







我的Python足迹
print("hello word!")
#1.整数与浮点
print(123)
print(123-321)
print(0.1+0.2)
#变量
长=10
宽=5
高=2
底面积=长*宽
体积=底面积*高
print(底面积)
print(体积)
#2.字符串,列表,元组
#a字符串
string_1='我是一个字符串'
string_2=''#空字符串
#b列表(list)是python的容器之一,由方括号和方括号括起来的数据构成
list_1=[1,2,3,4,5]
list_2=['a','b','','kk']
list_3=[123,'abc',45,[1,2,'xx']]#也可由多种元素组合起来的列表
#c元组(tuple)是python的容器之一,由小括号和小括号括起来的数据构成
tuple_1=[1,2,3,4,5]
tuple_2=['a','b','','kk']
tuple_3=[123,'abc',45,[1,2,'xx']]#也可由多种元素组合起来的元组
#元组与列表的区别:列表生成以后还可以往里面继续添加数据,也可以删除数据;但是tuple一旦生成就不能修改。
#3.数据的读取
# a指定下下标从0开始
example_string ='我是字符串'
example_list=['我','是','列表']
example_tuple=('我','是','元组')
print(example_string[0])#我
print(example_list[1])#是
print(example_tuple[2])#元组
print(example_tuple[-1])#元组 -1表示最后一个元素以此类推
#b切片操作切了以后还是它自己 格式 变量名[开始位置下标:结束位置下标:步长]
print(example_string[1:3])#读取下标为1和为2的字符
print(example_string[1])#是
print(example_string[2])#字
print(example_string[1:])#读取下标为1的元素和它后面的元素
print(example_string[:3])#读取下标为0,1,2和3的元素
print(example_string[:-1])#取-1表示倒序读取
#c拼接与修改
#c_1字符串与字符串拼接
string_1='你好'
string_2='世界'
string_3=string_1+string_2
print(string_3)
#c_2元组与元组
tuple_1=('abc','exo')
tuple_2=('哇哇哇哇','哈哈哈')
tuple_3=tuple_1+tuple_2
print(tuple_3)#('abc', 'exo', '哇哇哇哇', '哈哈哈')
#c_3列表与列表
list_1=['abc','exo']
list_2=['哇哇哇哇','哈哈哈']#['abc', 'exo', '哇哇哇哇', '哈哈哈']
list_3=list_1+list_2
print(list_3)
#可通过列表的下表修改值 变量名[下标]=新的值
existd_list=[1,2,34,45]
existd_list[1]='new'
print(existd_list)
#列表还可以单独在末尾添加元素
list_4=['python','爬虫']
print(list_4)#['python', '爬虫']
list_4.append('----')
print(list_4)#['python', '爬虫', '----']
list_4.append('酷')
print(list_4)#['python', '爬虫', '----', '酷']
#元组和字符串不能添加新的内容
#4.字典与集合
#a字典就是使用大括号括起来的键(key)值(value)对(key-value对)
dict_1={'superman':'超人内裤外穿','天才':'99%的努力加汗水','xx':0,118:'118是正确答案'}
#可以通过key来读取value a:变量名[key] b:变量名.get(key) c:变量名.get(key,'再找不到key的情况下使用这个值')
example_dict={'superman':'超人内裤外穿','天才':'99%的努力加汗水','xx':0,118:'118是正确答案'}
print(example_dict['天才'])#99%的努力加汗水
print(example_dict.get(118))#118是正确答案
print(example_dict.get('不存在的key'))#None
print(example_dict.get('不存在的key','没有'))#没有
#使用get来读取,如果get只有一个参数,那么在找不到Key的情况下会得到“None”;如果get有两个参数,那么在找不到Key的情况下,会返回第2个参数。
#修改key 变量名[key]='新的值'
existed_dict={'a':123,'b':'爽歪歪'}
print(existed_dict)#{'a': 123, 'b': '爽歪歪'}
existed_dict['b']='我修改了b'
print(existed_dict)#{'a': 123, 'b': '我修改了b'}
existed_dict['c']='我是新来的'
print(existed_dict)#{'a': 123, 'b': '我修改了b', 'c': '我是新来的'}
#b.集合 集合最大的应用之一就是去重。例如,把一个带有重复元素的列表先转换为集合,再转换回列表,那么重复元素就只会保留一个
example_set={1,2,3,'a','b','c'}
duplicated_list={2,2,34,5,54,11,11,'a','a','s'}
unique_list=list(set(duplicated_list)) #使用set()函数把列表转为集合
print(unique_list)#[2, 34, 'a', 5, 54, 's', 11] 注:由于集合与字典一样,里面的值没有顺序,因此使用集合来去重是有代价的,代价就是原来列表的顺序也会被改变。
#5.条件语句
#a.if语句
a=1
b=2
if a+b==3:
print('答案正确') #答案正确
print('以后的代码与以上if无关')#以后的代码与以上if无关
#and or 连接表达式
if 1+1==2 and 2+2==4:
print('答案正确')
if 1+1==3 or 3+3==6:
print('答案正确')
#b.短路效应
# (1)在使用and连接的多个表达式中,只要有一个表达式不为真,那么后面的表达式就不会执行。
# name_list=[]
# if nmae_list and name_list=='张三':
# print('ok')
# (2)在使用or连接的多个表达式中,只要有一个表达式为真,那么后面的表达式就不会执行。
# if 1+1==2 or 2+'a'==3 or 1+1==3:
# print('ok')
#c.多重条件判断
# 对于多重条件的判断,需要使用“if...elif...else...”。其中,“elif”可以有0个,也可以有多个,但是else只能有0个或者1个。
answer=2
if answer==2:
print('true')
else:
print('false')
name='酱鸭饭'
if name=='酱鸭饭':
print('12元')
elif name =='回锅肉':
print('15元')
elif name=='米饭':
print('1元')
elif name=='鸡汤':
print('免费')
else: print('换个店试试')
# if state=='start':
# code=1
# elif state=='running':
# code=2
# elif state=='offline':
# code=3
# elif state=='unknow':
# code=4
# else: code=5
#
# state_dict={'start':1,'running':2,'offlin':3,'unknow':4}
# code=state_dict.get(state,5)
'''----day02'''
#1.函数与类
#a.def定义函数 def函数名(参数1,参数2)……return返回值
def func_example_1():
a=1+1
return a
b=2+2 #同一个函数中return后的代码不会被执行
print(b)
#b.调用函数
def get_input(): #得到用户输入的数据
input_string =input('请输入由的逗号分隔的两个非零整数:')
a_string,b_string=input_string.split(',')
return int (a_string),int(b_string)
def calc(a,b): #计算两个数的和差积商
sum_a_b=a+b
difference_a_b=a-b
product_a_b=a*b
quotient=a/b
return {'sum':sum_a_b,'diff':difference_a_b,'pro':product_a_b,'quo':quotient}
def output(result): #将结果打印出来
print ('两数的和:{}'.format(result['sum']))
print('两数的差:{}'.format(result['diff']))
print('两数的商:{}'.format(result['quo']))
print('两数的积:{}'.format(result['pro']))
# a_int,b_int=get_input()
# result_dict=calc(a_int,b_int)
# output(result_dict)
# def run():
# a,b=get_input()
# result=calc(a,b)
# output(result)
# run()
# def get_input(split_char): #得到用户输入的数据
# input_string =input('请输入由的{}分隔的两个非零整数:'.format(split_char))
# a_string,b_string=input_string.split(split_char)
# return int (a_string),int(b_string)
# a,b=get_input('#')
# print ('第一个数:{},第二个数:{}'.format(a,b))
正则表达式&文件操作
#3.1正则表达式 正则表达式是提取信息的方法之一。
#正则表达式的基本符号
#1.点号“.” 一个点号可以代替除了换行符以外的任何一个字符
#2.星号“*” 一个星号可以表示它前面的一个子表达式(普通字符、另一个或几个正则表达式符号)0次到无限次
#3.问号"?" 问号表示它前面的子表达式0次或者1次
#4.反斜杠“\” 反斜杠在正则表达式里面不能单独使用,甚至在整个Python里都不能单独使用。反斜杠需要和其他的字符配合使用来把特殊符号变成普通符号,把普通符号变成特殊符号
#5.数字"\d" 正则表达式里面使用“\d”来表示一位数字。为什么要用字母d呢?因为d是英文“digital(数字)”的首字母
#6.小括号"()" 小括号可以把括号里面的内容提取出来。
#3.2使用正则表达式
# 1.findall Python的正则表达式模块名字为“re”,也就是“regular expression”的首字母缩写。在Python中需要首先导入这个模块再进行使用
import re #Python的正则表达式模块包含一个findall方法,它能够以列表的形式返回所有满足要求的字符串
content='我的微信密码是:123456,QQ密码是:34643768abc,支付宝密码是:88888888,帮我记住密码'
password_list=re.findall(':(.*?),',content)
print('找到密码{}'.format(password_list))
#re.findall(pattern,string ,flags=0) #pattern表示正则表达式,string表示原来的字符串,flags表示一些特殊功能的标志
#2.search search()的用法和findall()的用法一样
#3.“.*”和“.*? ”的区别
# ①“.*”:贪婪模式,获取最长的满足条件的字符串。
# ②“.*? ”:非贪婪模式,获取最短的能满足条件的字符串。
#3.3正则表达式提取
#1.不需要compile
#2.先抓大再抓小
big_small_text='''
有效用户:
姓名:张三
姓名:李四
姓名:王五
无效用户:
姓名:小爱同学
姓名:小i的爹
'''
# user=re.findall('姓名:(.*?)\n',big_small_text)
# print(user)
user_big=re.findall('有效用户(.*?)无效用户',big_small_text,re.S)
print('user_big:{}'.format(user_big))
user_userful=re.findall('姓名:(.*?)\n',user_big[0])
print('有效用户:{}'.format(user_userful))
#3.括号内和括号外 括号限制提取的内容部分
#3.2Python文件操作
#1.使用Python读取文本文件
# with open ('text.txt',encoding='utf—8') as f:
# content_list=f.readlines()
# #readlines读取所有行,
# # 并以列表的形式返回结果
# # #read 直接把文件里面的全部内容用一个字符串返回
# print(content_list)
#2.使用Python写文本文件
with open('new.txt','w',encoding='utf-8') as f:
#w是英文write的首字母,意思是以写的方式打开文件。这个参数除了为“w”外,还可以为“a”。
# 它们的区别在于,如果原来已经有一个new.txt文件了,使用“w”会覆盖原来的文件,
# 导致原来的内容丢失;而使用“a”,则会把新的内容写到原来的文件末尾
f.write('你好')
f.write('\n==================\n')
f.write('嘿嘿,跟我学爬虫')
a = 21
b = 10
c = 0
c = a + b
print (ord('乘'))
print(chr(20056))
name='乐呵呵'
print(name)
a=1.1
b=2.2
print(a+b)
from decimal import Decimal
print(Decimal('1.1')+Decimal('2.2'))
f1=False
f2=True
print(f1,type(f1))
name='张三'
age=20
print('我叫'+name+'今年'+str(age))
#------将其他类型转为int型-------
# a_1=123
# print(int(a_1),type(a_1))
# a_2='1234.4'
# # print(int(a_2),type(a_2))
# a_2_1='1234'
# print(int(a_2_1),type(a_2_1))
# a_3='hello'
# # print(int(a_3),type(a_3))
# a_4=True
# print(int(a_4),type(a_4))
# a_5=123.345
# print(int(a_5),type(a_5))
# # print(a_1,type(a_1),a_2,type(a_2),a_3,type(a_3),a_4,type(a_4),a_5,type(a_5))
# print('第一个数:')
# num_1=input()
# print('第二个数:')
# num_2=input()
# print(int(num_1)+int(num_2))
#解包赋值
n,b,l=2,1,5
print(n,b,l)
#交换
n,b=b,n
print(n,b,l)
#-------------------
'''双分支结构'''
# print("输入一个数")
# a=int(input())
# if a%2==0:
# print(a,'偶数')
# else:
# print(a,'奇数')
'''多分支结构
90-100 A
80-89 B
70-79 C
60-69 D
0-59 E
小于0或大于100为非法数据
'''
# score=float(input('请输入成绩'))
# if score<=100 and score>=90:
# print('A')
# elif 80<=score<=89:
# print('B')
# elif 70<=score<=79:
# print('C')
# elif 60<=score<=69:
# print('D')
# elif 0<=score<=59:
# print('E')
# else:
# print('非法数据')
# '''从键盘输入两个数比较大小'''
# num_1=int(input('第一个数:'))
# num_2=int(input('第二个数:'))
# if num_1 >= num_2:
# print(num_1,'大于等于',num_2)
# else:
# print(str(num_1)+'小于'+str(num_2))
#-----使用条件表达式比较
# print((str(num_1)+'大于等于'+str(num_2)) if num_1>=num_2 else str(num_1)+'小于'+str(num_2) )
#-----pass占位符
age=int(input('请输入年龄:'))
if age:
print('年龄',age)
else:
print('不能为零')Python中的循环结构
# ----range的三种创建方式
'''第一种创建方式,只有一个参数'''
r=range(10)#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],默认从0开始,默认相差1称为步长
print(r)#range(0, 10)
print(list(r))#用于查看range中的整数序列
'''第二种创建方式,给了两个参数'''
r=range(1,10)
print(list(r))#[1, 2, 3, 4, 5, 6, 7, 8, 9]
'''第三种创建方式,给了三个参数'''
r=range(1,10,2) #range(start,stop,step)
print(list(r))#[1, 3, 5, 7, 9]
print(10 in r)
print(10 not in r)
'''循环结构'''
'''while循环的执行流程
初始化变量
条件判断
条件执行体
改变变量'''
#计算1-5的和
sum=0 #用于存储累加和
''' 初始化变量'''
a=0
'''条件判断 '''
while a<=5:
'''循环体'''
sum+=a
'''改变变量'''
a+=1
print('和',sum)
'''计算1-100之间的偶数和'''
'''while循环'''
sum=0
a=0
while a<=100 :
if not bool (a%2):
sum+=a
a+=1
print('和',sum)
'''for循环'''
sum=0
for i in range(0,101,2):
# if not bool(i%2):
# print(i)
sum+=i
print(sum)
'''100-999之间的水仙花数'''
for i in range(100,1000):
ge=i%10
shi=i//10%10
bai=i//100
if ge**3+bai**3+shi**3==i:
print("水仙花数",i)
'''打印矩形'''
for item in range(3):#行数
for j in range(4):
print('*',end='\t') #不换行
print() #打行
'''打九九乘法表'''
for i in range(1,10):
for j in range(1,i+1):
print(str(j)+'*'+str(i)+'='+str(i*j),end='\t')
print()列表
a=10
lst=['hello','world',100]
print(id(lst))
print(type(lst))
print(lst)
'''创建列表的第一种方式,使用[]'''
lst=['hello','world',100]
'''创建列表的第二种方式,使用内置函数list()'''
lst2=list(['hello','world',98])
print('添加元素前',id(lst2),lst2)
'''向列表里添加元素'''
lst2.append(886) #向列表的末尾添加一个元素
print('添加元素后',id(lst2),lst2) #添加前后标识列不变
#lst2.append(lst) #将lst作为一个元素添加到列表的末尾
lst2.extend(lst) #向列表的末尾添加多个元素
print(lst2)
lst2.insert(1,666)#任意位置添加一个元素
print(lst2)
lst2[1:]=lst #切片 在列表的任意位置添加至少一个元素
print(lst2)
'''向列表删除元素'''
lst=[10,20,30,40,50,60,100]
lst.remove(20)#从列表中移除一个元素,如果不存在会报错
print(lst)
lst.pop(1) #pop()根据索引移除元素
lst.pop() #如果不指定参数移除最后一个元素
print(lst)
print('-----切片操作——删除至少一个元素,将产生一个新的列表对象------')
new_list=lst[1:3]
print('原列表',lst)
print('新列表',new_list)
'''直接删除'''
lst[1:3]=[]
print(lst)
'''清除列表中的所有元素'''
lst.clear()
print(lst)
'''del将列表直接删除'''
del lst
#print(lst) #lst' is not defined(defined 定义)
'''列表元素的排序操作'''
lst_1=[100,23,67,89,66,889,907]
print('对排序',lst_1)
lst_1.sort()#默认升序
print(lst_1)
lst_1.sort(reverse=True) #降序
print(lst_1)
print('------使用内置函数sorted()对列表进行排序--------')
lst_1=[100,23,67,89,66,889,907]
print('原列表',lst_1)
#开始排序
new_list_1=sorted(lst_1)
print(lst_1)
print(new_list_1)
#降序
new_list_1=sorted(lst_1,reverse=True)
print(lst_1)
print(new_list_1)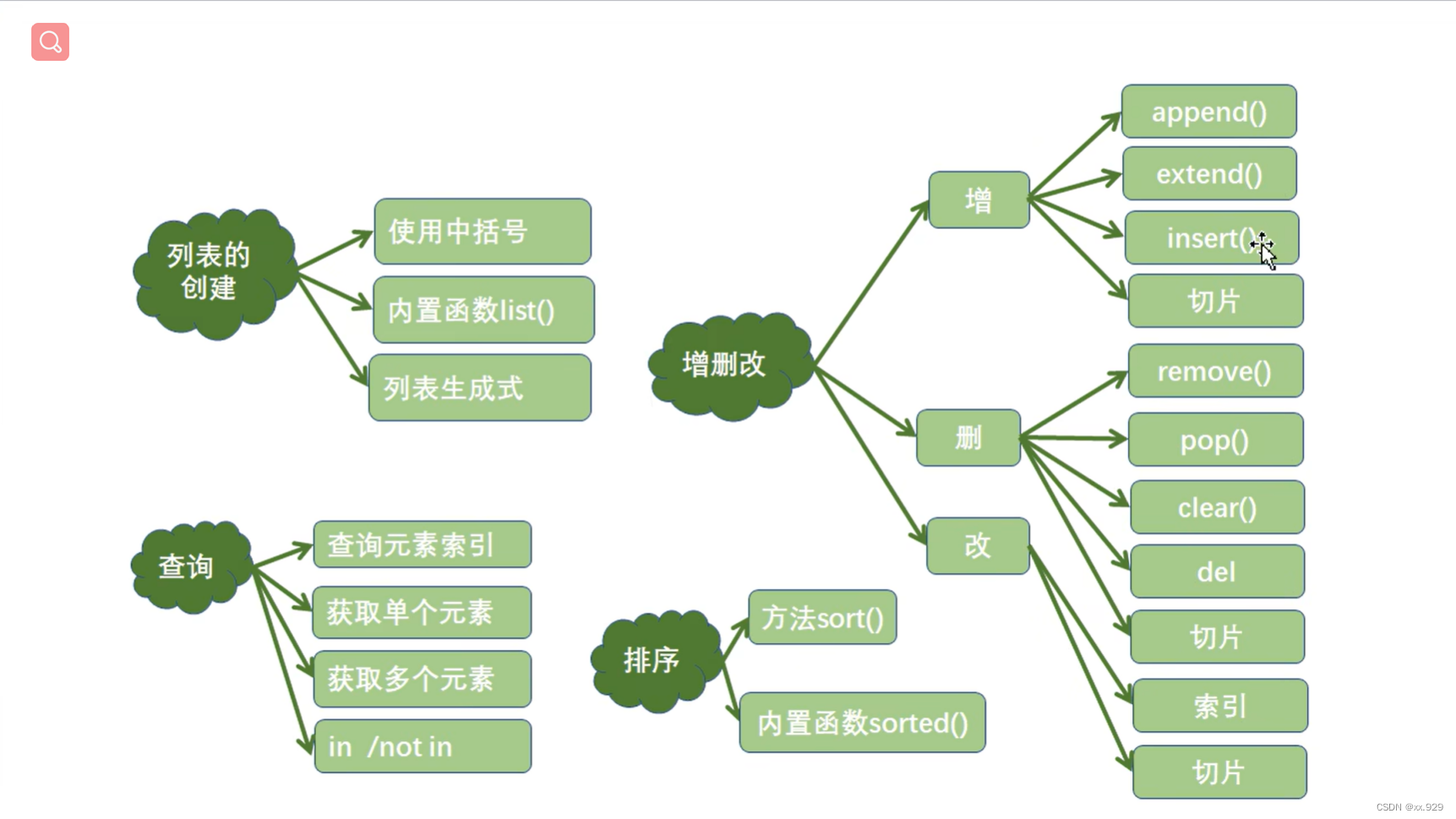
字典的创建方式
'''使用{}创建字典'''
score={'张三':100,'李四':98,'王五':66}
print(score)
'''第二种创建dict()'''
student=dict(name='张三',score=99)
print(student)
'''空字典'''
d={}
print(d)
'''获取字典的元素'''
print(score['张三'])
print(score.get('成六',99))
#判断存在
print('张三' in score) #True
print('张三' not in score) #False
#删除
del score['张三']
print(score)
#新增
score['老八']=99
print(score)
#修改
score['老八']=123
print(score)
#打包
items=['Fruits','Books','Others']
prices=[96,87,66,200]
d={item.upper():price for item ,price in zip(items,prices) }
print(d) 
集合
s1={1,2,3,4,5,6,7}
s2={7,6,5,4,3,2,1}
s2=set({7,6,5,4,3,2,1})
print(s1!=s2) #两个集合是否相等
s3={1,2,3,4,5}
s4={1,2,3,4}
print(s4.issubset(s3)) #s4是s3的子集
print(s3.issuperset(s4)) #s3是s4的超集
print(s3.isdisjoint(s1)) #是否存不在交集
'''集合的数学操作'''
s_1={1,2,3,4,5}
s_2={2,3,4,5,6,7}
print(s_1.intersection(s_2))
print(s_1 & s_2) #交集操作
print(s_1.union(s_2))
print(s_1 | s_2) #并集操作
print(s_2.difference(s_1))
print(s_2-s_1) #差集
print(s_1.symmetric_difference(s_2))
print(s_1^s_2) #对称差集

字符串的常用操作集合
'''字符串的查询操作'''
s='hello,hello'
print(s.index('lo')) #3
print(s.find('lo'))#3
print(s.rindex('lo'))#9
print(s.rfind('lo'))#9
#print(s.index('k')) #ValueError: substring not found
print(s.find('k')) #-1
#print(s.rindex('k')) #ValueError: substring not found
print(s.rfind('k')) #-1
'''字符串的大小写转化操作'''
s='Hello Python'
print(s.upper())#HELLO PYTHON
print(s.lower())#hello python
print(s.swapcase())#hELLO pYTHON 反转字符串中的大小写
print(s.capitalize())#Hello python 首字母大写
print(s.title())#Hello Python
'''字符串内容对齐操作'''
s='hello,python'
'''居中对齐'''
print(s.center(20,'#'))####hello,python####
'''左对齐'''
print(s.ljust(20,'*'))#hello,python********
print(s.ljust(20))
'''右对齐'''
print(s.rjust(20,'#'))
print(s.rjust(20)) # hello,python
'''右对齐,使用0进行填充'''
print(s.zfill(20))
print(s.zfill(10))
print('-8910'.zfill(8))
'''字符串的分割'''
s='hello world python'
lst=s.split()
print(lst) #['hello', 'world', 'python']
s_1='hello|world|python'
print(s_1.split(sep='|')) #['hello', 'world', 'python']
print(s_1.split(sep='|',maxsplit=1)) #['hello', 'world|python']
print('''rsplit()从右侧开始辟分''')
print(s.rsplit())
print(s_1.rsplit('|'))
print(s_1.rsplit(sep='|',maxsplit=1)) #['hello|world', 'python']
'''判断字符串操作'''
s='hello,python'
'''isidentifier()判断字符串是否合法'''
print('1.',s.isidentifier()) # False
print('2.','hello'.isidentifier()) # False
print('3.','张三_123'.isidentifier()) #True
'''isspace()判断字符串是否全部由空白字符组成'''
print('5.','\t'.isspace()) #True
'''isalpha()判断字符串是否全部由字母组成'''
print('6.','abc'.isalpha())#True
'''isdecimal()判断字符串是否全部由十进制的数字组成'''
print('7.','145'.isdecimal())#True
'''isnumeric()判断字符串是否全部由数字组成'''
print('8.','12345六'.isnumeric())#True
'''isalnum()判断字符串是否全部由字母和数字组成'''
print('9.','12345六张三'.isalnum())#True
'''字符串操作的其他方法'''
'''字符串替换replace()'''
s='hello,python'
print(s.replace('python','c#')) #hello c#
s_1='hello,python,python,python'
print(s_1.replace('python','c#',2)) #hello,c#,c#,python
'''字符串的合并join()'''
lst=['hello','java','c']
print('|'.join(lst)) #hello|java|c
print(''.join(lst)) #hellojavac
t=('hello','java','c')
print(''.join(t))#hellojavac
print('*'.join('hello'))#h*e*l*l*o
字符串的比较操作 &字符串的切片
print('apple'>'app') #True
print('apple'>'banana') #False
print(ord('a'),ord('c')) #97 99
print(chr(97),chr(98)) #a b
'''==与is的区别
==比较的是 value
is比较的是id'''
a=b='python'
c='python'
print(a is c) #True
print(a==c) #True
'''字符串的切片'''
s='hello,python'
s_1=s[:5]
s_2=s[6:]
print(s_1)
print(s_2)
s_3='!'
print(s_1+s_3+s_2)
格式化字符串
#1.%占位符
name='张三'
age=20
print('我叫%s,今年%d'%(name,age)) #%s字符串 %i或%d整数 %f浮点数
#2.{}占位符
print('我叫{0},今年{1}岁'.format(name,age))
#3.f-string
print(f'我叫{name},今年{age}')
print('%10d' % 99) # 99 10表示宽度
print('%.3f' %3.1415926) #3.142 3表示小数点后三位
print('%10.3f' %3.1415926) # 3.142 一共总宽度为10 ,小数点后3位
print('hellohello')
print('{0:.3}'.format(3.1415926)) #3.14 .3表示的是一共是3位小数
print('{:.3f}'.format(3.1415926)) #3.142 .3f表示是3位小数
print('{:10.3f}'.format(3.1415926)) # 3.142 同时设置宽度和精度,一共是10位,3位小数
字符串的编码
s='天涯共此时'
print(s.encode(encoding='GBK'))#在GBK这种编码格式中一个中文占两个字节
print(s.encode(encoding='UTF-8'))#在UTF-8中一个中文占三个字节
#解码
#byte代表就是一个二进制数据
byte=s.encode(encoding='GBK') #编码
print(byte.decode(encoding='GBK')) #解码
byte=s.encode(encoding='UTF-8')
print(byte.decode(encoding='UTF-8'))函数
'''函数的创建和调用'''
def calc(a,b):
c=a+b
return c
result=calc(10,29)
print(result)
'''函数参数传递的内存分析'''
def fun(arg1,arg2):
print('arg1',arg1) #11
print('arg2',arg2) #[22, 33, 44]
arg1=100
arg2.append(10)
print('arg1',arg1) #100
print('arg2',arg2) #[22, 33, 44, 10]
n1=11
n2=[22,33,44]
fun(n1,n2)
print(n1,n2) #11 [22, 33, 44, 10]
'''在函数调用过程中,进行参数的传递
如果是不可变对象,在函数体的修改不会影响实参的值 arg1的值修改为100,不会影响n1的值
如果是可变对象,在函数体的修改会影响到实参的值 arg2的修改,append(10)会影响n2的值'''
'''函数的返回'''
def fun(num):
odd=[]
even=[]
for i in num:
if i%2:
odd.append(i)
else:
even.append(i)
return odd,even
'''函数的调用'''
lst=[1,2,3,4,5,6,7,8]
print(fun(lst)) #([1, 3, 5, 7], [2, 4, 6, 8])
'''函数的返回值
(1)如果函数没有返回值 return 可以不写
(2)函数的返回值,如果是一个,直接返回类型
(3)函数的返回值,如果是多个,返回的结果为元组
'''
print('-----')
'''函数参数定义'''
def fun(a,b=10): #b为默认值参数
print(a,b)
#函数的调用
fun(100) #100 10
fun(10,200) #10 200
print('hello',end='\t')
print('python')
'''个数可变的位置参数'''
def fun(*args): #函数定义时的 可变的位置参数
print(args)
fun(10)#(10,)
fun(10,30)#(10, 30)
def fun1(**args):
print(args)
fun1(a=10)#{'a': 10}
fun1(a=20,c=30)#{'a': 20, 'c': 30}
def num(a,b,c):
print('a',a)
print('b',b)
print('c',c)
num(1,2,3)
lis=[11,22,33]
num(*lis)#在调用时,将列表中的每一个元素都转化为位置实参传入
dic={'a':100,'b':200,'c':300}
num(**dic)#在调用时,将字典中的键值对都转化为关键字实参
#变量的作用域
def fun(a,b):
c=a+b #c,就称为局部变量
print(c)
name='张三' #name,全局变量
print(name)
def fun():
print(name)
fun()递归函数
def fac(n):
if n==1:
return 1
else:
return n*fac(n-1)
print(fac(6)) #720
'''斐波那契'''
def fib(n):
if n==1 or n==2 :
return 1
else:
return fib(n-1)+fib(n-2)
print(fib(6)) #8
'''输出前6项'''
for i in range(1,7):
print('第',i,'项:',fib(i))
'''第 1 项: 1
第 2 项: 1
第 3 项: 2
第 4 项: 3
第 5 项: 5
第 6 项: 8''''''类的创建'''
class Student:
native_pace='吉林' #类属性
def __init__(self,name,age):
self.name=name #self.name 称为实体属性, 进行一个赋值的操作,将局部变量的name的值赋给实体属性
self.age=age
#实例方法
def eat(self):
print(self.name,'吃饭')
#静态方法
@staticmethod
def method():
print('我是静态方法,用@staticmethod修饰')
#类方法
@classmethod
def cm(cls):
print('我是类方法,用@classmethod修饰')
#在类之外定义的称为函数,在类内称为方法
def drink():
print('喝水')
'''创建Student类的对象'''
stu_1=Student('张三',20)
stu_2=Student('李四',30)
stu_1.eat() #对象名.方法名
print(stu_1.name)
print('-----------')
Student.eat(stu_1) #调用Student中的eat方法
#类名.方法名(对象名)
#动态绑定数据
stu_1.gender='女'
print(stu_1.name,stu_1.age,stu_1.gender)
stu_1.eat()
def show():
print('定义在类之外的,称函数')
stu_1.show=show
stu_1.show()
stu_2.show=show()
#封装
class Student:
def __init__(self, name, age,gender):
self.name = name # self.name 称为实体属性, 进行一个赋值的操作,将局部变量的name的值赋给实体属性
self.age = age
self.__gender=gender #性别不希望在类的外部被使用,所以加__
def show(self):
print(self.name,self.age,self.__gender)
stu=Student('张三',20,'男')
stu.show() #张三 20 男
print(dir(stu)) #['_Student__gender', '__class__', '__delattr_
print(stu._Student__gender) #男
#继承
class Person(object):
def __init__(self,name,age):
self.name=name
self.age=age
def info(self):
print(self.name,self.age)
class Student(Person):
def __init__(self,name,age,stu_no):
super().__init__(name,age)
self.stu_no=stu_no
def info(self): #重写
super().info()
print(self.stu_no)
class Teacher(Person):
def __init__(self,name,age,teacher_no):
super().__init__(name,age)
self.teacher_no=teacher_no
def info(self):
super().info()
print(self.teacher_no)
stu=Student('张三',20,'1026')
teach=Teacher('李四',34,'001')
print('----')
stu.info()
print('-----')
teach.info()
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def __str__(self):
return '我的名字是{0},今年{1}岁'.format(self.name,self.age)
stu=Student('张三',20)
print(dir(stu))
print(stu) #我的名字是张三,今年20岁 默认调用__str__
print(type(stu)) #<class '__main__.Student'>
class Animal(object):
def eat(self):
print('动物会吃')
class Dog(Animal):
def eat(self):
print('狗吃肉')
class Cat(Animal):
def eat(self):
print('猫吃鱼')
class Person:
def eat(self):
print('人吃五谷杂粮')
#定义一个函数
def fun(obj):
obj.eat()
#开始调用函数
fun(Cat())
fun(Dog())
fun(Animal())
print('---')
fun(Person())















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









