






import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get('http://www.baidu.com/')
#driver.find_element(by=By.ID,value='kw').send_keys('python')
#driver.find_element(By.NAME,'wd').send_keys('csdn')
#driver.find_element(By.CLASS_NAME,'s_ipt').send_keys('csdn')
driver .find_element(By.LINK_TEXT,'新闻').click()
time.sleep(5)
driver.quit()首先,查找页面元素以及标签:http://www.baidu.com/
按下F12可查找页面元素,也可使用鼠标移动到需要找的元素上面,鼠标右键点击检查即可
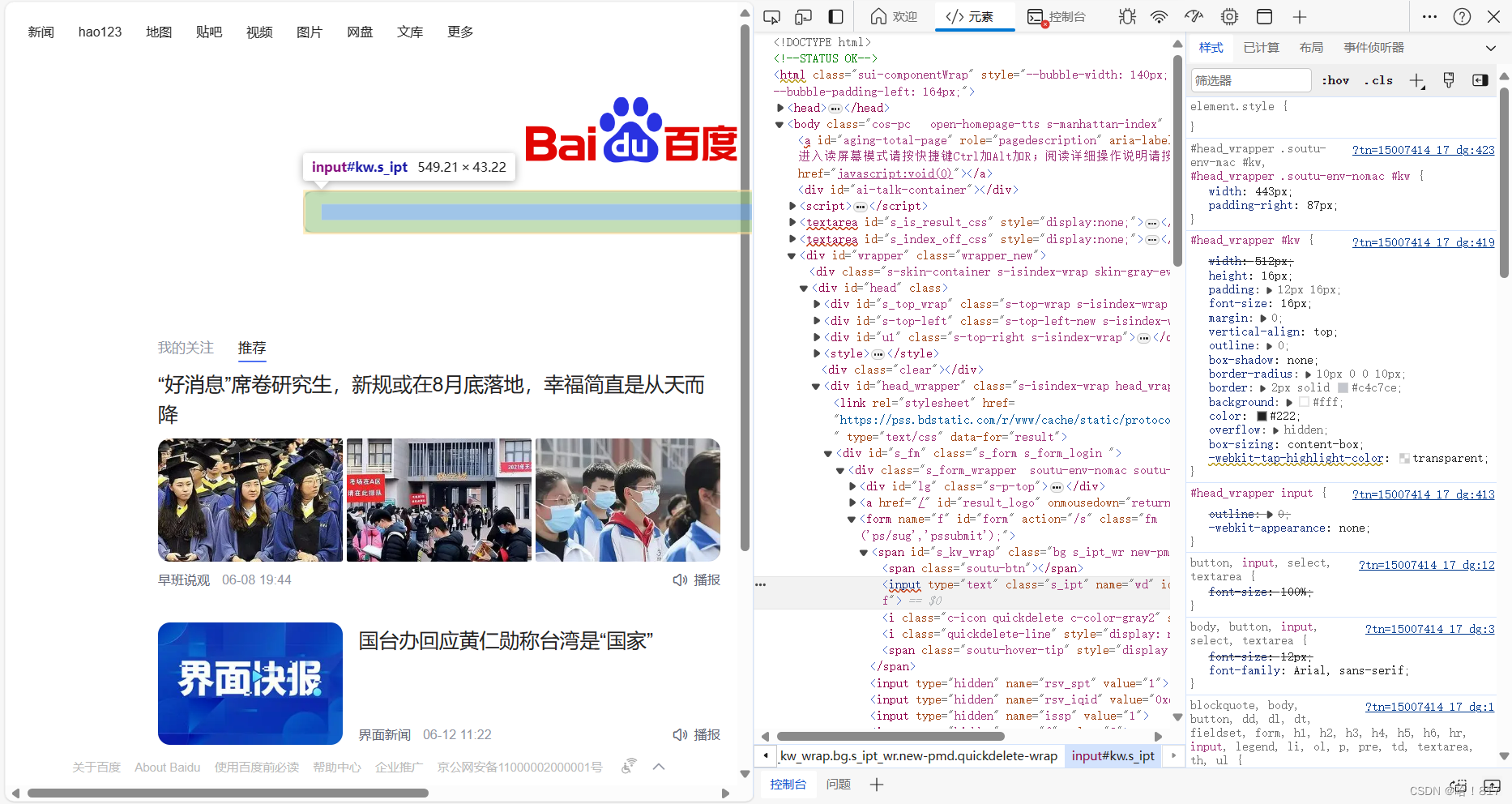
右图颜色加深区域就是需要找的目标元素代码
下面通过Xpath查找元素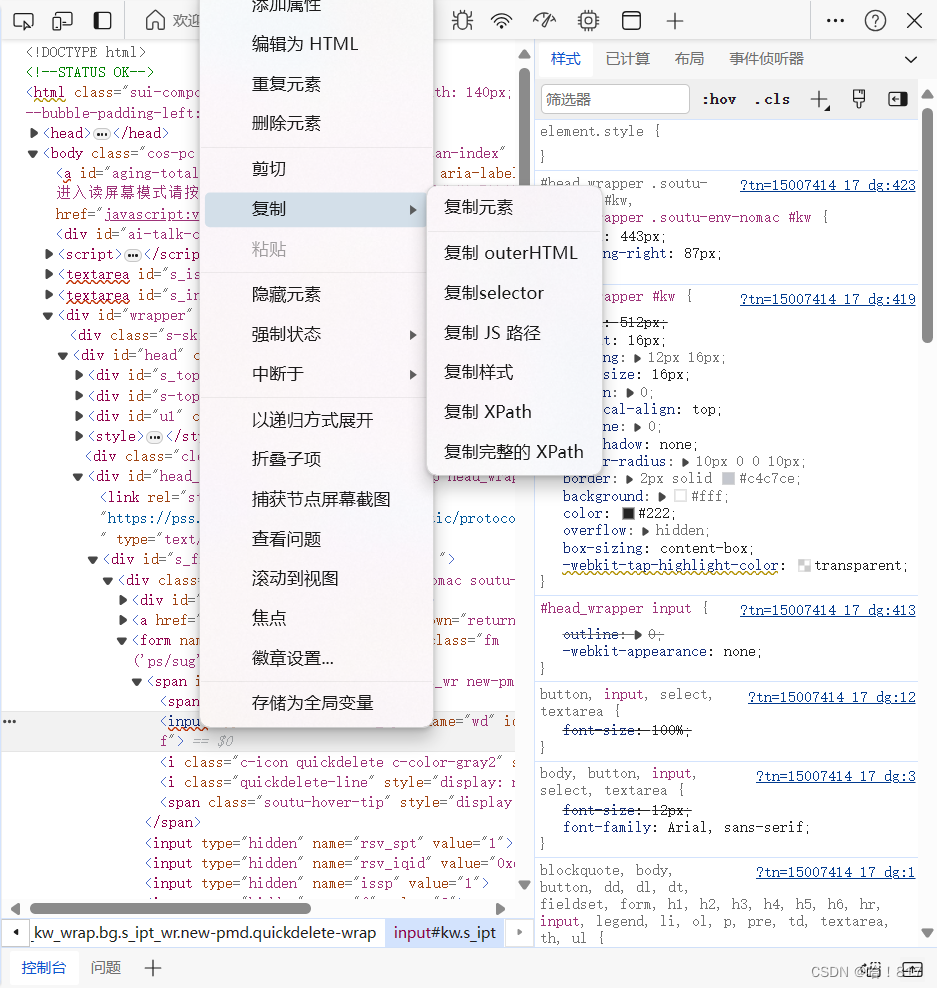
在深颜色区域鼠标右键,复制XPath,下面代码实现一下
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get('http://www.baidu.com/')
driver.implicitly_wait(10)
driver.find_element(By.XPATH,'/html/body/div[2]/div[1]/div[3]/a[1]').click()
time.sleep(5)
driver.quit()
这里有一个需要注意的就是,
driver.implicitly_wait(10)#隐式等待,如果没有这行代码就会出错,因为页面加载的比较慢,需要等到页面加载完成再进行点击操作
XPath按绝对路径查找要比按照标签查找要快很多,你可以根据上面两个代码验证一下,以及上面代码出现报错的,多试几次就可以运行成功,有时候网页会有拒绝服务的功能。或者加长隐式等待时间,又或者可以更换XPath路径,不使用完整的路径而是使用XPath的相对路径,需要注意的是这种方法极其不稳定,报错与否看运气,哈哈哈哈
补充一点:因为页面元素标签中的id值具有唯一性,所以用id操作selenium准确度比较高
另外还有一些用法读者可自行试试,可以跳转到源看看用法,本章只是告诉读者们最开始遇到的代码以及问题















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









