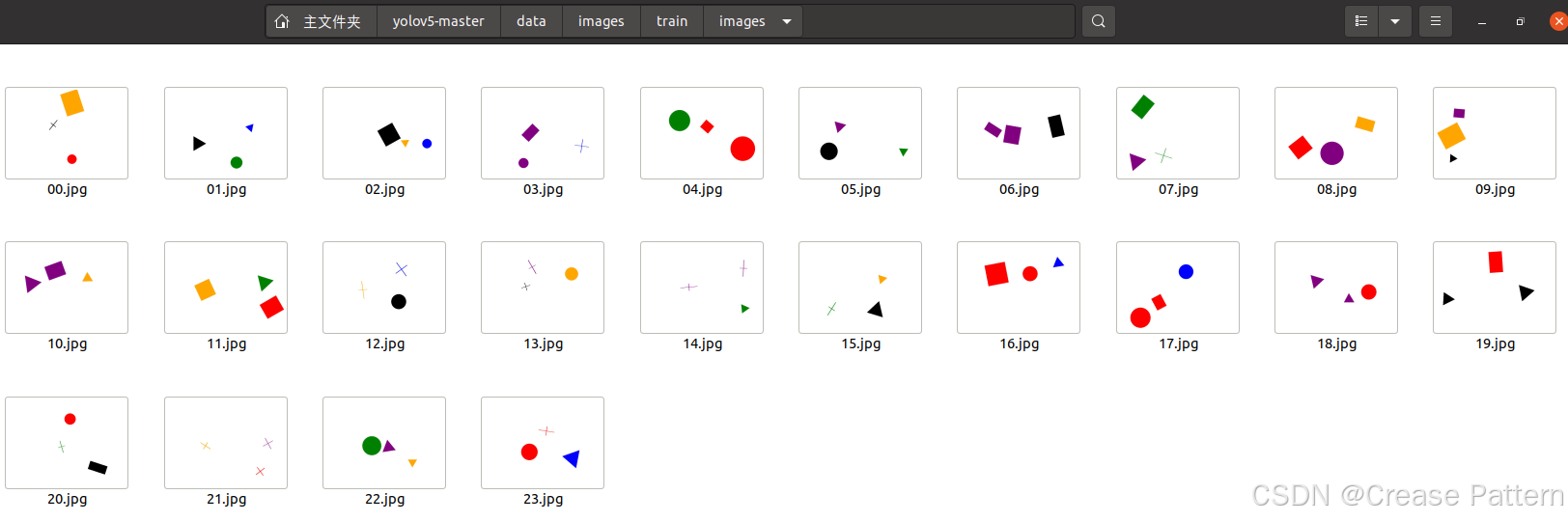
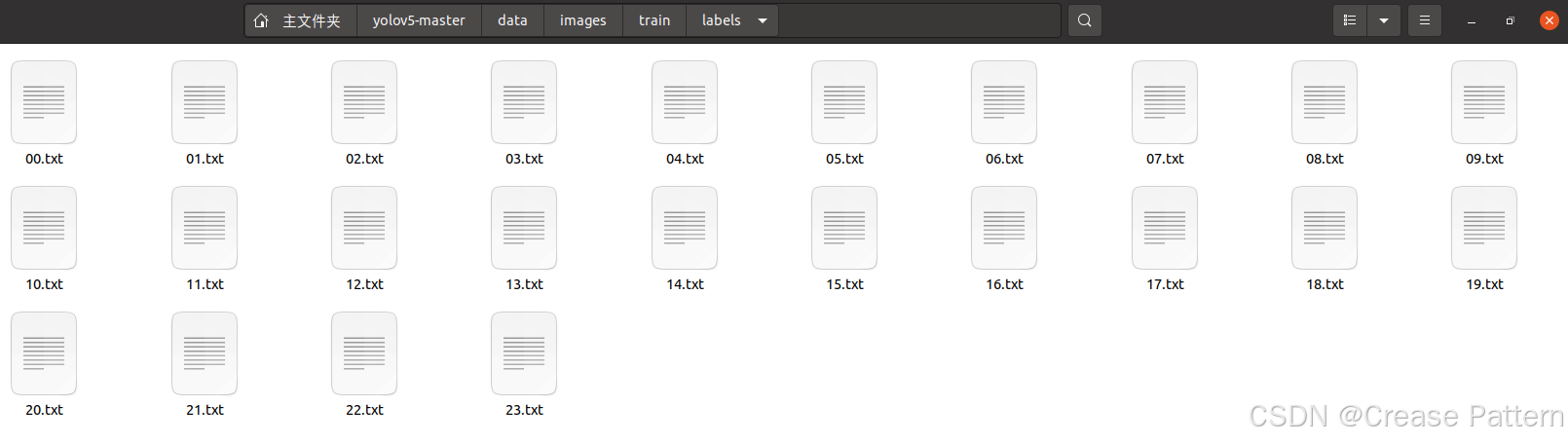
将剩下的放入“val”中的“images”和“labels”,用作验证集
创建一个yaml文件(data.yaml)

文件内容如下:
train: data/images/train/images
val: data/images/val/images
nc: 4
names: ['方形','十字','圆形','三角']根据自己要识别的目标来,nc是类别个数
修改“train.py”中的一些参数,参数解释可以参考YOLOV5训练代码train.py训练参数解析
"data":改成"data/data.yaml",这是刚刚创建的yaml文件 #数据集对应的yaml参数文件;里面主要存放数据集的类别和路径信息
"epochs":这里改成了200轮 #epochs表示训练整个训练集的次数,epochs为n表示将整个训练集训练n次
"batch-size":大小需要根据自己设备GPU的资源合理设置,我改成8后面训练还会被杀死,最后改成4才行 #表示每个 mini-batch 中的样本数,batch-size设置为n表示一次性从训练集中获取n张图片送入模型进行训练
"workers":根据自己的来,可以改成4 #Dataloader中numworkers表示加载处理数据使用的线程数,使用多线程加载数据时,每个线程会负责加载和处理一批数据,数据加载处理完成后,会送入相应的队列中,最后主线程会从队列中读取数据,并送入GPU中进行模型计算;numworkers为0表示不使用多线程,仅使用主线程进行数据加载和处理。
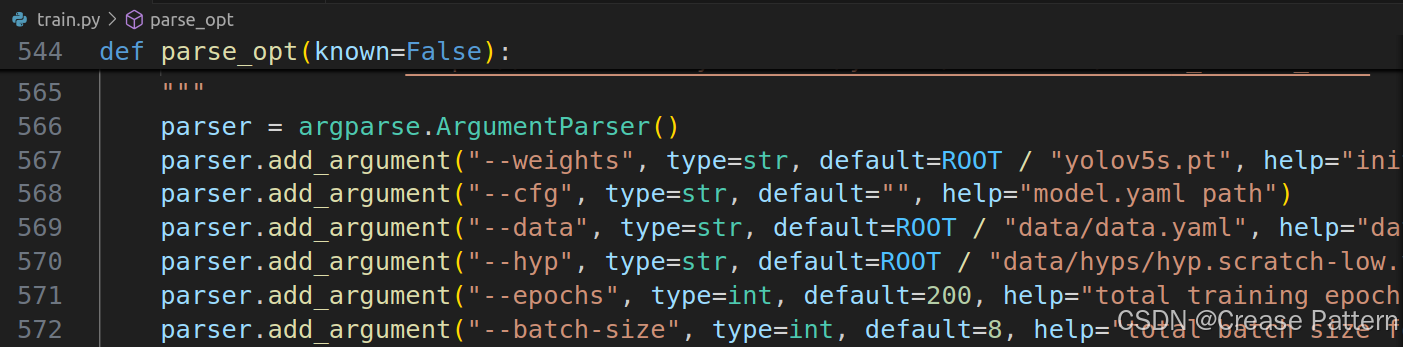

运行train.py来训练
这里会出现一些问题
提示
run 'pip install comet_ml' to automatically track and visualize YOLOv5 🚀 runs in Comet
解决办法:
输入命令
pip install comet_ml
安装完以后再运行还会提示
TypeError: unsupported operand type(s) for |: 'dict' and 'dict'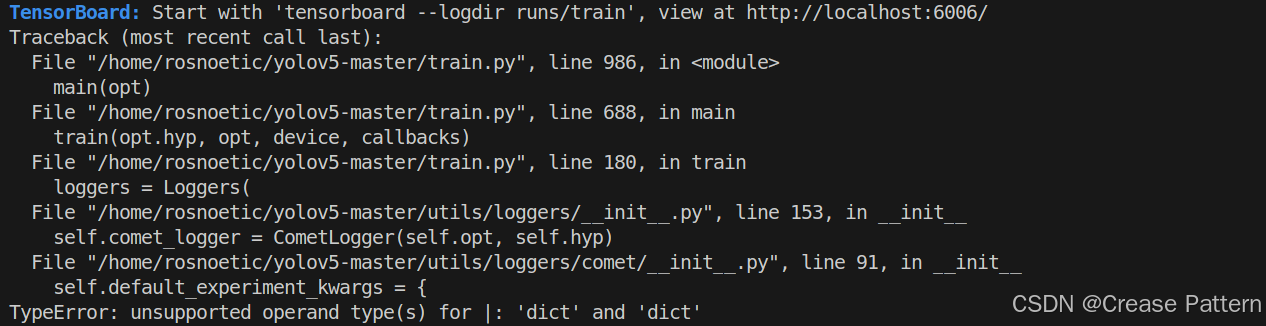
这里结合csdn和deepseek,代码里使用了python3.8不支持的字典合并运算符,3.9应该可以,但是重新安装python环境比较麻烦,试了下没有成功可以参考Python 如何更改现有 conda 虚拟环境的 Python 版本,按流程操作下来发现python版本还是没变,可以用python --version查看,删除python重新安装发现很多依赖都被删了,重新安装也运行不成功
解决办法:
找到错误在的地方,原来的代码是这样
self.default_experiment_kwargs = {
"log_code": False,
"log_env_gpu": True,
"log_env_cpu": True,
"project_name": COMET_PROJECT_NAME,
} | experiment_kwargs改成下面这段,注意代码缩进
self.default_experiment_kwargs = {
**{
"log_code": False,
"log_env_gpu": True,
"log_env_cpu": True,
"project_name": COMET_PROJECT_NAME,
},
**experiment_kwargs
}改完之后再运行,又提示很多东西,开始从github自动下载,巨慢,这个据了解是个字体文件,可以自行去查如何不从github上下载
Downloading https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf to /home/rosnoetic/.config/Ultralytics/Arial.Unicode.ttf...
出现这种已杀死的情况可能就是前面参数没调对,导致内存不够什么的,我这里'batch-size'改成4就可以继续运行

花了差不多一个小时训练完成,因为数据量比较小
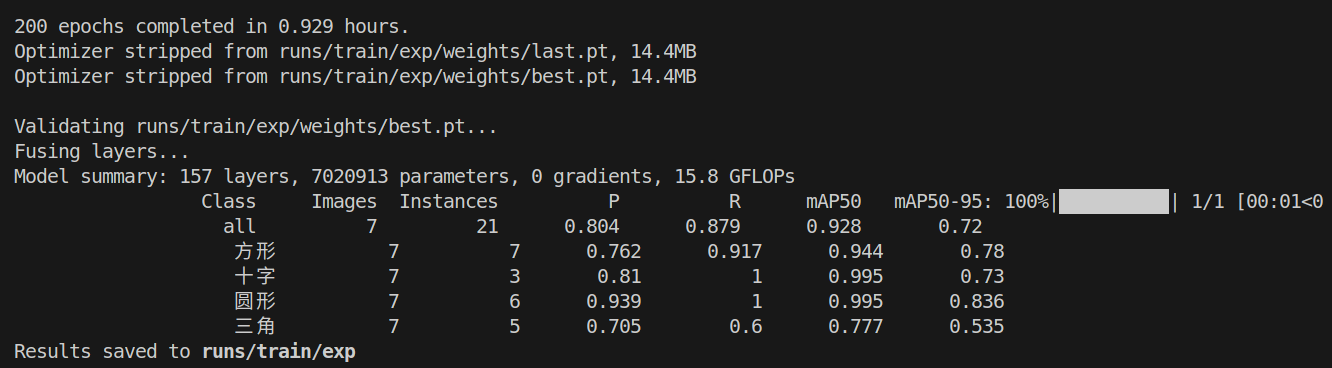
可以看到训练的结果存储在“runs/train/exp/weights”中
训练完成后还有个问题
COMET INFO: Still saving offline stats to messages file before program termination (may take up to 120 seconds)
COMET INFO: Begin archiving the offline data.
COMET INFO: To upload this offline experiment, run:
comet upload /home/rosnoetic/yolov5-master/.cometml-runs/d4d562157ec54c3ea6dbca876d1d9f0f.zip
这些信息是YOLOv5模型训练完成后,由Comet.ml(实验管理工具)生成的提示,涉及离线实验数据的保存和上传流程。以下是逐条解析:
1. Still saving offline stats to messages file...
含义:训练结束后,Comet正在将实验的统计数据(如训练损失、验证精度等)保存到本地文件。
背景:可能因网络中断、主动选择离线模式,或Comet配置为离线运行,导致数据无法实时上传至云端。
注意:此过程可能需要最多120秒,需等待完成后再关闭程序或释放资源。
2. Begin archiving the offline data.
含义:Comet开始将离线数据打包成ZIP压缩文件,路径为.cometml-runs/下的指定子目录。
作用:归档确保所有实验相关文件(如日志、模型权重、评估结果)被完整保留,便于后续上传或迁移。
3. To upload this offline experiment, run: ...
含义:提示用户通过手动执行命令将ZIP文件上传至Comet云端服务器。
操作:在终端运行comet upload /path/to/xxx.zip,需确保:
已安装Comet客户端(pip install comet_ml)。
配置了Comet API密钥(环境变量或配置文件)。
用途:上传后,可在Comet网页仪表盘中查看完整的实验记录、对比结果及可视化数据。
整体流程总结
离线模式运行:训练时未实时同步数据到Comet云端。
训练结束处理:
保存统计数据到本地 → 打包为ZIP → 提示上传命令。
后续操作:手动上传ZIP文件以云端持久化实验记录。
用户注意事项
离线原因:检查网络连接或Comet配置(如COMET_MODE=OFFLINE)。
文件安全:勿删除.cometml-runs/目录下的ZIP文件,直到确认上传成功。
验证上传:登录Comet官网查看实验是否出现在项目列表中。
通过此机制,即使训练时断网,也能保障实验数据不丢失,适合不稳定网络环境或需保密的内部训练场景。
开启新对话根据deepseek的回答推测没什么影响,就是上传到网络失败,因为我训练的时候没连接网络
使用模型
如下图,将detect.py中的“--weights”参数替换为刚训练好的pt文件路径,“--source”改为待检测的图片路径
runs/train/exp/weights/best.ptdata/images/images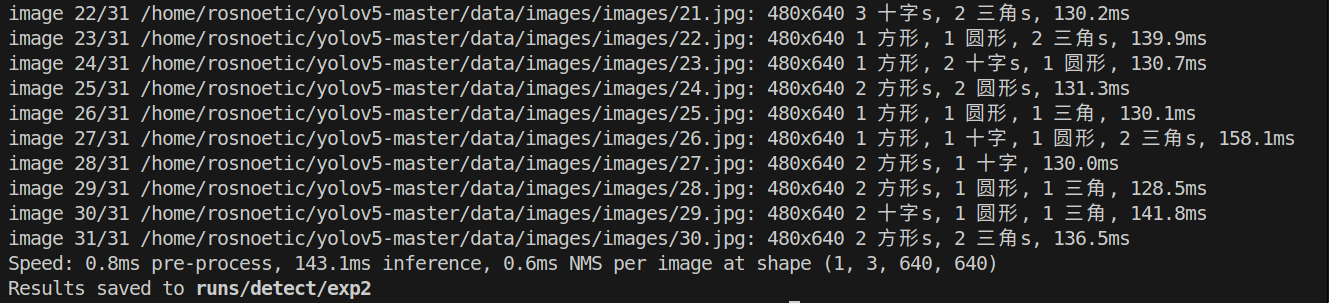
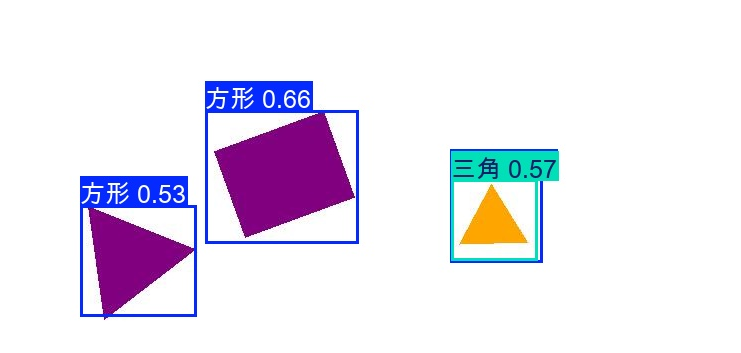
可以看到识别效果还是有点差的,下一步就打算增加数据集量和多样性
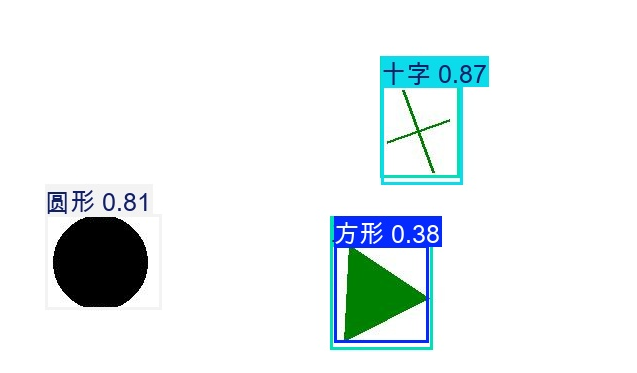
继续训练
如果想在上一次训练的基础上继续训练模型,可以更改“train.py”中的“--weights”参数,改为上一次训练的pt文件



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









