复制
* 复制是从服务器拉取二进制日志,而不是主服务器推送二进制日志
复制格式
* 复制格式主要使用的有两种 RBR、SBR、MBR
* RBR 的优点?
- 任何更改都会被记录,是最安全的复制格式
- 主服务器更少的性能消耗(这里解释一下以 InnoDB 为例,INSERT 语句锁了 5 行 STATMENT 也会跟着
锁 5 行,而 ROW 只会记录当前被修改的行,也就是一行一行的记录)
- 从服务器更少的性能消耗(因为从服务器也开启了二进制日志,从主服务器拉取二进制日志复制
也是在进行修改)
* RBR 的缺点?
- 如果存储引擎支持行锁,且一次性锁住了很多行,RBR 将会消耗更多的带宽和存储空间,另外
二进制日志在写入从数据库时是表锁,会阻塞下一次写入
- 如果用户书写的 UDFs 会产生 BLOB 数据,会产生和锁住很多行类似的效应
- 无法提升 MyISAM、ARCHIVE 等非行锁引擎的性能
* 调优指南
MySQL 会自动优化 binlog_row_image 为 minimal 的服务器,具体体现在更少的锁定时间
更小的日志大小
* 为什么二进制日志中看不到 SQL 语句?
MySQL 对 ROW 格式的二进制日志进行 BASE64 编码,需要使用 mysqlbinlog --base64-output=DECODE-ROWS --verbose
查看
* Base64 编码后会比原先大 33%,MySQL 为什么要使用这种方式?
Base64 可以将非 ASCII 字符转为 ASCII 字符,可以更好的进行网络传输,保障日志安全
* 题外话:为什么 Base64 编码后会大 33%?
每 3 字节的数据会转为 4 字节文本数据
* SBR 的优点?
- 体积小
- 用于代码审查的最方便的格式
* SBR 的缺点?
- 不安全,当涉及到 XA 时,SBR 可能会导致从服务器的死锁
* RBR MBR 不会复制临时表
* 日志格式可在运行时进行切换,即使临时表已经被创建,除 MySQL 8.0
* 当临时表使用完毕后,DROP TABLE IF EXISTS 会被写入到二进制日志中
* 当使用 RBL 时,影响非事务表数据的临时表的 DML 会被记录
* 当使用 RBR 时,推荐使用事务性存储引擎,从而避免从主动和被动停止复制导致的不一致
* 在 MySQL 中评估一个语句是否安全可以通过 SBL 如果 SBL 的效果能够被正确的复制则是安全的
复制中的线程
* 以主从复制为例,在整个复制过程中主要运行三个线程:
- 主服务器上的 dump 线程,该线程负责将二进制日志发送到从服务器中
- 从服务器上的 receiver 线程,该线程负责将接受主服务器的二进制日志并将二进制日志写入
中继日志中
- 从服务器上的 applier 线程,该线程负责处理存放在中继日志中的更新
提升复制的性能
* 主备(从)延迟:主库与备库的一致性具有一定的时间差
* 该问题主要由那几个因素产生?
- 主从复制是基于 TCP 的,网络的波动会造成影响
- 不同硬件设备的 IO 速率不一,日志的 IO 速率也会不相同
- 备库只读压力大,便会占用系统大量的 IO 资源
- 主库锁表或锁大量行
* 如何优化?
先解释几个系统变量 sync_binlog、innodb_flush_log_at_trx_commit
sync_binlog:设置为 1 时,每执行一条更新语句就会将二进制日志写入磁盘中,可以防止最后几条
SQL 语句的丢失
innodb_flush_log_at_trx_commit:设置为 1 时,如果事务进行提交便会自动将日志刷新到磁盘
由于从库往往作为只读库出现,因此 ACID 在从库上显得并不是十分重要,因此可以将他们关闭,
以提高从库性能
使用中继数据库
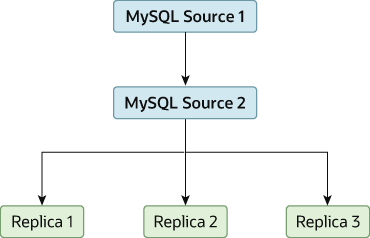
* Source1 作为主库
* Source2 作为 Source1 的从库
* Replica1 Replica2 Replica3 作为 Source2 的从库,本质上是作为 Source1 的从库
* 优点?
- 增加了主库的可用连接,减少了主库压力
使用不同的存储引擎
* 在主从复制中从库往往作为只读库出现,ACID 特性在从库中相对而言并不重要,另外在二进制日志写入从
库时,会进行表锁,在 MySQL 中 MyISAM 和此情况十分搭配
使用不同的从数据库备份不同的表
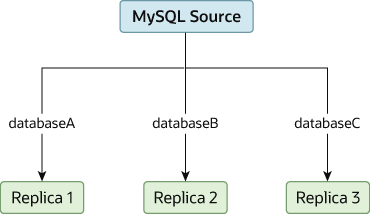
* innodb_file_per_table 为真时才可在 InnoDB 中使用
其他
* 对表进行水平切分,再复制到不同的数据库中,往往根据时间进行,该操作可使用 Kafaka、Sharding-JDBC 来完成或使用两个核心变量 Position 和 File
* 对表进行垂直分片,再复制到不同的数据库中,往往根据访问频率进行,该操作可使用 Kafaka、Sharding-JDBC 来完成
* 分布式 ID 问题?
在分库分表后原先自增的主键又会从零开始增长,而数据在逻辑上依然是个整体,若继续使用主键自增
会造成逻辑不一致
* 如何解决?
- 为每一个分库增加一个 ID 范围,会增加系统复杂度,使用 Oracle 数据库或许会简单一些
- 使用 Redis 保持全局 ID,插入时从 Redis 中取出即可
- 使用 UUID ,不推荐,字符串做主键会造成聚簇索引过大,且为随机函数,只能使用 RBL 或 MBL
- 使用雪花算法,与时钟紧密绑定,相较于 Redis 来说比较简单






















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









