







深度学习前置知识:
线性映射的复合 依然是 线性映射。
前馈神经网络:
L:神经网络的层数
:第l层的神经元的净输入
: 第l层神经元的输出
关于神经元计算:
全连接:l+1的第i个神经元和 l 层的第 j个神经元 连接
关于矩阵计算:
关于数据处理:
原始数据输入->线性变化(Y=AX+b)->激活函数(Z=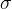 (Y))->神经元得到输入输出->所有神经元后计算loss
(Y))->神经元得到输入输出->所有神经元后计算loss
pytorch中backward():反向传播计算中自动求梯度
均方误差作为目标函数: E损失函数
损失函数E -> 激活函数结果out -> 线性函数结果 net
再计算完损失函数后,要根据损失函数的结果再把前面的所有参数更新一遍(为了找到模型的最优参数),包括权重参数 w , 偏置 b 。
1.先更新离输出结果 近的
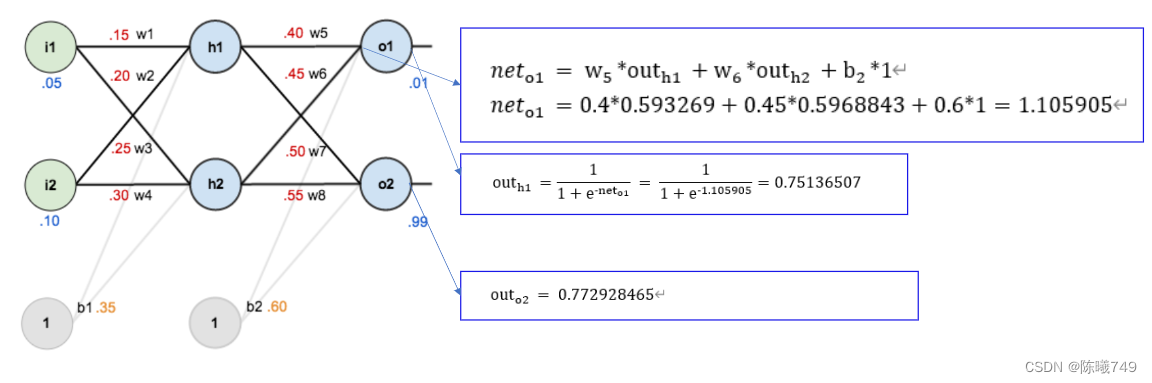

更新 和 更新
不同 。距离输入结果的深度不同,所求导数也不同。
2.再更新
因为 和 损失函数 E 的复合关系(就像复合函数一样),因此我们想求 E 关于
的梯度 ,就要把关系一层层拆开(借助中间函数求梯度)。
(1).由上面的图简单分析,损失函数E由两个神经元的输出结果决定()。
求梯度,则是


不理解为什么要拆开算???懂了懂了

更新 。
以学习率 更新权重参数: (学习率)
再更新 偏置梯度 :
sigmoid激活函数:
求导:
更新完权重参数,即完成了一次向前传播和 反向传播 。
卷积神经网络:
全连接神经网络的缺点:参数爆炸
图像本身信息“局部相关行”强
CNN超参:Kernel size , Stride , Padding
卷积与池化 :平均池化,最大池化
在池化时导致的失真问题:论文阅读 我们通常用最大池化。
框架学习建议:要学会利用官网
关于实例:
Python 内置函数: enumerate() 函数
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
Python 2.3. 以上版本可用,2.6 添加 start 参数。
>>> seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]CrossEntropyloss: 交叉熵损失函数
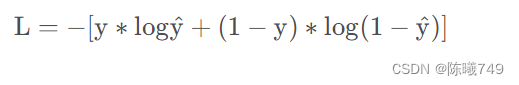
在pytorch中, CrossEntropyloss()把输出结果进行sigmoid(将数据设置到0-1之间),随后再放入到传统的交叉熵损失函数中,就会得到结果。来源
paddle的 nll_loss 函数:相关了解
optimizer : 优化器 paddle.optimizer.Adam 关于Adam , 关于动量
Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使参数比较稳定。
CSV文件:逗号分隔文件 (Comma Separated Values) 的首字母英文缩写,是一种用来存储数据的纯文本格式,通常用于电子表格或数据库软件。
Linear:线性分类器
epoch、iteration 和 batch_size :
(1)batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
(2)iteration:1个iteration等于使用batchsize个样本训练一次;
(3)epoch:1个epoch等于使用训练集中的全部样本训练一次;
举个例子,训练集有1000个样本,batchsize=10,那么:
训练完整个样本集需要:100次iteration,1次epoch。来源
关于项目逻辑:
数据准备:解压数据集food-11
环境配置与安装
导入相关包 与定义数据集
设置batch_size 并 加载 数据集与验证集
模型构建 :卷积神经网络时常使用 “Conv+BN+激活+池化” 作为一个基础block ,我们可以将多个block堆叠在一起,进行特征提取,最后连接一个Linear层, 实现图片分类。
print('start training...')
for epoch in range(epoch_num): #循环epoch次数
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
# 模型训练
model.train()
for img, label in train_loader():
optimizer.clear_grad()
pred = model(img)
step_loss = loss(pred, label)
step_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(pred.numpy(), axis=1) == label.numpy())
train_loss += step_loss.numpy()[0]
# 模型验证
model.eval()
for img, label in val_loader():
pred = model(img)
step_loss = loss(pred, label)
val_acc += np.sum(np.argmax(pred.numpy(), axis=1) == label.numpy())
val_loss += step_loss.numpy()[0]














 974
974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









