






背景
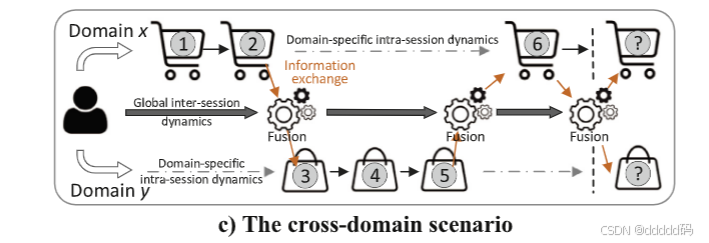
单域数据存在数据稀疏性,现在有多个会话的数据,因此可以合理地假设,融合用户的跨域序列行为能够提升个性化会话推荐的性能。因此我们需要考虑如何整合来自多个基于会话的领域的用户序列信息呢?受到启发,我们打算通过统一捕捉不同领域的会话间动态和会话内动态,共同对用户的全局兴趣信息和局部序列模式进行建模。如下图。
挑战
第一个方面是行为差异。尽管不同领域之间存在一些重叠,比如相同的用户或物品。然而,由于服务的多样性,即使面对相同的物品,用户也可能有不同的行为和偏好。简单地组合跨领域信息可能会引入噪声,从而降低推荐性能。
第二个方面是时间不同步。即使是同一用户的相似行为,往往也会表现出显著的时间差异。
例如,在不同的时间,同一部电影可能会在不同地方再次被该用户评分。如果只是简单地按时间顺序将不同领域的数据分割成片段分别进行处理,跨领域的相关性就会丢失。
模型概述和贡献
在本文中,我们提出了一种基于循环神经网络(RNN)的创新模型,称为跨域分层循环模型(CDHRM),通过联合利用用户跨域的顺序行为来整合不同领域的顺序信息。
首先,我们设计了一个跨域用户级RNN,它接受来自不同领域的所有会话输入,通过对跨域会话间动态进行建模,统一描述用户的全局动态兴趣。
然后,假设我们要融合两个不同领域的信息(该方法可直接推广到更多领域),我们设计了两个特定领域的会话级RNN,分别捕捉不同领域的会话内动态,这样可以保留行为差异。同时,为了实现不同领域异步信息的交互,用户级RNN被设计为按时间顺序与会话级RNN进行信息共享。此外,我们引入了具有不同集成方式的融合层,以进一步描述用户在不同领域间的行为差异。
最后,我们联合使用跨域用户级和会话级信息,以实现更优的个性化会话推荐。
问题陈述
假设我们有两个基于会话的领域 x 和 y。设
为跨域重叠用户的集合,其中L是所有领域中重叠用户的数量。
设
为领域
中的物品集合,
是领域d中物品的数量。
我们假设物品集可以有交集,也可以没有交集,即
,其中
是
中重叠物品的数量。
对于用户u,领域d中的顺序行为
由一系列按时间顺序排列的会话
组成,其中
是用户u在领域d中的会话数量,
表示用户u在领域d中的第m个会话。
基于上述符号和定义,我们正式将本研究的问题表述为:给定一组用户的所有跨域顺序数据,即
,我们旨在设计一个跨域推荐模型,能够为每个用户在其感兴趣的每个领域中推荐下一个物品。
循环神经网络(RNNs)
循环神经网络在捕捉序列数据的动态特征方面表现出色。与标准的前馈神经网络不同,循环神经网络保留了一个隐藏状态,这个隐藏状态可以表示来自可变长度上下文的信息。
形式上,对于每个会话
,循环神经网络通过以下函数更新其隐藏状态
其中,f是一个非线性变换,例如逻辑 sigmoid 函数,并且
。
将输入
与已经计算出的信息(即循环状态
)相结合。
门控循环单元(GRU)
在本文中,我们使用门控循环单元(GRU)作为公式(1)中的非线性变换f,以克服循环神经网络中的梯度消失问题。f的具体参数化形式如下:
其中,
是逻辑 sigmoid 函数,
表示元素对应相乘,
、
和W是常规权重矩阵,
、
和H分别是三个不同门的循环权重矩阵。在接下来的内容中,这个函数将被记为
。
提出的模型:CDHRM
下图展示了 CDHRM 的图形表示,它由三个RNN(循环神经网络)构成层次结构,即一个跨域用户级 RNN和两个特定领域的会话级RNN。
跨域用户级 RNN 对用户跨域会话间动态兴趣的演变进行建模,并为基于会话的RNN提供个性化指导。每个特定领域的会话级RNN对依赖于领域的会话内顺序模式进行建模,并生成相应领域的推荐。此外,该模型通过按时间顺序在用户级RNN和会话级RNN之间共享信息,实现异步信息交换。我们还在模型中插入了一个基于乘积神经网络的融合层,以捕捉用户在不同领域的行为差异。接下来,我们联合使用跨域用户级和会话级信息,在接下来的会话中提供个性化推荐。
跨域用户级循环神经网络
添加了一个融合层
来对用户的跨域行为交互进行建模,然后设计了一个跨域用户级循环神经网络(即
),用于跟踪用户的全局动态兴趣并实现跨域异步信息交换。
形式上,对于每个拥有会话
的用户u,我们将领域d中的会话表示记为
,其中
是每个会话
的会话级循环神经网络(即
)的最后一个隐藏状态,用于更新
,其中
是会话
为了区分用户u在两个领域中的相同会话ID,我们用
表示领域d中的当前会话m,用
表示会话m之前所有领域中的前一个会话。为方便起见,余下部分省略用户上标u。
为了有效捕捉用户行为的特征,我们首先在
不同领域的会话表示
和用户兴趣表示
分别可以从
:
- 基于拼接的情况:
- 基于乘积的情况:
- 基于拼接和乘积的情况 1:
- 基于拼接和乘积的情况 2:
其中,
形式上,对于输入
,融合层构建如下:
其中,
和
是
然后,跨域用户兴趣表示
其中,
(零向量),
【通俗易懂的解释一下】
这部分内容主要介绍了跨域用户级 RNN,它是 CDHRM 模型的一部分,主要用于跟踪用户的全局动态兴趣并实现跨域异步信息交换。
那么我们关注的两个重点是如何跟踪全局的兴趣以及如何进行知识迁移?
下面用看电影和听音乐的例子来解释:
整体功能:假如有个用户,他既喜欢看电影(领域 x),又喜欢听音乐(领域 y) 。跨域用户级RNN就像是一个 “兴趣追踪器”,能通过分析这两个平台的行为,了解他的整体兴趣变化。
融合层及函数:为了更好地追踪兴趣,这里设置了融合层。融合层有 4 种融合函数。比如基于拼接的情况,把在电影平台上一次会话的最后行为(如看完一部动作片)表示为
,在音乐平台上一次会话结束时的兴趣状态表示为
,那么基于拼接的融合就是把这两个信息拼在一起。
更新用户兴趣表示:融合后的信息会输入到
知识迁移方面:
迁移方式:在这个模型里,知识迁移是通过融合层和
特定领域会话级循环神经网络
两种不同的会话级循环神经网络(
和
),分别用于捕捉领域x和领域y中会话特定的、独立的动态模式。
连体长短期记忆网络(Siamese LSTM)可能是对领域感知顺序模式进行建模的有效方案。然而,连体长短期记忆网络难以保留序列之间的差异,因为它旨在捕捉序列之间的相关性。因此,我们采用了一种更合适的方法,即使用两个特定领域的会话级循环神经网络对领域感知顺序模式进行建模。为了补充个性化信息,我们不仅利用跨域用户兴趣表示来初始化
和
),将会话级循环神经网络中的顺序模式与用户偏好进行整合。
会话级 RNN 中的融合层:独热编码的效果总是优于额外的嵌入层,因此在我们仅考虑对物品使用独热编码。由于独热编码和用户兴趣表示来自不同的维度空间,所以我们采用基于拼接的整合函数
将二者结合起来。
其中,是领域d中当前物品 ID 的独热编码。
与公式 (3) 类似,我们为
)构建融合层如下:
此外,为了进一步增强个性化对
其中和
是领域d中的初始化权重和偏置。通过初始化,可以将用户的先验信息融入到会话级状态中。然后,领域d的会话表示按如下方式更新:
其中是用户u在领域d中第m个会话的循环状态。
优化目标
用户级循环神经网络(RNN)和会话级 RNN 都用于对用户的序列行为进行建模。不同之处在于,用户级门控循环单元(GRUu)专注于跟踪所有域中用户兴趣在会话间的全局演变,而特定域的会话级 GRUxs 和 GRUys 则分别关注每个域中会话内序列行为的局部动态。因此,我们将这两种互补的 RNN 结合起来,共同对用户跨域序列行为的动态进行建模。此外,用户级和会话级信息会传播到我们模型的最终预测层以生成输出。那么,模型针对域 d 的输出分数
,代表了在域 d 的会话中成为下一个物品的可能性,其计算方式如下:
其中,
是一个非线性函数,如双曲正切函数(tanh)或 Softmax 函数,具体取决于最终的损失函数。
由于 TOP1-max [31] 在克服基于会话的推荐中随着样本数量增加而出现的梯度消失问题方面表现出色,因此我们基于 TOP1-max 构建目标函数。我们的网络也可以使用几种排序最大损失函数进行训练,如 BPR-max [23],然而,TOP1-max 的性能始终优于其他损失函数。TOP1-max 的优化准则是将目标分数推高到最相关样本分数之上(即样本中的最大分数)。然后,我们通过最小化以下函数来推导目标函数:
其中,
和
是会话中某一时刻物品 i 和物品 j 的分数,i 是目标物品,j 是从 x 和 y 域的物品集中随机选择的负样本。我们还尝试仅将目标分数与所有域中最相关的样本分数进行比较(即,我们为每个目标物品从所有域中选择负样本)。由于最大选择操作不可微,我们通过对由相应 Softmax 函数
加权的单个成对损失求和来连续逼近它。
用 Sigmoid 函数进行逼近,最终的损失函数如下:
其中,
是单个成对损失的 Softmax 权重,
是一个正则化项,用于迫使负样本的分数趋近于零。
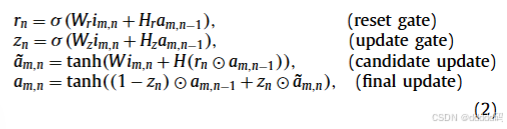
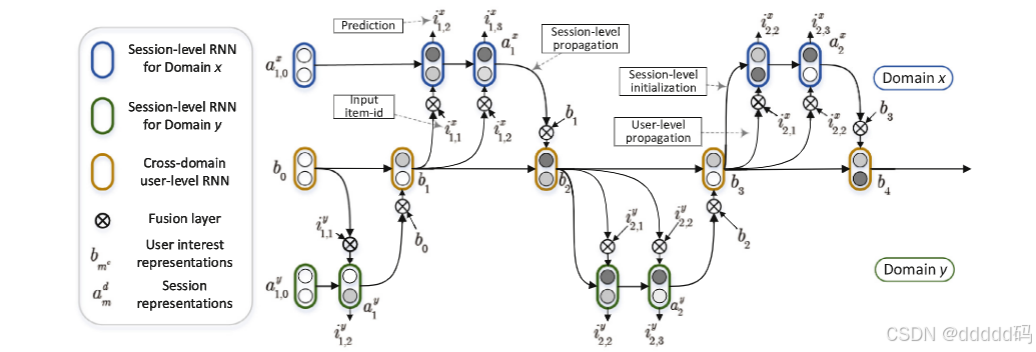
模型核心结构与处理流程
CDHRM 分为 三层结构,层层递进处理输入数据,分别是:
1. 领域会话级 RNN(最底层:分析单领域行为)
2. 跨域用户级 RNN(中间层:整合跨领域兴趣)
3. 融合层(贯穿其中:处理领域差异和兴趣交互)
1. 领域会话级 RNN:分析每个领域的具体行为
作用:分别分析用户在 电影域 x 和 音乐域 y 中的每个会话,捕捉该领域内的行为模式(比如用户在电影会话中喜欢 “科幻片→动作片” 的顺序)。
处理步骤:
对每个领域的每个会话,用一个 独立的 RNN(如 GRU) 处理。
输入:该领域会话中的物品 ID 序列(如电影 ID 序列),以及 用户的全局兴趣初始化值(来自中间层,后面会讲)。
输出:每个会话的 “会话表示”(即这个会话的整体特征向量,包含该会话的兴趣模式)。
关键细节:
用 独热编码 表示物品 ID(比如 “电影 A” 用 [1,0,0] 表示),简单直接。
通过 融合层 将物品 ID 和用户全局兴趣结合,让模型知道 “用户在当前会话中喜欢什么” 的同时,还考虑 “用户整体喜欢什么”。
2. 跨域用户级 RNN:整合跨领域的全局兴趣
作用:把用户在 电影域 和 音乐域 的会话信息 “串联” 起来,分析用户跨领域的兴趣演变(比如看完科幻电影后听电子音乐的模式)。
处理步骤:
输入:每个会话结束后的 “会话表示”(来自底层 RNN),以及 上一次的全局兴趣状态。
融合层处理:
用不同策略(如 “拼接” 或 “元素相乘”)将当前会话的领域特征与之前的全局兴趣结合。例如:
拼接:把电影会话的特征和音乐会话的特征接在一起,形成更长的向量。
相乘:通过数学运算找出两个领域特征的关联(比如 “喜欢科幻电影” 和 “喜欢电子音乐” 的相关性)。
输出:更新后的 用户全局兴趣状态(比如 “用户现在同时喜欢科幻和电子音乐”)。
关键细节:
按 时间顺序 处理所有领域的会话(比如先处理电影会话,再处理音乐会话,交替进行)。
通过 循环神经网络(GRU) 追踪用户兴趣的变化,比如用户从 “喜欢浪漫电影 + 流行音乐” 转向 “喜欢科幻电影 + 电子音乐” 的过程。
3. 融合层:处理领域差异和兴趣交互
作用:解决不同领域的行为差异(比如电影和音乐的推荐逻辑不同),同时提取跨领域的关联。
怎么工作:
在 领域会话级 RNN 中,融合层把 “当前物品” 和 “用户全局兴趣” 结合,让模型知道 “用户在听这首歌时,整体兴趣如何”。
在 跨域用户级 RNN 中,融合层把 “当前领域的会话特征” 和 “之前的全局兴趣” 结合,确保模型既保留领域特性,又能跨域关联。
三、模型输出:推荐下一个可能感兴趣的物品
如何生成推荐:
用 领域会话级 RNN 预测当前领域的下一个物品(比如根据用户刚看完的电影,推荐同类型电影)。
同时用 跨域用户级 RNN 的全局兴趣状态,调整推荐结果(比如根据用户刚听完的音乐,推荐相关电影)。
最终输出每个领域的 物品推荐列表(如 “接下来可能看的电影” 和 “可能听的音乐”)。
数学上的输出: 通过一个非线性函数(如 Softmax)计算每个物品的 “推荐分数”,分数越高越可能被推荐。公式大致是:推荐分数=f(领域会话特征,用户全局兴趣特征)
四、一个通俗比喻:模型像一个 “跨领域的兴趣追踪器”
场景:用户今天看了科幻电影《星际穿越》(电影域会话),然后听了汉斯・季默的电影原声音乐(音乐域会话)。
模型处理流程:
领域会话级 RNN:电影域 RNN 分析 “《星际穿越》→ 科幻片” 的模式,得出 “用户当前会话喜欢科幻”。音乐域 RNN 分析 “汉斯・季默原声→ 电影配乐” 的模式,得出 “用户当前会话喜欢电影原声”。
跨域用户级 RNN:发现 “科幻电影” 和 “电影原声音乐” 的关联,更新全局兴趣为 “用户喜欢科幻题材 + 电影配乐”。
输出推荐:电影域推荐《火星救援》(同是科幻片),音乐域推荐《蝙蝠侠》原声(同是汉斯・季默的电影配乐)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









