






前言
我们将从源码角度深度分析特点,来提升对他们的了解以及设计。
String、StringBuilder、StringBuffer的常见面试题及四大区别可以参考:String、StringBuilder、StringBuffer的四大区别解析
String
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
// 用final 修饰不可变的char 数组存放字符串
private final char value[];
// 缓存 String 的 hash 值
private int hash; // Default to 0
// 实现序列化的表示
private static final long serialVersionUID = -6849794470754667710L;
}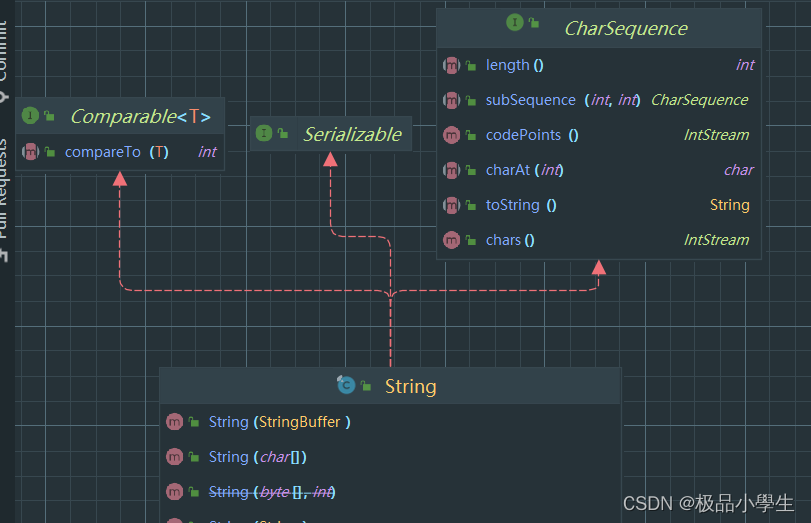
String 实现了三个接口:
Comparable: 说明 String 实现了比较功能,可以比较大小(按顺序比较单个字符的ASCII码)
Serializable: 说明 String 可以实现序列化
CharSequence: 表示是一个有序字符的序列,因为String的本质是一个char类型数组.
被 final 修饰的 char[]
fianl 修饰变量表示改变量的值一旦被初始化后不可以修改。fianl 不论是修饰变量、参数、方法、类都表示其 是完美的不可以被修改,或者逻辑顺序不能改变是一个基本逻辑实现元素。
final 的详细讲解可以看final详解
那为什么这里要用final修饰呢?
被 fianl 修饰就表示不能被继承或者重写修改,String类的设计是Java设计者不希望程序员继承String也就说明String类的最好用法不是继承,而是依赖和关联的关系。
先说被fianl修饰的字符数组
字符串是我们在开发过程中要进程使用的,每一次的创建对象随着次数的增加都会造成资源的大量消耗,导致内存消耗以及庞大的性能开销,为了提高性能,降低内存消耗,提出了字符串共享的方案,在方法区的常量池中保存下创建唯一的字符串去共给不同的类不同的方法以及线程去使用。
再回到这个数组上,字符串共享是解决内存消耗以及性能开销的必然选择,这里还没回答出为什么要被final修饰。共享带来的问题就是安全问题,在多个线程对通同一个字符串访问操作是不确定的,为了保证线程安全并且兼顾内存资源问题最好的办法就是使用fianl修饰。表示禁止修改。
类为什么也要被fianl修饰?
final修饰的类表示不可以被继承,就是限制多态/限制行为。Java的一大特性就是安全性,如果不被fianl修饰,在使用Sring的时候会有太多的不确定性,每一个方法都围绕char数组展开,如果被继承方法进行了多态,会造成不同的语义或者错误的定义,使得String的行为性不确定,使得String对象的代码将是不安全的,所以设计成不能被继承的,来保证它的绝对安全。也说明了这个类最好的使用方法是依赖和关联,而不是继承。
创建方式以及存储区域
public class Demo1 {
public static void main(String[] args) {
String s1 = "hello";
String s2 = new String("hello");
String s3 = "he" + "llo";
String s4 = new String("he") + "llo";
String s5 = new String("he") + new String("llo");
String s6 = new String(s2);
String s7 = new String(s6).intern();
System.out.println(s1 == s2); //false
System.out.println(s1 == s3); //true
System.out.println(s4 == s1); //fasle
System.out.println(s4 == s2); //false
System.out.println(s5 == s2); //false
System.out.println(s6 == s2); //fasle
System.out.println(s7 == s1); //true
}
}我们知道 s1 这种方式创建的对象是在常量池中,并且在栈区直接指向常量池中第一个字符的地址,第二种方式现在常量池中寻找对象如果没有就创建,然后在堆区创建一个对象引用常量池中的位置,再由栈区获取。每一次new对象都会在栈区创建一个新对象,比如 s7 使用了intern方法返回的结果就是 true 这是因为他们其实在常量池的地址都是一样的,但是因为有了堆区的指向,所以不相等,有了intern直接在栈区指向常量池的地址所以就返回了相等。
















 122
122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











