







【面试必备】经典限流算法讲解
参考资料:
一:限流是什么?
限流,也称流量控制。是指系统在面临高并发,或者大流量请求的情况下,限制新的请求对系统的访问,从而保证系统的稳定性。限流会导致部分用户请求处理不及时或者被拒,这就影响了用户体验。所以一般需要在系统稳定和用户体验之间平衡一下。举个生活的例子:
一些热门的旅游景区,一般会对每日的旅游参观人数有限制的。每天只会卖出固定数目的门票,比如5000张。假设在五一、国庆假期,你去晚了,可能当天的票就已经卖完了,就无法进去游玩了。即使你进去了,排队也能排到你怀疑人生。
二:为什么要限流?
日常的业务上有类似秒杀活动、双十一大促或者突发新闻等场景,用户的流量突增,后端服务的处理能力是有限的,如果不能处理好突发流量,后端服务很容易就被打垮。
亦或是爬虫等不正常流量,我们对外暴露的服务都要以最大恶意去防备调用者。
限流的本质是因为后端处理能力有限,需要截掉超过处理能力之外的请求,亦或是为了均衡客户端对服务端资源的公平调用,防止一些客户端饿死。
三:常见的限流算法
1:固定窗口计数限流算法
首先维护一个计数器,将单位时间段当做一个窗口,计数器记录这个窗口接收请求的次数。
- 当次数少于限流阀值,就允许访问,并且计数器+1
- 当次数大于限流阀值,就拒绝访问。
- 当前的时间窗口过去之后,计数器清零。
假设单位时间是1秒,限流阀值为3。在单位时间1秒内,每来一个请求,计数器就加1,如果计数器累加的次数超过限流阀值3,后续的请求全部拒绝。等到1s结束后,计数器清0,重新开始计数。如下图:

伪代码如下:
/**
* 固定窗口时间算法
* @return
*/
boolean fixedWindowsTryAcquire() {
long currentTime = System.currentTimeMillis(); //获取系统当前时间
if (currentTime - lastRequestTime > windowUnit) { //检查是否在时间窗口内
counter = 0; // 计数器清0
lastRequestTime = currentTime; //开启新的时间窗口
}
if (counter < threshold) { // 小于阀值
counter++; //计数器加1
return true;
}
return false;
}
优点就是:简单粗暴,单机在 Java 中可用 Atomic 等原子类、分布式就 Redis incr。
缺点就是:假设我们允许的阈值是1万,此时计数器的值为 0, 当 1 万个请求在前 1 秒内一股脑儿的都涌进来,这突发的流量可是顶不住的。
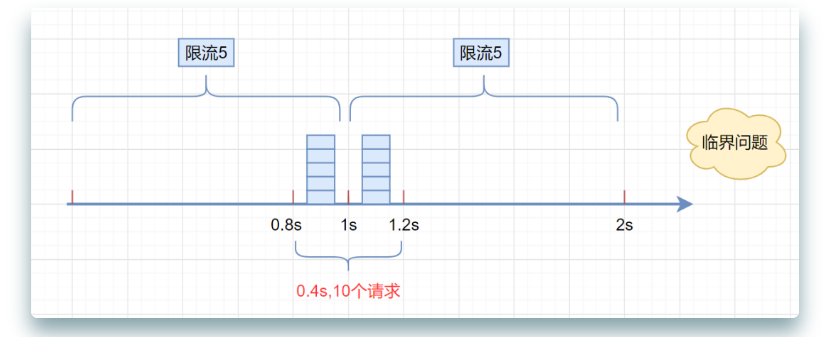
但是,这种算法有一个很明显的临界问题:假设限流阀值为5个请求,单位时间窗口是1s,如果我们在单位时间内的前0.8-1s和1-1.2s,分别并发5个请求。虽然都没有超过阀值,但是如果算0.8-1.2s,则并发数高达10,已经超过单位时间1s不超过5阀值的定义啦。
2:滑动窗口限流算法
滑动窗口限流解决固定窗口临界值的问题。它将单位时间周期分为n个小周期,分别记录每个小周期内接口的访问次数,并且根据时间滑动删除过期的小周期。
相对于固定窗口,滑动窗口除了需要引入计数器之外还需要记录时间窗口内每个请求到达的时间点,因此对内存的占用会比较多。
一张图解释滑动窗口算法,如下:
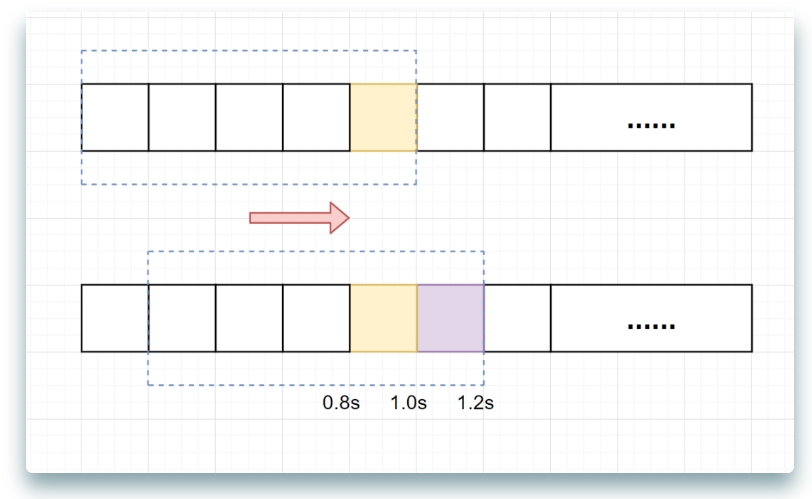
假设单位时间还是1s,滑动窗口算法把它划分为5个小周期,也就是滑动窗口(单位时间)被划分为5个小格子。每格表示0.2s。每过0.2s,时间窗口就会往右滑动一格。然后呢,每个小周期,都有自己独立的计数器,如果请求是0.83s到达的,0.8~1.0s对应的计数器就会加1。
我们来看下滑动窗口是如何解决临界问题的?
假设我们1s内的限流阀值还是5个请求,0.81.0s内(比如0.9s的时候)来了5个请求,落在黄色格子里。时间过了1.0s这个点之后,又来5个请求,落在紫色格子里。如果**是固定窗口算法,是不会被限流的**,但是**滑动窗口的话,每过一个小周期,它会右移一个小格**。过了1.0s这个点后,会右移一小格,当前的单位时间段是0.21.2s,这个区域的请求已经超过限定的5了,已触发限流啦,实际上,紫色格子的请求都被拒绝啦。
当滑动窗口的格子周期划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
滑动窗口算法伪代码实现如下:
/**
* 单位时间划分的小周期(单位时间是1分钟,10s一个小格子窗口,一共6个格子)
*/
private int SUB_CYCLE = 10;
/**
* 每分钟限流请求数
*/
private int thresholdPerMin = 100;
/**
* 计数器, k-为当前窗口的开始时间值秒,value为当前窗口的计数
*/
private final TreeMap<Long, Integer> counters = new TreeMap<>();
/**
* 滑动窗口时间算法实现
*/
boolean slidingWindowsTryAcquire() {
long currentWindowTime = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC) / SUB_CYCLE * SUB_CYCLE; //获取当前时间在哪个小周期窗口
int currentWindowNum = countCurrentWindow(currentWindowTime); //当前窗口总请求数
//超过阀值限流
if (currentWindowNum >= thresholdPerMin) {
return false;
}
//计数器+1
counters.get(currentWindowTime)++;
return true;
}
/**
* 统计当前窗口的请求数
*/
private int countCurrentWindow(long currentWindowTime) {
//计算窗口开始位置
long startTime = currentWindowTime - SUB_CYCLE* (60s/SUB_CYCLE-1);
int count = 0;
//遍历存储的计数器
Iterator<Map.Entry<Long, Integer>> iterator = counters.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Long, Integer> entry = iterator.next();
// 删除无效过期的子窗口计数器
if (entry.getKey() < startTime) {
iterator.remove();
} else {
//累加当前窗口的所有计数器之和
count =count + entry.getValue();
}
}
return count;
}
滑动窗口算法虽然解决了固定窗口的临界问题,但是一旦到达限流后,请求都会直接暴力被拒绝。酱紫我们会损失一部分请求,这其实对于产品来说,并不太友好。
但是滑动窗口和固定窗口都无法解决短时间之内集中流量的突击。
我们所想的限流场景是:
每秒限制 100 个请求。希望请求每 10ms 来一个,这样我们的流量处理就很平滑,但是真实场景很难控制请求的频率,因此可能存在 5ms 内就打满了阈值的情况。
当然对于这种情况还是有变型处理的,例如设置多条限流规则。不仅限制每秒 100 个请求,再设置每 10ms 不超过 2 个。
再多说一句,这个滑动窗口可与TCP的滑动窗口不一样。
TCP的滑动窗口是接收方告知发送方自己能接多少“货”,然后发送方控制发送的速率。
接下来再说说漏桶,它可以解决时间窗口类的痛点,使得流量更加平滑。
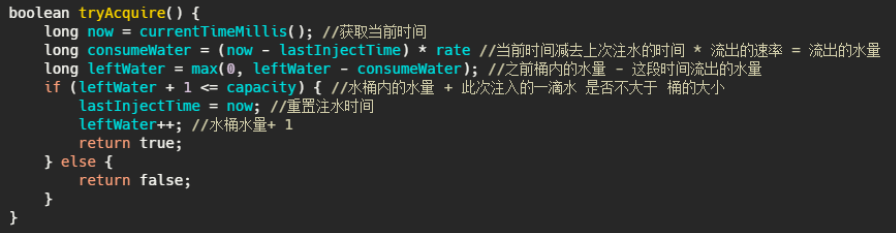
3:漏桶算法
漏桶算法面对限流,就更加的柔性,不存在直接的粗暴拒绝。
它的原理很简单,可以认为就是注水漏水的过程。往漏桶中以任意速率流入水,以固定的速率流出水。当水超过桶的容量时,会被溢出,也就是被丢弃。因为桶容量是不变的,保证了整体的速率。
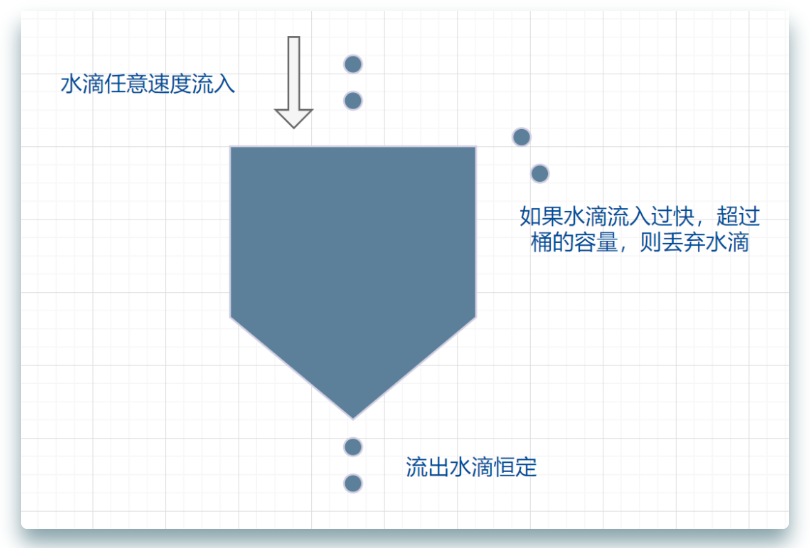
- 流入的水滴,可以看作是访问系统的请求,这个流入速率是不确定的。
- 桶的容量一般表示系统所能处理的请求数。
- 如果桶的容量满了,就达到限流的阀值,就会丢弃水滴(拒绝请求)
- 流出的水滴,是恒定过滤的,对应服务按照固定的速率处理请求。
漏桶算法伪代码实现如下:
在正常流量的时候,系统按照固定的速率处理请求,是我们想要的。但是面对突发流量的时候,漏桶算法还是循规蹈矩地处理请求,这就不是我们想看到的啦。流量变突发时,我们肯定希望系统尽量快点处理请求,提升用户体验嘛。
它的特点就是宽进严出,无论请求多少,请求的速率有多大,都按照固定的速率流出,对应的就是服务按照固定的速率处理请求。
“他强任他强,老子尼克杨”。

看到这想到啥,是不是和消息队列思想有点像,削峰填谷。
一般而言漏桶也是由队列来实现的,处理不过来的请求就排队,队列满了就开始拒绝请求。
看到这又想到啥,线程池不就是这样实现的嘛?
经过漏洞这么一过滤,请求就能平滑的流出,看起来很像很挺完美的?实际上它的优点也即缺点。
面对突发请求,服务的处理速度和平时是一样的,这其实不是我们想要的。
在面对突发流量我们希望在系统平稳的同时,提升用户体验即能更快的处理请求,而不是和正常流量一样,循规蹈矩的处理(看看,之前滑动窗口说流量不够平滑,现在太平滑了又不行,难搞啊)。
而令牌桶在应对突击流量的时候,可以更加的“激进”。
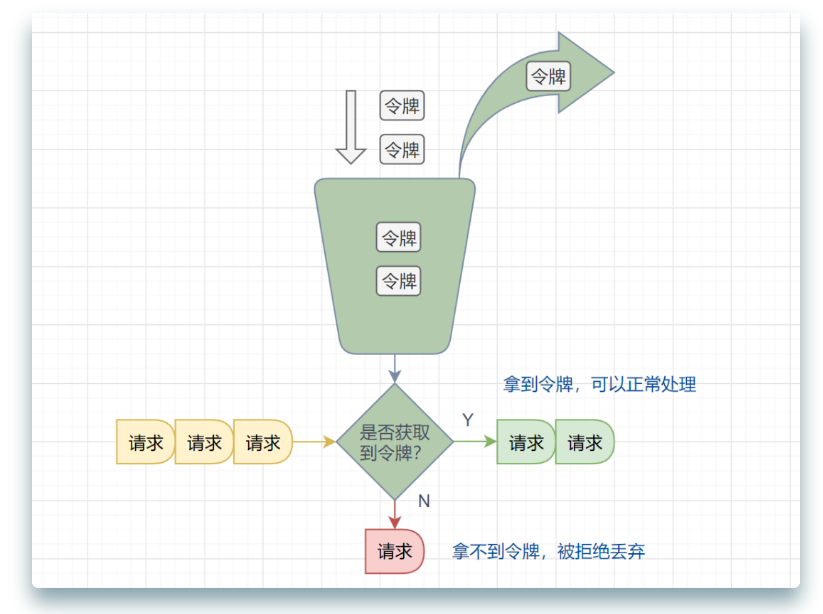
4:令牌桶算法
面对突发流量的时候,我们可以使用令牌桶算法限流。
令牌桶算法原理:
- 有一个令牌管理员,根据限流大小,定速往令牌桶里放令牌。
- 如果令牌数量满了,超过令牌桶容量的限制,那就丢弃。
- 系统在接受到一个用户请求时,都会先去令牌桶要一个令牌。如果拿到令牌,那么就处理这个请求的业务逻辑;
- 如果拿不到令牌,就直接拒绝这个请求。
漏桶算法伪代码实现如下:

如果令牌发放的策略正确,这个系统即不会被拖垮,也能提高机器的利用率。
可以看出令牌桶在应对突发流量的时候,桶内假如有 100 个令牌,那么这 100 个令牌可以马上被取走,而不像漏桶那样匀速的消费。所以在应对突发流量的时候令牌桶表现的更佳。
四:限流算法总结
1:适用场景
上面所述的算法其实只是这些算法最粗略的实现和最本质的思想,在工程上其实还是有很多变型的。
从上面看来好像漏桶和令牌桶比时间窗口算法好多了,那时间窗口算法有啥子用,扔了扔了?
并不是的,虽然漏桶和令牌桶对比时间窗口对流量的整形效果更佳,流量更加得平滑,但是也有各自的缺点(上面已经提到了一部分)。
拿令牌桶来说,假设你没预热,那是不是上线时候桶里没令牌?没令牌请求过来不就直接拒了么?
这就误杀了,明明系统没啥负载现在。
再比如说请求的访问其实是随机的,假设令牌桶每20ms放入一个令牌,桶内初始没令牌,这请求就刚好在第一个20ms内有两个请求,再过20ms里面没请求,其实从40ms来看只有2个请求,应该都放行的,而有一个请求就直接被拒了。
这就有可能造成很多请求的误杀,但是如果看监控曲线的话,好像流量很平滑,峰值也控制的很好。
再拿漏桶来说,漏桶中请求是暂时存在桶内的,这其实不符合互联网业务低延迟的要求。
所以漏桶和令牌桶其实比较适合阻塞式限流场景,即没令牌我就等着,这样就不会误杀了,而漏桶本就是等着,比较适合后台任务类的限流。
而基于时间窗口的限流比较适合对时间敏感的场景,请求过不了您就快点儿告诉我,等的花儿都谢了(给阿姨倒一杯卡布奇诺。为什么我会突然打这句话??)。
2:单机限流和分布式限流
本质上单机限流和分布式限流的区别其实就在于 “阈值” 存放的位置。
单机限流就上面所说的算法直接在单台服务器上实现就好了,而往往我们的服务是集群部署的。
因此需要多台机器协同提供限流功能。
像上述的计数器或者时间窗口的算法,可以将计数器存放至 Redis 等分布式 K-V 存储中。
例如滑动窗口的每个请求的时间记录可以利用 Redis 的 zset 存储,利用ZREMRANGEBYSCORE 删除时间窗口之外的数据,再用 ZCARD计数。
像令牌桶也可以将令牌数量放到 Redis 中。
不过这样的方式等于每一个请求我们都需要去Redis判断一下能不能通过,在性能上有一定的损耗。
所以有个优化点就是 「批量获取」,每次取令牌不是一个一取,而是取一批,不够了再去取一批,这样可以减少对 Redis 的请求。
不过要注意一点,批量获取会导致一定范围内的限流误差。比如你取了 10 个此时不用,等下一秒再用,那同一时刻集群机器总处理量可能会超过阈值。
其实「批量」这个优化点太常见了,不论是 MySQL 的批量刷盘,还是 Kafka 消息的批量发送还是分布式 ID 的高性能发号,都包含了「批量」的思想。
当然,分布式限流还有一种思想是平分,假设之前单机限流 500,现在集群部署了 5 台,那就让每台继续限流 500 呗,即在总的入口做总的限流限制,然后每台机子再自己实现限流。
3:限流的难点
可以看到,每个限流都有个阈值,这个阈值如何定是个难点。
定大了服务器可能顶不住,定小了就“误杀”了,没有资源利用最大化,对用户体验不好。
我能想到的就是限流上线之后先预估个大概的阈值,然后不执行真正的限流操作,而是采取日志记录方式,对日志进行分析查看限流的效果,然后调整阈值,推算出集群总的处理能力,和每台机子的处理能力(方便扩缩容)。
然后将线上的流量进行重放,测试真正的限流效果,最终阈值确定,然后上线。
我之前还看过一篇耗子叔的文章,讲述了在自动化伸缩的情况下,我们要动态地调整限流的阈值很难。
于是基于TCP拥塞控制的思想,根据请求响应在一个时间段的响应时间P90或者P99值来确定此时服务器的健康状况,来进行动态限流。在他的 Ease Gateway 产品中实现了这套算法,有兴趣的同学可以自行搜索。
先预估个大概的阈值,然后不执行真正的限流操作,而是采取日志记录方式,对日志进行分析查看限流的效果,然后调整阈值,推算出集群总的处理能力,和每台机子的处理能力(方便扩缩容)。
然后将线上的流量进行重放,测试真正的限流效果,最终阈值确定,然后上线。
我之前还看过一篇耗子叔的文章,讲述了在自动化伸缩的情况下,我们要动态地调整限流的阈值很难。
于是基于TCP拥塞控制的思想,根据请求响应在一个时间段的响应时间P90或者P99值来确定此时服务器的健康状况,来进行动态限流。在他的 Ease Gateway 产品中实现了这套算法,有兴趣的同学可以自行搜索。
其实真实的业务场景很复杂,需要限流的条件和资源很多,每个资源限流要求还不一样。所以我上面就是嘴强王者。
















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











