







--累计求和
select earnmonth,
sum(personincome),
sum(sum(t.personincome)) over(order by t.earnmonth rows between unbounded preceding and current row)
from earnings t
group by earnmonth
--order by earnmonth,area nulls last;

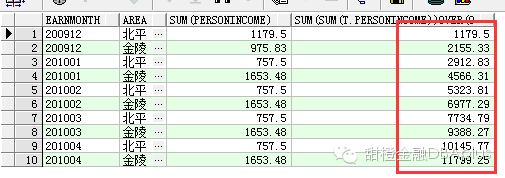
select earnmonth,
area,
sum(personincome),
sum(sum(t.personincome))over(order by t.earnmonth, t.area rows between unbounded preceding and current row)
from earnings t
groupby earnmonth, area
--order by earnmonth,area nulls last;
--滚动求和:求前一行,当前行,后一行的和
select earnmonth,
area,
sum(personincome),
sum(sum(t.personincome))over(order by t.earnmonth, t.area rows between 1 preceding and 1 following)
from earnings t
groupby earnmonth, area
--order by earnmonth,area nulls last;

--累计求平均值
select earnmonth,
sum(personincome),
avg(sum(t.personincome))over(order by t.earnmonth rows between unbounded preceding and current row)
from earnings t
groupby earnmonth
--order by earnmonth,area nulls last;

select earnmonth,
area,
sum(personincome),
avg(sum(t.personincome))over(order by t.earnmonth, t.area rows between unbounded preceding and current row)
from earnings t
groupby earnmonth, area
--order by earnmonth,area nulls last;

--求前一行到后一行的移动平均值
select earnmonth,
area,
sum(personincome),
avg(sum(t.personincome))over(order by t.earnmonth, t.area rows between 1 preceding and 1 following)
from earnings t
groupby earnmonth, area
--order by earnmonth,area nulls last;

---返回窗口的第一行
select earnmonth,
area,
sum(personincome),
first_value(sum(t.personincome))over(order by t.earnmonth, t.area rows between 1 preceding and 1 following)
from earnings t
groupby earnmonth, area
--order by earnmonth,area nulls last;

--返回窗口的最后一行
select earnmonth,
area,
sum(personincome),
LAST_VALUE(sum(t.personincome))over(order by t.earnmonth, t.area rows between 1 preceding and 1 following)
from earnings t
groupby earnmonth, area
--order by earnmonth,area nulls last;

--获取当前窗口的前x行的值
select earnmonth,
area,
sum(personincome),
lag(sum(t.personincome),2)over(order by t.earnmonth,t.area)
from earnings t
groupby earnmonth, area
--order by earnmonth,area nulls last;

--获取当前窗口的后x行的值
select earnmonth,
area,
sum(personincome),
lead(sum(t.personincome),2)over(order by t.earnmonth,t.area)
from earnings t
groupby earnmonth, area
--order byearnmonth,area nulls last;

说明:Lag和Lead函数可以在一次查询中取出某个字段的前N行和后N行的数据(可以是其他字段的数据,比如根据字段甲查询上一行或下两行的字段乙),原来没有分析函数的时候采用子查询方法,但是比较麻烦,惭愧,我用子查询有的还查不出来呢。
语法如下:
lag(value_expression [,offset] [,default])over ([query_partition_clase] order_by_clause);
lead(value_expression [,offset] [,default]) over ([query_partition_clase] order_by_clause);
其中:
value_expression:可以是一个字段或一个内建函数。
offset是正整数,默认为1,指往前或往后几点记录.因组内第一个条记录没有之前的行,最后一行没有之后的行,
default就是用于处理这样的信息,默认为空。
再讲讲所谓的开窗函数,依本人遇见,开窗函数就是 over([query_partition_clase] order_by_clause)。比如说,我采用sum求和,rank排序等等,但是我根据什么来呢?over提供一个窗口,可以根据什么什么分组,就用partition by,然后在组内根据什么什么进行内部排序,就用 order by
-------数值分析
cume_dist()和PERCENT_RANK()用法
下面这些函数计算某个值在一组有序数据中的累计分布(cumulative distribution)
1) cume_dist()
计算结果为相对位置/总行数。返回值(0,1]。
例如在一个5行的组中,返回的累计分布值为0.2,0.4,0.6,0.8,1.0;
注意对于重复行,计算时取重复行中的最后一行的位置。
例1:
SELECT t.*,cume_dist()over(order by empno) as cumedist FROM emp t;

观察红色标注部分的值,看看与下面的结果有什么关系

例2,先分组,然后按照每个组做累积分布
SELECT t.*,cume_dist()over(partition by deptno orderby empno)as cumedist FROM emp t;

下面这些函数计算某个值在一组有序数据中的累计分布(cumulative distribution)
例3:
SELECT cume_dist(2975) within group(order by sal) as cumedist FROM emp t;

那么,为什么结果是0.8呢?
再观察下面结果:
SELECT t.*,cume_dist()over(order by sal) as cumedist FROM emp t;

然后看看0.0714285714285714、0.785714285714286、和0.8这几个数据与下面的计算方法有什么不同?

规律:如果是计算指定数值的累计分布,那么计算方法为
(相对位置)/(参照位置+1)
即 (12)/(14+1)=0.8
a)作为聚合函数的用法
语法:cume_dist(expr) with group (order by exp)
cume_dist()用参数中的指定的数据构造一条假定的数据并插入到现存行中,
然后计算这条假定数据在所有行中的相对位置。
例如下面的查询中,emp中总共有14行数据,
假定的数据(deptno=20,sal=4000)会插入到第9行,
因此相对位置 9/(14+1)=0.6。
SELECT t.*,cume_dist()over(order by deptno,sal) as cumedist FROM emp t;

select cume_dist(20,4000)
within group (order by deptno, sal)cume_dist
from emp;
CUME_DIST
----------
.6
假定的数据(deptno=20,sal=4000)会插入到第9行.
因此,相对位置 9/(14+1)=0.6
b)作为分析函数的用法
语法:cume_dist() over([partition_clause] order_by_clause)
例如计算每个人在本部门按照薪水排列中的相对位置。
select ename,
sal,
deptno,
cume_dist()over(partition by deptno order by sal) cume_dist
from emp;

与此类似的函数,PERCENT_RANK,先猜猜这个函数做什么用?
和cume_dist的不同点在于计算分布结果的方法。
计算方法为 (相对位置-1)/(总行数-1),
因此第一行的结果为0。返回值[0,1]。
例如在一个5行的组中,返回的累计分布值为0,0.25,0.5,0.75,1.0;
注意对于重复行,计算时取重复行中的第一行的位置
例1
SELECT t.*,percent_rank()over(order by deptno,sal) as cumedist FROM emp t;

红色标注的数据=(2-1)/(14-1)=0.0769230769230769
作为聚合函数的用法
语法:percent_rank(expr) with group (order by exp)
下面的例子中,类似cume_dist,假定数据(deptno=20,sal=4000)会插入到第9行,
计算相对位置 (9-1)/((14+1)-1)=0.57
select percent_rank(20, 4000) within group(order by deptno, sal) percent_rank
from emp;

作为分析函数的用法
语法: percent_rank() over([partition_clause] order_by_clause)
例如计算每个人在本部门按照薪水排列中的相对位置。
例
select ename,
sal,
deptno,
percent_rank() over(partition by deptno order by sal) percent_rank
from emp;

类似的数值分析函数还有percentile_disc()、percentile_cont()、ntile()、ratio_to_report(),感兴趣的话可以查阅相关资料。
select sal, deptno from emp;
1下面用 pivot实现数据聚合行转列
select *
from (select sal, deptno from emp) pivot(sum(sal) as sum_sal for(deptno)in(10,20,30));
行转列

在这个例子中,工资按照指定部门做聚集后,成为独立的列显示出来。有几个部门,就有几列;而总是只有一行。即是说,达到了行转列的效果。这种效果的报表在BI/DW应用中很常见。
注意:IN语句是必须的。也就是说,在运行SQL之前必须知道deptno
2按照多个列作行转列
select *
from (select sal, deptno, mgr from emp) pivot(sum(sal) for(deptno, mgr)in((20, 7902), (30, 7698), (10, 7839)));

SELECT sal, deptno, mgr
FROM emp
where (deptno, mgr) in ((20, 7902), (30,7698), (10, 7839))

这个SQL查询按照指定部门和经理的组合聚合后的工资。相当于按照两个维度来做聚集。
两个pivot,这时列数增加1倍。但是for() in()内容需要保持一致,否则Oracle无法确定你的列名,列的数据类型
3求各部门总工资和平均工资:
select *
from (select sal, deptno from emp) pivot(sum(sal) sumsal, avg(sal)avgsal for(deptno) in(10, 20,30));

select deptno,sum(sal) as sum_sal from EMPt
group by deptno

使用UNPIVOT列转行
create table src_table(
product_Id varchar2(10),
product_color varchar2(10),
porduct_type varchar2(10),
is_intelligent varchar2(10));
prompt Importing table SCOTT.SRC_TABLE...
set feedback off
set define off
insert into SCOTT.SRC_TABLE (PRODUCT_ID,PRODUCT_COLOR, PORDUCT_TYPE, IS_INTELLIGENT)
values ('1111 ', 'red ', 't1 ', '是');
insert into SCOTT.SRC_TABLE (PRODUCT_ID,PRODUCT_COLOR, PORDUCT_TYPE, IS_INTELLIGENT)
values ('1112 ', 'blue ', 't2 ', '否');
insert into SCOTT.SRC_TABLE (PRODUCT_ID,PRODUCT_COLOR, PORDUCT_TYPE, IS_INTELLIGENT)
values ('1113 ', 'green ', 't3 ', '是');
prompt Done.
select * from SCOTT.SRC_TABLE t

SELECT *
FROM src_table UNPIVOT(param_value FOR param_name IN(product_color,PORDUCT_TYPE, is_intelligent));

---GROUPING()函数用法介绍
GROUPING函数可以接受一列,返回0或者1。如果列值为空,那么GROUPING()返回1;如果列值非空,那么返回0。GROUPING只能在使用ROLLUP或CUBE的查询中使用。当需要在返回空值的地方显示某个值时,GROUPING()就非常有用。
1、在ROLLUP中对单列使用GROUPING()
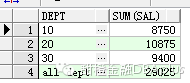
SELECT t.deptno,sum(sal) FROM emp t
group by rollup(t.deptno)

加上GROUPING来看看
SELECT grouping(t.deptno), t.deptno,sum(sal)
FROM emp t
group by rollup(t.deptno)

2、使用CASE转换GROUPING()的返回值
可能你会觉得前面的0和1太枯燥了,代表不了任何意义,说白了就是不够人性化,呵呵。这个时候我们可以使用
SELECT case
when grouping(t.deptno) = 1 then
'all dept'
else
to_char(t.deptno)
end as dept,
sum(sal)
FROM emp t
group by rollup(t.deptno)
2、使用GROUPING SETS子句
使用GROUPING SETS子句可以只返回小计记录。
SELECT t.deptno, t.job, sum(sal)
FROM emp t
group by grouping sets(t.deptno, t.job)
order by t.deptno, t.job

-----MODEL使用
create table tmp_shzg_sales(
YEARS number,MONTHS number,PRODUCT_NAME varchar2(15),SALES number);
prompt Importing tableSCOTT.TMP_SHZG_SALES...
set feedback off
set define off
insert into SCOTT.TMP_SHZG_SALES(YEARS, MONTHS, PRODUCT_ NAME, SALES)
values (2015, 1, 'A', 1000);
insert into SCOTT.TMP_SHZG_SALES(YEARS, MONTHS, PRODUCT_ NAME, SALES)
values (2015, 1, 'B', 1500);
insert into SCOTT.TMP_SHZG_SALES(YEARS, MONTHS, PRODUCT_ NAME, SALES)
values (2015, 2, 'A', 2000);
insert into SCOTT.TMP_SHZG_SALES(YEARS, MONTHS, PRODUCT_ NAME, SALES)
values (2015, 2, 'B', 2500);
insert into SCOTT.TMP_SHZG_SALES(YEARS, MONTHS, PRODUCT_ NAME, SALES)
values (2015, 3, 'A', 1500);
insert into SCOTT.TMP_SHZG_SALES(YEARS, MONTHS, PRODUCT_NA, SALES)
values (2015, 3, 'B', 1700);
prompt Done.
---------------
select * from TMP_SHZG_SALES t orderby years, months, product_name;

--用位置标记和符号标记访问数据单元
select years, months, product_name,sales
from TMP_SHZG_SALES
model
partition by(years)
dimension by(months, product_name)
measures(sales sales)
rules(sales[months=4,product_name='A']=sales[months=3,product_name='A']);

--不用位置标记和符号标记访问
select years,months,product_name,xyzfrom TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales xyz)
rules
(
xyz[4,'A']=xyz[2,'A']
);

总结一:用位置标记的不返回更新后的行,不用位置标记会将更新后的行也一起返回。
--用位置标记和使用returnupdated rows符号访问
select years, months, product_name,xyz
from TMP_SHZG_SALES
model
return updated rows
partition by(years)
dimension by(months, product_name)
measures(sales xyz)
rules(xyz[months=4,product_name='A']=xyz[months=3,product_name='A']);

--不用位置标记和符号标记访问
select years,months,product_name,xyzfrom TMP_SHZG_SALES
model
return updated rows
partition by (years)
dimension by (months,product_name)
measures (sales xyz)
rules
(
xyz[4,'A']=xyz[2,'A']
);

总结:使用return updated rows 以后,只返回有更新的行记录。
--使用ANY和IS ANY
--ANY和位置标记一起使用,IS ANY和符号标记一起使用。
select years,months,product_name,sale from TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales sale)
rules
(
sale[ANY,'A']=100
);

selectyears,months,product_name,sale from TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales sale)
rules
(
sale[months IS ANY,'A']=100
);

--总结:ANY和IS ANY可以简化rules中的规则
--使用currentv()或者CV()函数
selectyears,months,product_name,sale from TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales sale)
rules
(
sale[2,'A']=sale[cv(),'B']
);

selectyears,months,product_name,sale from TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales sale)
rules
(
sale[2,'A']=sale[cv(months)-1,'B']
);

--使用FOR循环
select years,months,product_name,xyzfrom TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales xyz)
rules
(
xyz[for months from 1 to 3 increment1,'A']=xyz[cv(),'B']
);

select years,months,product_name,xyzfrom TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales xyz)
rules
(
xyz[for months in(1,2,3),'A']=xyz[cv(),'B']
);

--使用IS PRESENT
--如果数据单元指定的记录在MODEL子句执行之前就存在,那么IS PRESENT 返回TRUE
select years,months,product_name,xyzfrom TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales xyz)
rules
(
xyz[for months in (1,2,3),'A']=CASEWHEN xyz[cv(),'B']
IS PRESENT THEN xyz[cv(),'B'] ELSE 0END
);

--使用PRESENTV()
--PRESENTV(CELL,EXPR1,EXPR2)如果cell引用的记录存在,则返回EXPR1,否则返回EXPR2;
select years,months,product_name,xyzfrom TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales xyz)
rules
(
xyz[for months in (1,2,3,4),'A']=presentv(xyz[cv(),'B'],xyz[cv(),'B'],0)
);

--使用PRESENTNNV()
--PRESENTNNV(CELL,EXPR1,EXPR2)只有当cell单元引用的记录存在且不为空时才返回EXPR1,否则返回EXPR2;
select years,months,product_name,xyzfrom TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales xyz)
rules
(
xyz[for months in(1,2,3,4),'A']=presentnnv(xyz[cv(),'B'],xyz[cv(),'B'],1)
);

-使用IGNORE NAV和KEEP NAV
IGNORE NAV 的返回值如下:
空值或缺失数字值时返回0;
空值或缺失字符串时返回空字符串;
空值或缺失日期值时返回01-JAN-2000;
其他数据库类型时返回空值;
KEEP NAV 对空值或缺失数字值返回空值,默认条件下是使用KEEP NAV
select years,months,product_name,xyzfrom TMP_SHZG_SALES
model
partition by (years)
dimension by (months,product_name)
measures (sales xyz)
rules
(
xyz[for months in(1,2,3,4),'A']=xyz[cv(),'B']
);

--End--
补充说明:
我是本文的作者,2016年1月26日在翼支付的微信公众号首发,以前公司要求在公众号写文章,但是我看已经被墨天轮网站收录了,我想把该文章转发在我的CSDN上。
原文链接如下:














 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









