






最近心血来潮,想用爬虫抓取一本小时候看过的小说,但是抓取的过程中老是报这个错:IndexError: list index out of range,很懵逼!

于是我上网查了一下,大概就是可能返回的是空值,或者索引超出了范围,我勒个豆啊,我一想这也太麻烦了,于是我就想简单点,咱惹不起还躲不起吗!那么直接用try.....except......跳过

然后他又又报错了,
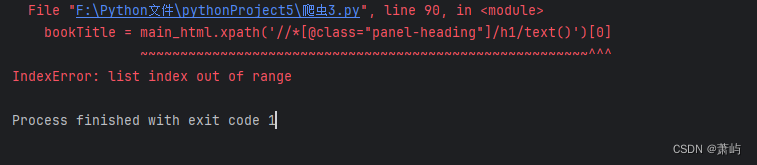
因为我爬取小说需要定位很多个xpath,虽然跳过了一个但是还有下一个

没办法了,只能回到刚开始的地方,
尝试输出一下他的值,

不出意料,果然是个空值,

我想着有没有可能是我xpath路径定位错了,用xpath看了一下,这也也没错啊

又上网看了一下网友们的说法,绝对路径不行,相对路径总应该是可以的

用xpath helper再手动输入一下相对路径,这下总行了吧

然后返回的还是空值,又报错了,这不应该啊

xpath helper网页定位都没有问题,我路径里面也没有tbody这种修饰过的标签啊,是不是遗漏了什么。又仔细看了一遍代码,终于发现是我请求头部填错了,填成上一个爬取网站的网址去了,沃日,赶紧修改过来

最后也是成功的爬取到了小说
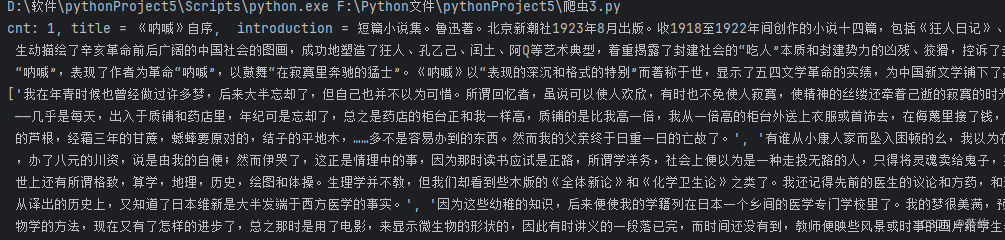
最后,我想说的是:也许只是一个很简单的问题,因为粗心,白白浪费了很多时间,虽然解决问题的过程也很美妙就是了哈哈















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









