







文章目录
1. 进程地址空间
1.1 存在
本文分享一下进程地址空间的解析,实验环境:CentOS 7.6
首先看一下如下代码,逻辑很简单:定义一个全局变量,然后创建子进程,随后父子进程分别打印这个变量的地址
int foo = 10;
int main()
{
int pid = fork();
if (pid == 0) // 子进程
{
cout << "子进程中 foo 变量的地址: [" << &foo << "] | 值为 [" << foo << "] " << endl;
}
else if (pid > 0) // 父进程
{
cout << "父进程中 foo 变量的地址: [" << &foo << "] | 值为 [" << foo << "] " << endl;
}
sleep(1); // 睡眠一秒, 保证打印出来的格式正常
return 0;
}
程序执行结果如下,两者地址一样

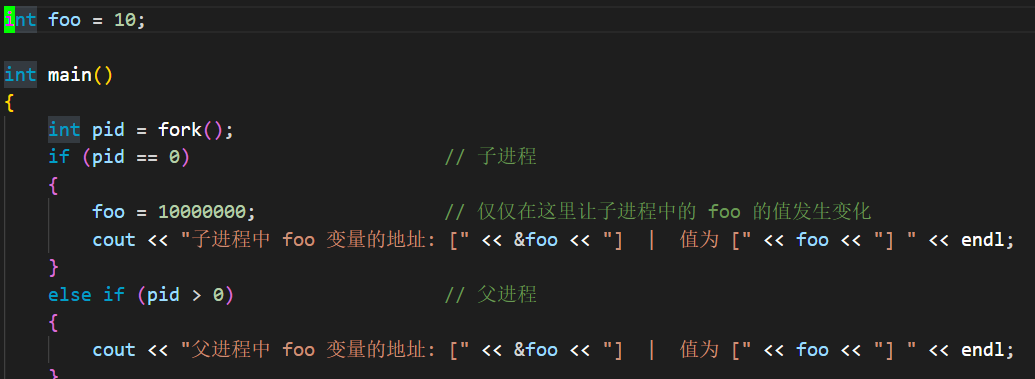
现在稍微修改一下代码:仅在子进程中对 foo 变量做修改
int foo = 10;
int main()
{
int pid = fork();
if (pid == 0) // 子进程
{
foo = 10000000; // 仅仅在这里让子进程中的 foo 的值发生变化
cout << "子进程中 foo 变量的地址: [" << &foo << "] | 值为 [" << foo << "] " << endl;
}
else if (pid > 0) // 父进程
{
cout << "父进程中 foo 变量的地址: [" << &foo << "] | 值为 [" << foo << "] " << endl;
}
sleep(1); // 睡眠一秒, 保证打印出来的格式正常
return 0;
}
现在执行结果如下:

发现不对劲了吗?「两个变量地址一样,但是该地址存储的值是不一样的」,如果说这里变量的地址是物理地址,那必然不存在这种情况,就像我家房子既是游泳池又是核电站一样诡异。
故而这里变量的地址并不是实际的物理地址,其实是进程的虚拟地址
1.2 初步了解
在每一个进程被创建启动的时候,操作系统都会为这些进程赋予虚拟地址空间的概念(在task_struct 中利用数据结构维护起来),并且在 32 位系统下,虚拟地址空间的分布就是由全 0 到 全 F,也就是 4GB,并且这些进程可以将虚拟地址空间视为内存
也就是说:站在任何一个进程的视角下,自己都拥有访问整个内存空间的能力,当进程需要内存的时候,如果条件允许,那么操作系统都会为其分配内存资源
在进程自己的视角下,虽然自己认为拥有物理内存,但是并不是随时都在使用所有资源。更多的表示的是对内存的划分区域后的使用,这里画个草图方便大家理解虚拟地址空间的大致,但是这里并不直接指向物理内存
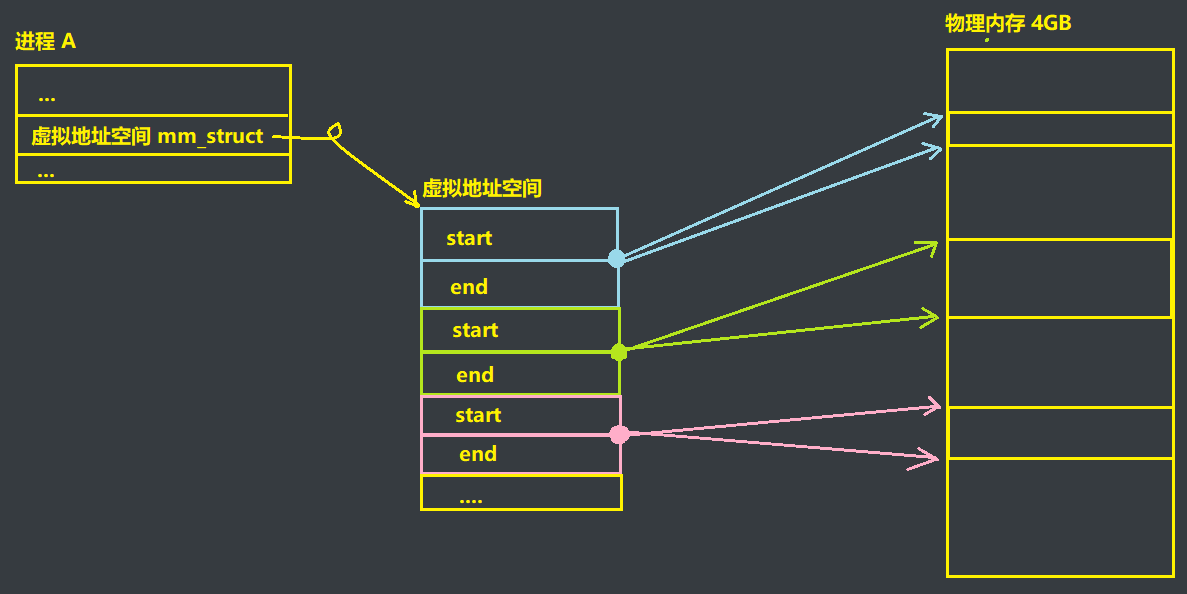
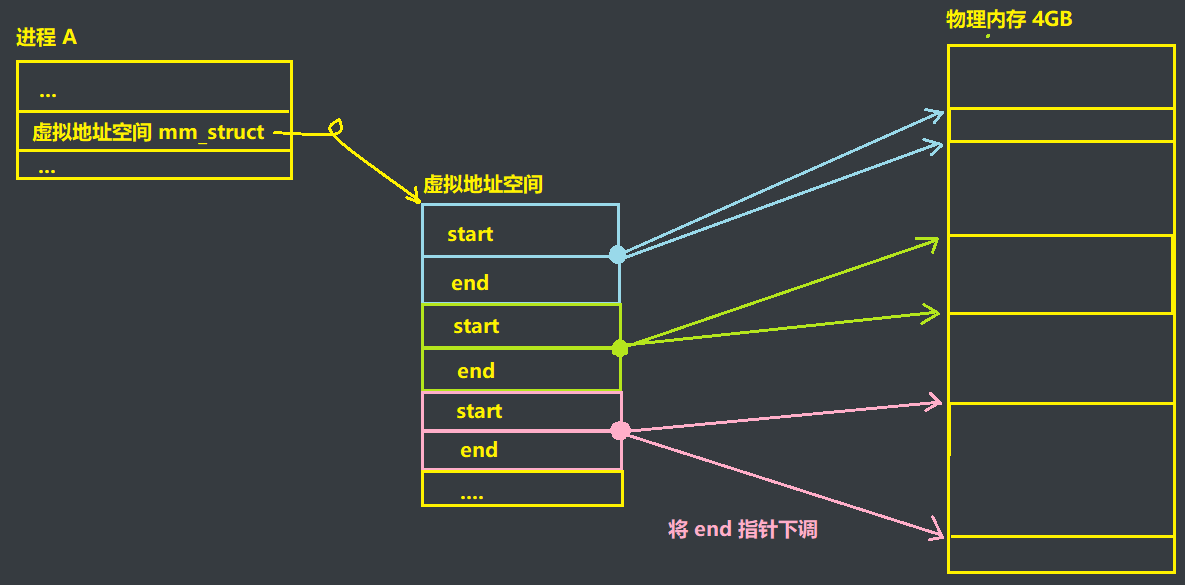
如果说当前进程某一块资源太小了不够用,那么就可以调整 start 和 end 指针来实现区域划分的调整
1.2 虚拟地址空间的划分
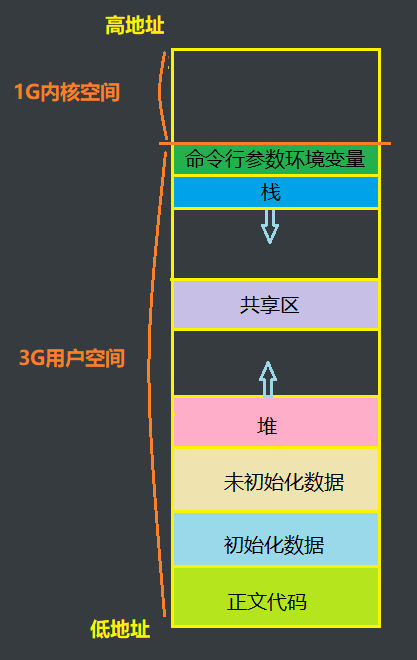
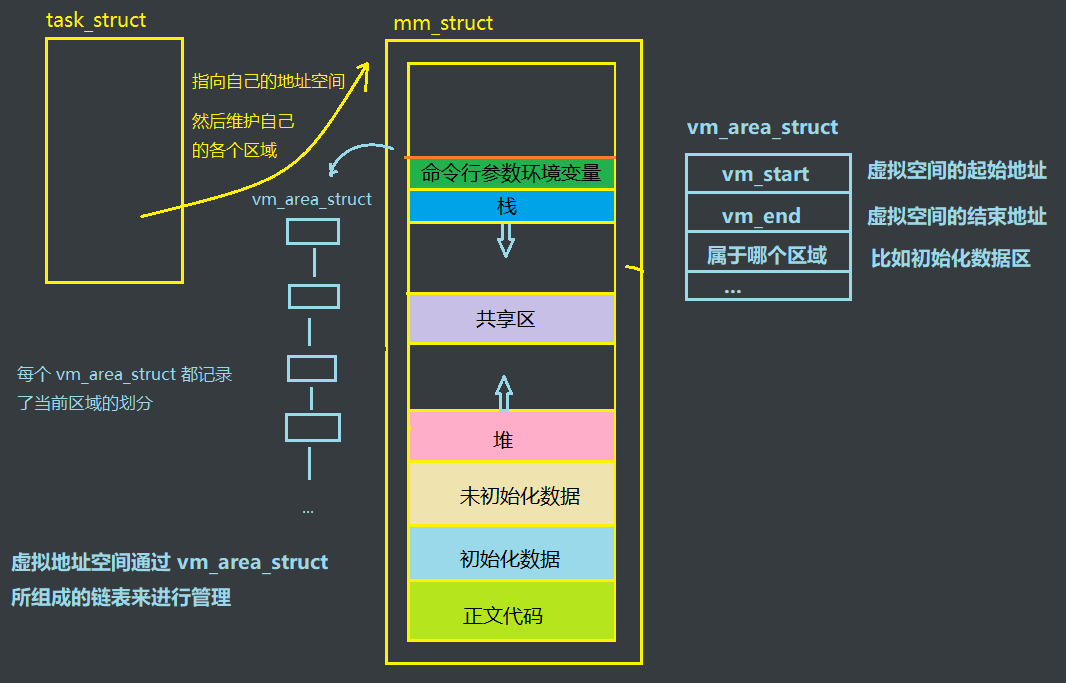
进程的虚拟地址空间被划分成了若干个区域,画图如下:
在Linux中,使用struct task_struct 来描述一个进程,而这个结构体中还有一个数据结构,就是mm_struct,也就是对进程虚拟空间相关的描述
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
...
struct mm_struct *mm, *active_mm;
...
};
而 mm_struct 也不并不会去直接描述这么多区域的虚拟地址空间,它里边还有一个结构体 vm_area_struct 来描述这些分区(正文代码区,初始化数据区…)的区域划分
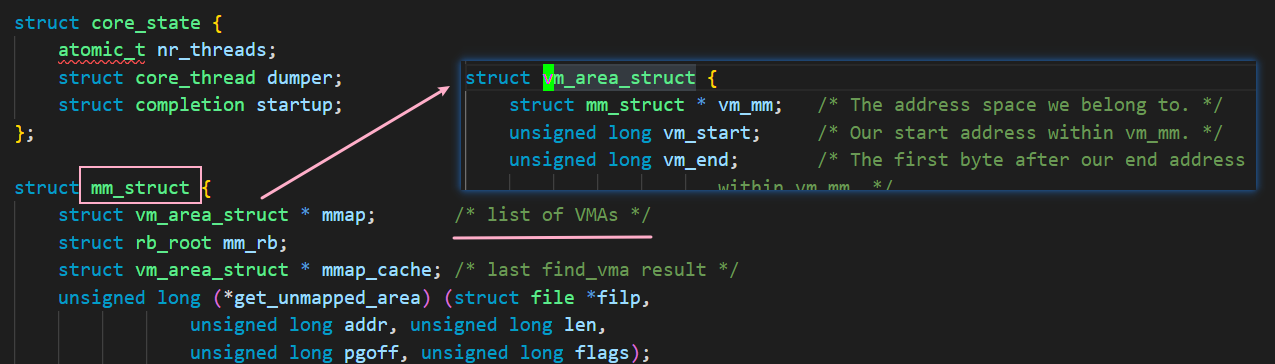
也就是说,进程task_struct 中使用 mm_struct 来描述虚拟地址空间,而虚拟地址空间中被划分成了多个区域,所以mm_struct 中还有vm_area_struct 结构体来描述一个个连续的虚拟地址范围,还会保存该区域的权限等相关属性,比如用来描述堆栈区的vm_area_struct 对象,并且最终 mm_struct 中会将这些 vm_area_struct 通过链表形式连接起来,从而做到虚拟地址空间对堆,栈等空间区域的维护管理
那么现在就又有了一个新的理解,我们再画个草图
1.3 页表
虚拟地址空间和物理内存中还有一层用于映射的软件,可以将虚拟地址通过映射关系映射到物理内存上,最终可以实现通过虚拟地址而拿到物理内存中的真实值,这层软件就是页表。
当程序被加载到内存中的时候,就拥有了加载到内存的物理地址,操作系统会将虚拟地址和物理内存在页表中建立映射关系。并且在程序运行过程中,可能还会动态申请空间,这时候页表仍然会进行虚拟地址和物理地址映射关系的构建
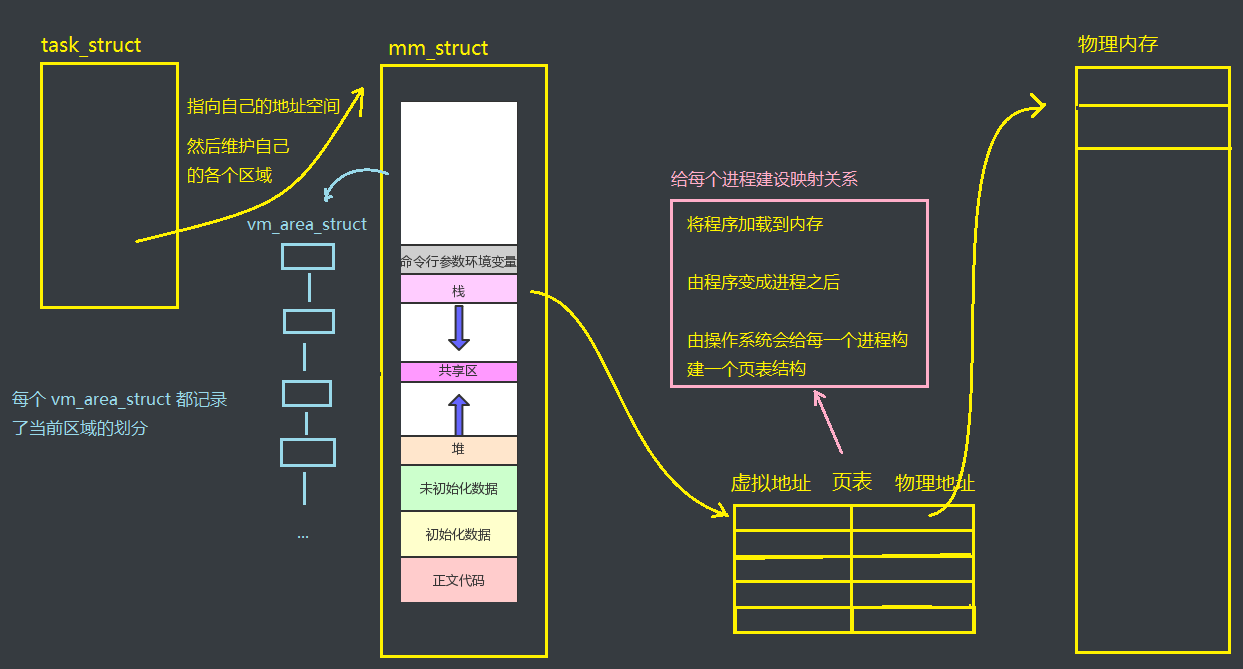
并且每一个进程都拥有自己的页表,页表中还会存储映射的权限等其他复杂的属性(ps:这里的页表经过了简化,实际上可能存在多级页表)
而且多个进程中虚拟地址是允许相等的,因为不同的进程有各自的页表,最终会通过页表来映射到物理内存中的不同位置。有了页表,就可以根据虚拟地址来进行页表映射,从而找到物理内存中的数据了
2. 虚拟地址如何转化成物理地址
页表可以将进程的虚拟地址转化成物理地址,那么这个过程发生了什么?(页表经过简化,但是过程大致一样)
虚拟地址空间有 232 个地址,也就是 4G,而通常页表中的一项(条目)会代表 4KB 的虚拟内存,然后我们称虚拟内存中的 4KB( 212 ) 为一个单位,称为页,因此虚拟地址空间中就会有 232 ÷ ÷ ÷ 212 = = = 220 个页
对应的,4KB 的物理内存也为一个单位,称为页框,而完整的物理内存会被划分成一个个页框
2.1 二级页表
但是实际上,在 Linux 中,一般会使用多级页表。可以通过一级页表来得到二级页表,一层一层往下,最终根据最后一层页表来获取页框的起始物理地址。
现在我们以二级页表为例,说说虚拟地址转化成物理地址的过程
物理内存中,4KB 为一个页框,而物理内存的划分就是按照页框为基本单位进行划分的

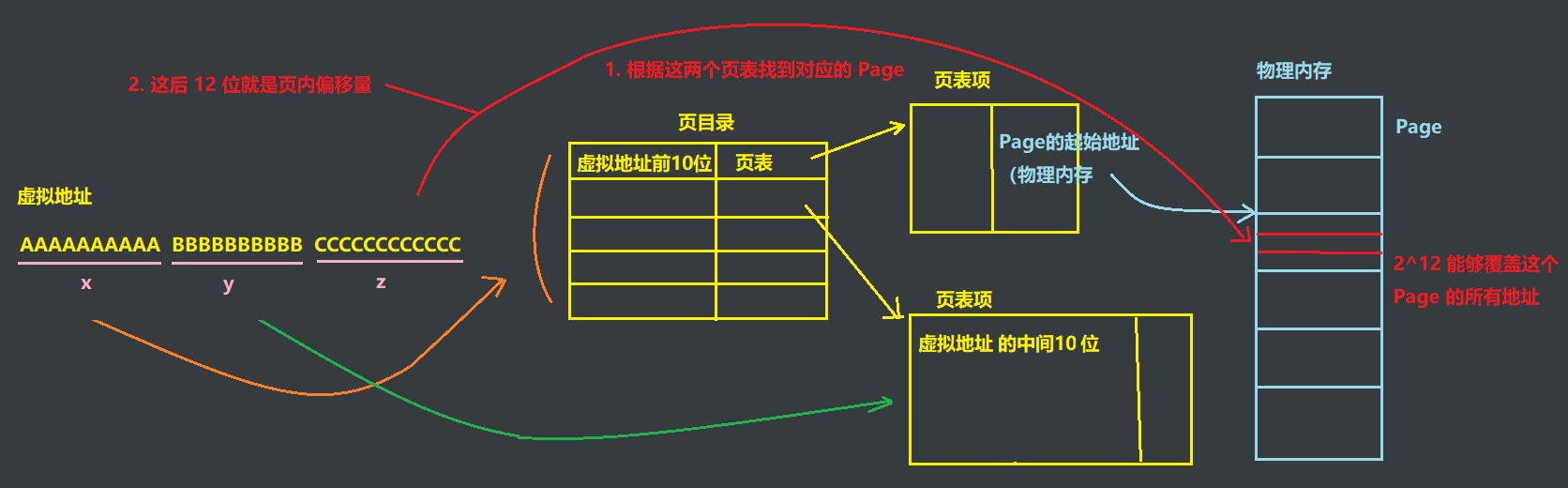
假设现在有个32位的虚拟地址,现在按照如下格式来划分地址
AAAAAAAAAA BBBBBBBBBB CCCCCCCCCCCC,也就是 10 个 A | 10 个 B | 12 个 C,为啥最后一个划分是 12 位?
前面说了物理内存会按照 页框 来一个个划分,页框是 4KB,就是 212,而表示页框里面的地址,刚好就需要 12 个比特位,所以虚拟地址最后 12 位就是偏移量 —— 页框的偏移量
现在将上述地址取个名字,方便讲述:

映射过程如下:
- 首先根据前 10 位,也就是
x可以去一级页表(页目录)中进行映射,然后可以得到二级页表 - 再根据中间 10 位,也就是
y就可以获取到页框(物理块)的起始地址,前面说过物理内存已经被以页框的形式一个个划分好了,这里得到的就是具体某个页框的起始地址 - 再根据最后 12 位,也就是
z,就可以得到页框的偏移量 - 根据第二步中得到的页框起始地址 + 第三部的页框偏移量就可以得到最终的物理内存地址
最终画图如下:
然而实际可能会有多级页表以及更复杂的中间过程,感兴趣的可以深入了解
2.2 总结
再总结一下:
- 最终的查找还是在寻找目标页框,所以页表的作用也就是定位物理内存的目标页框的起始位置
- 然后再通过虚拟地址的最后 12 位页框偏移量来获取目标数据的物理地址
3. 写时拷贝
3.1 原理
在现在的 Linux 中,父进程在 fork 子进程的时候,操作系统会创建子进程的数据结构,包括task_struct,mm_struct(虚拟地址空间),页表,文件描述符表…,并且拷贝父进程数据结构中的大部分数据,少部分数据根据子进程实际情况作修改,然后共享父类代码
然后这时候父子进程各自的页表上的映射关系权限都会改成只读权限,如果有一方尝试修改,操作系统就会开辟一段空间,将原数据拷贝过去并修改,修改后再调整页表的映射关系,这个数据修改完成之后,父子进程中,该数据在页表中的映射权限就会都改成普通权限
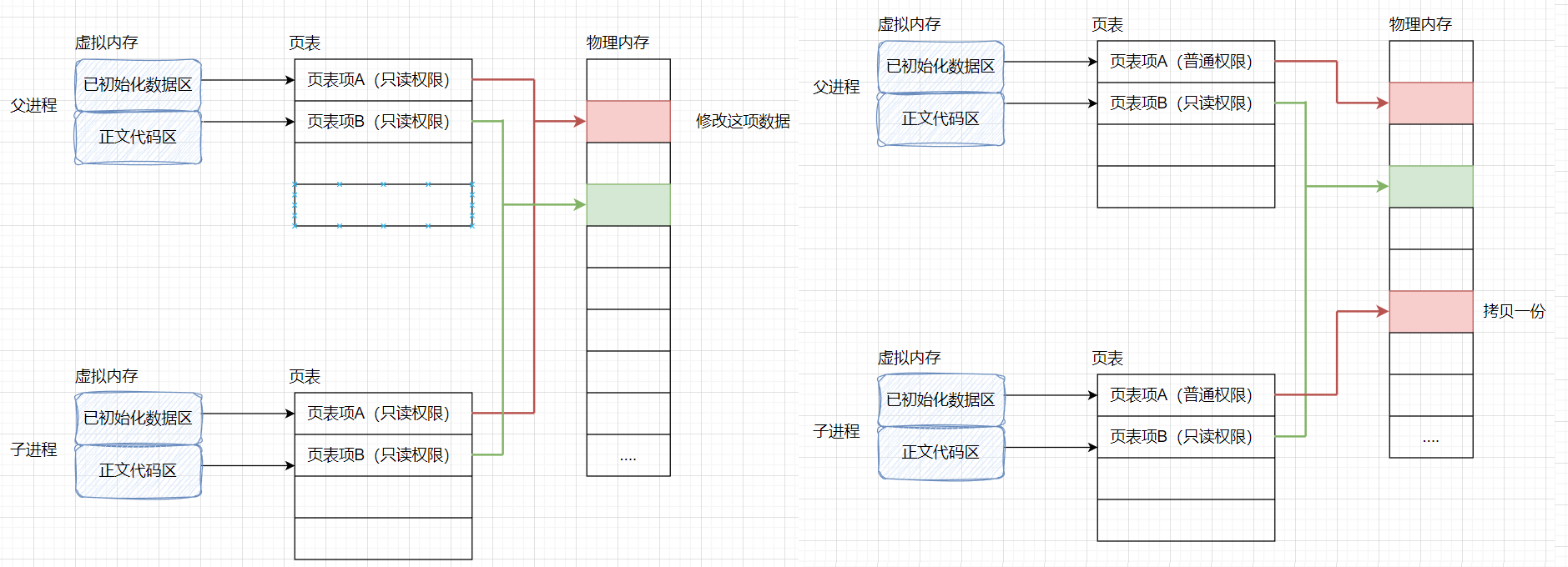
因此,在一开始演示的代码中,如下
- 在执行
foo = 10000000之前,父子进程的虚拟地址空间和页表一样(大部分拷贝自父类),子进程也还暂时没有修改数据 - 而在执行
foo = 10000000之后,foo变量被修改,子进程就会发生写实拷贝,重新在内存中开辟一个int空间,并且赋值 - 然后再在页表中让这个虚拟地址(不变)和新的物理地址重新建立映射关系
- 所以才有打印的地址一样,而地址的值不一样的情况。
- 根本原因就是两个进程的页表将相同的虚拟地址映射到了不同的物理地址上
原因就是子进程发生了写时拷贝,为int开辟了个新空间
3.2 解释为什么 pid_t ret = fork() 中,ret 会有两个不同的值
在上面那段程序中,同一个变量 pid 来接收 fork 的返回值,但是有两个不同的值?
- 父进程创建子进程后,子进程会以写时拷贝的方式拷贝父类的数据和数据结构,包括程序的代码。在
fork函数中的return语句之前,函数的主要任务已经完成,也就是完成了子进程创建,并放入到了运行队列中(一般子进程不会对代码做修改,所以父子进程执行的代码是一样的) - 那么既然子进程都创建成功了,那么
return语句也就会被父子进程各执行一次 return语句实际上会将返回值先写入到寄存器中,然后寄存器再将返回值写入到ret中,ret也就是接收fork函数返回值的变量- 而
ret是父进程中栈空间的变量,哪个进程先接收返回值,就会导致ret变量被修改,从而发生写实拷贝,重新建立页表映射关系 - 所以在这两个进程的执行逻辑中,该变量虚拟地址一致,但是物理内存不同,最终值自然不同。这个说法和上面很类似了
4. 为何需要虚拟地址空间
- 物理地址需要被保护
① 为物理内存的直接访问提供了一层软件层,可以在访问内存之前进行审核
如果是非法访问操作,比如空指针,或者指针越界,那么就会因为页表中不存在这份映射导致请求直接被拦截;
② 如果是对某些文件进行修改,但是没有修改权限,那么也会被页表所拦截,页表中存在相关的权限管理,存储了对映射关系的权限 - 让进程管理和内存管理之间进行解耦
① 如果没有虚拟内存空间,那么如果一个进程正在malloc来申请内存空间,就会去调用malloc的底层代码,进行内存管理要进行的工作
② 而现在,如果malloc来申请空间,那么操作系统会将进程中虚拟空间中对应的堆区扩大相应的大小,允许用户访问这段空间,但是不会马上进行内存的分配。等到用户真正要使用这块内存空间的时候,才会触发内存管理,申请物理空间,建立映射关系,就可以进行两者的解耦 - 虚拟地址空间的存在允许多个进程的相同虚拟地址映射到相同的物理地址,可以高效地进行进程间通信,
- 保证进程的独立性,让进程拥有自己独立的运行环境,可以防止进程异常或者崩溃影响到其他进程,提高了稳定性
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











