







目录
集群
广义的集群
- 只要是多个机器 且构成了分布式系统,均可称为是一个集群
- 主从结构、哨兵模式,也可认为是 广义的集群
狭义的集群
- Redis 提供的集群模式,在集群模式下,主要解决存储空间不足问题,即拓展存储空间
- 虽然哨兵模式提高了系统的可用性,但其本质还是通过 Redis 主从节点来存储数据
- 即通过 主节点/从节点 来存储整个数据的全集
问题:
- 一台机器的内存存储的空间始终是有限的!
解决方案:
- 引入多台机器,每台机器存储一部分数据
实例理解
- 例如有 1TB 的数据需要存储
- 拿两台机器来存,每台机器仅需存 512GB
- 拿四台机器来存,每台机器仅需存 256GB
- 随着机器数目的增加,每台机器所存储的数据量也便跟着减少
- 只要机器的规模足够多,便可以存储任意大小的数据
注意:
- 对于拿四台机器而言,不是说光搞四台机器就够了,而是每台存储数据的机器还需搭配若干个从节点
- 下述文章将介绍三种主流的数据分片算法

哈希求余算法
- 哈希求余算法 借鉴了哈希表的基本思想
基本思路
- 借助 hash 函数,针对要插入的数据的 key 来计算出一个 hash 值
- 再将该 hash 值余上 分片的个数,从而便得到一个下标
- 最终根据该下标来决定该 数据 应存入到哪个分片中
实例理解
- 假设有 四个分片,分别为 0号分片、1号分片、2号分片、3号分片
- 再次假设 hash(key)%N = 1 ,此时这个 key 对应的数据便应存入 1号分片中
- 后续查询 key 时,直接采用同样的算法
- 因为 key 是一样的,hash 函数是一样的,得到的 下标值 就是一样的
注意点一:
- 此处我们是针对要插入数据的 key 来计算 hash 值,而不是 value!
- Redis 本身存储的就是键值对结构的数据
注意点二:
- 关于 hash 函数,我们可以选择使用 MD5
- MD5 本身就是一个计算 hash 的算法
- MD5 可针对一个字符串里面的内容进行一系列的数学变换,最终变换成整数
- MD5 是一个非常广泛使用的 hash 算法
MD5 的特点:
- MD5 算出的结果为定长,即无论输入的原字符串多长,最终算出的结果均为固定长度
- MD5 算出的结果是分散的,即两个原字符串大部分都相同,仅一个小地方不同,算出来的 MD5 值也会差别很大
- MD5 计算结果是不可逆的,即给你原字符串,可以很容易算出 MD5 值,但是给你 MD5 值,很难还原出原始的字符串的(理论上是不可行的)
注意:
- 网上所存在的 MD5 破解,其实就是将一些常见字符串的 MD5 值提前算好,并将其保存下来
- 按照打表的方式,根据 MD5 值映射到 原字符串
- 此时你所提供的 MD5 值能不能查到原字符串,就纯凭运气了
服务器扩容
- 一旦服务器集群需要扩容,此时就需要更高的成本了
实例理解
- 分片主要目的就是为了能提高存储容量
- 分片越多,能存的数据就越多,其成本也越高
- 一般都是先少搞几个分片,比如 3个分片
- 但是随着业务逐步增长,数据变多,此时 3个分片的存储容量便略显不足,需要扩容
- 引入新的分片,此时 hash(key)% N 中的 N 随之改变
- 当 hash 函数和 key 都不变的情况下,仅 N 发生改变,整体的分片结果也会跟着改变!
- 如果发现某个数据在扩容之后,不应该待在当前的分片中了,就需要对其重新进行分配,即搬运数据
- 观察上图,一共 20 个数据,只有 3个数据不需要搬运,搬运了 17 个数据
- 如果是 20亿个数据呢?就有 17亿个数据需要搬运,这就十分麻烦了!
注意:
- 上述方式的扩容,开销极大
- 往往不能直接在生产环境上操作,只能通过 替换的方式来实现扩容
- 即重新搞原来那么多分片,并将原数据都拷贝过来,再引入新机器进行扩容操作,直到扩容完成,最后用新机器代替旧机器
- 这样一来依赖的机器将变得更多,成本也变得更高,操作步骤也更加复杂

一致性哈希算法
- 在上述哈希求余算法中,当前 key 属于哪个分区是交替进行存储的,即不连续
实例理解
- 结合上述的实例
- 102 属于 0 号分区、103 属于 1号分区、104 属于 2号分区、105 属于 0号分区
- 如此交替存储,导致搬运的成本很大
- 在一致性哈希算法的设定下,将交替存储,该进成了连续存储
基本思路
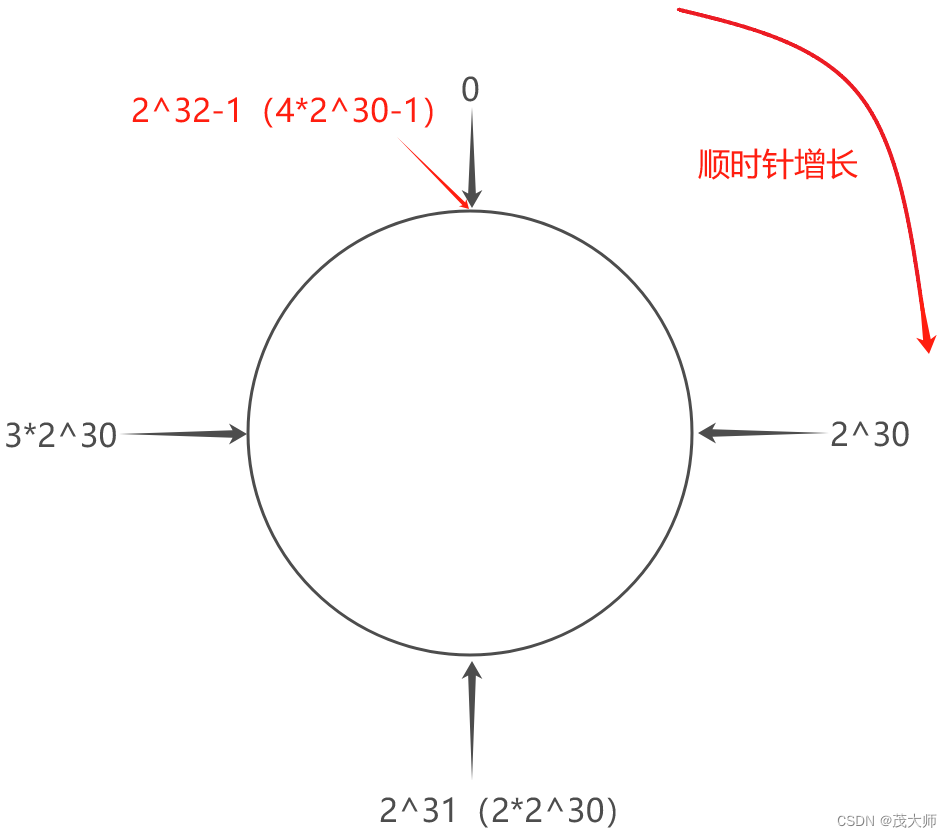
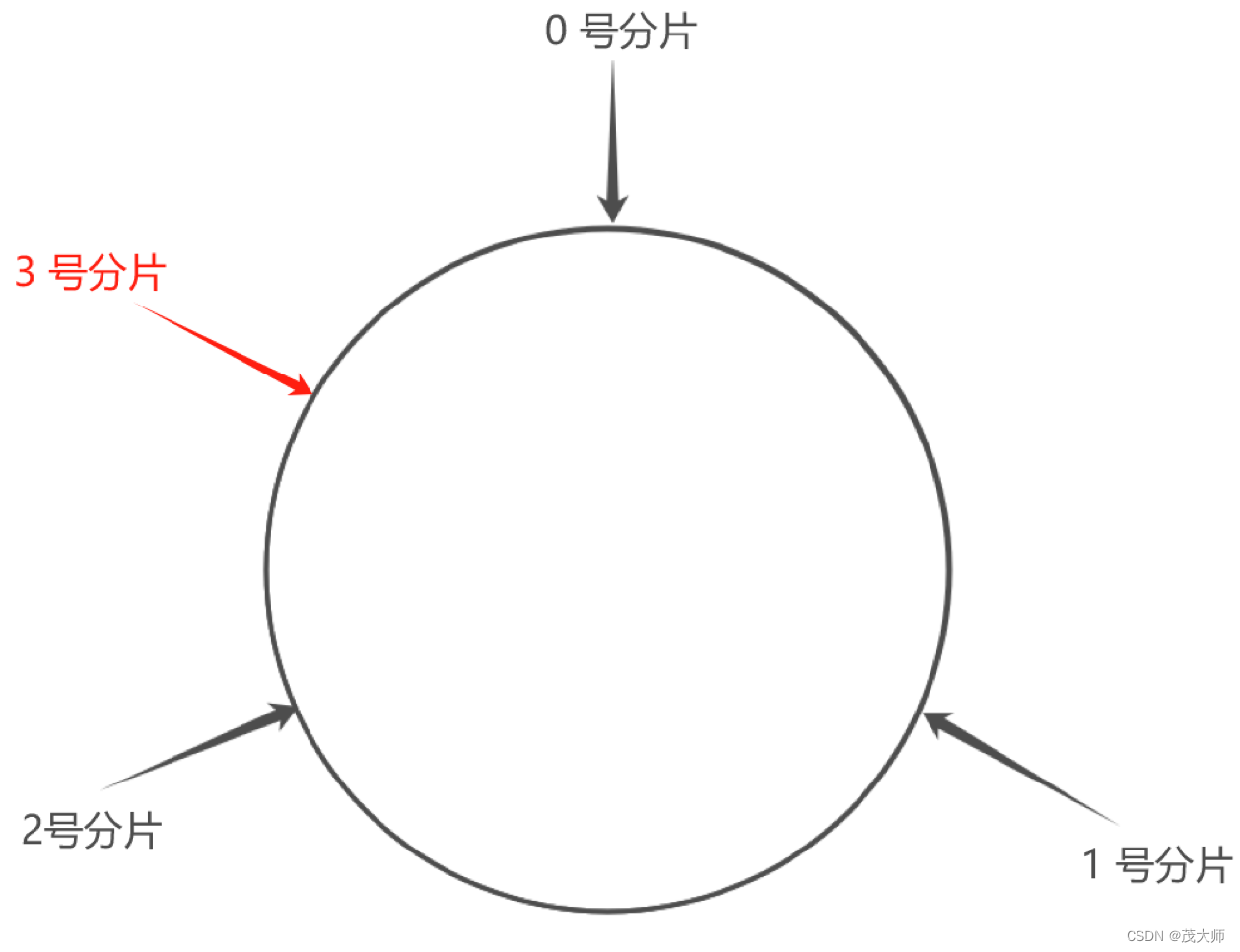
1、将 0~2^32-1 这个数据空间,映射到一个圆环上,数据按照顺时针方向增长
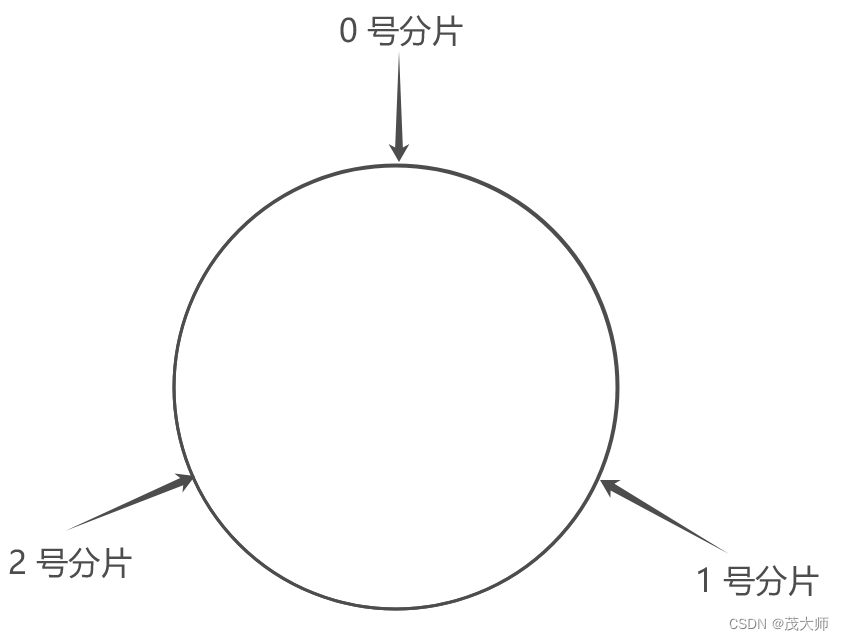
2、假设当前存在三个分片,将分片放到圆环对应位置上
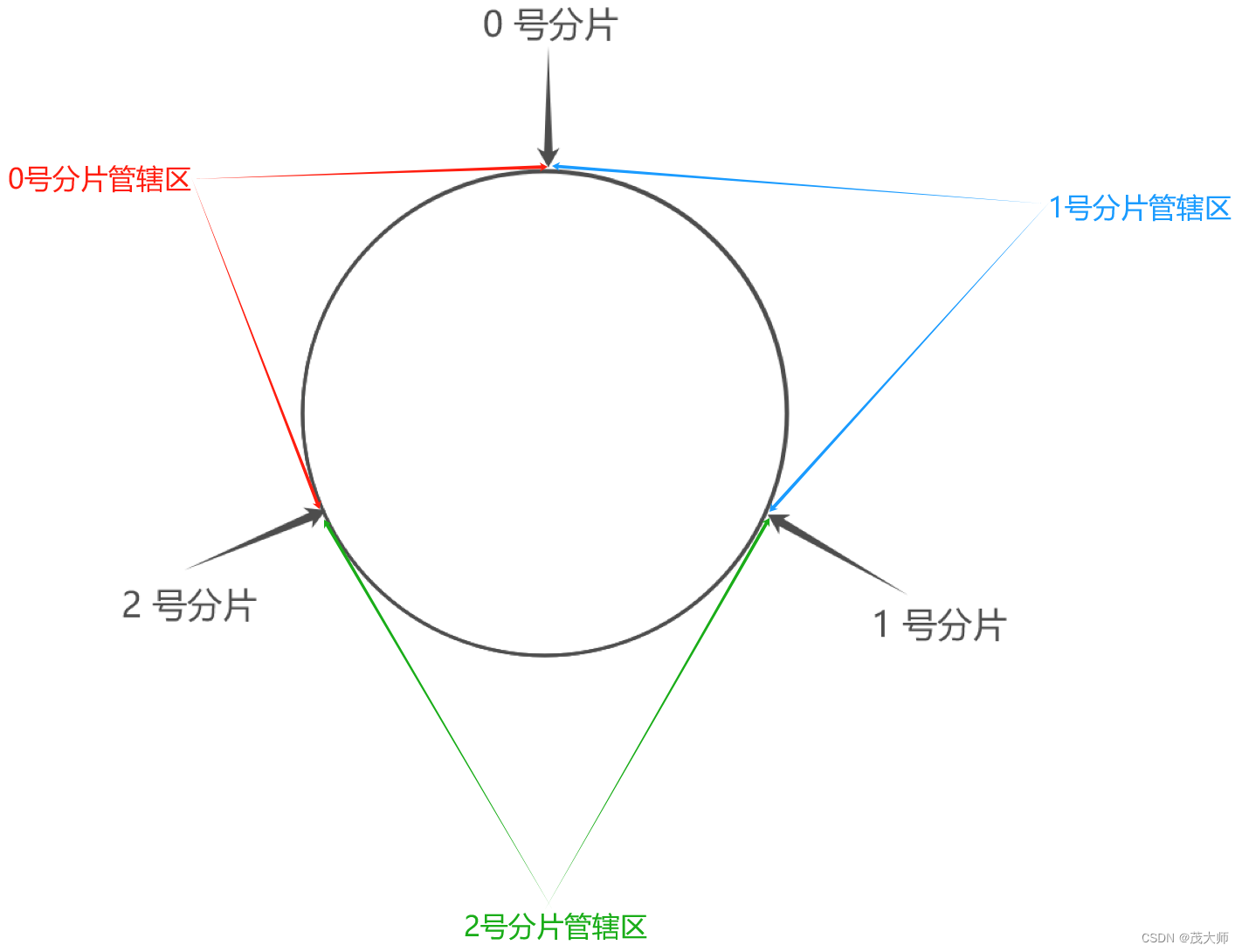
3、假设有一个 key,通过 hash 算法计算出 value 值 ,此时便将该 value 值映射到圆环上,接着顺时针去找,找到第一个分片就是该 key 应存入的分片
4、如需扩容,则原有分片在环上的位置不变,只需在环上新安排一个分片位置即可
- 此时仅需将 0号分片上的数据部分搬运给 3号分片即可,其他分片不动
注意点一:
- 因为 1号分片 和 2号分片 均不变
- 虽然该搬运方式的成本也是有的,但是还是比刚才哈希求余的方式低了不少
注意点二:
- 虽然搬运的成本低了,但是这几个分片的数据量,可能会因此不均匀,即数据倾斜
问题:
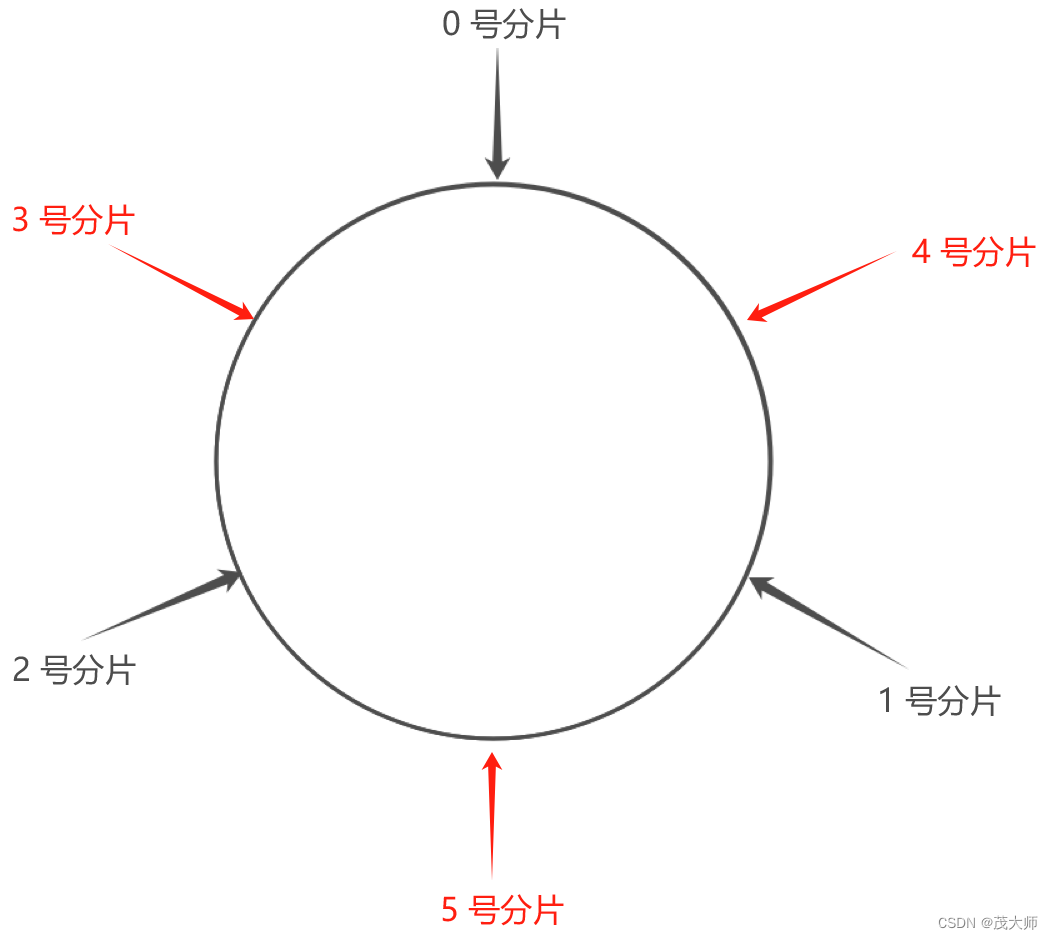
- 如果扩容时,搞多个分片呢?
- 如上图所示,这样不就可以避免数据倾斜问题吗?
回答:
- 这确实是个好的思路
- 且总的搬运数据量仍比哈希求余的方式更少
- 但最大的问题是 领导会给你批这么多机器吗? 该方式的成本还是比较高的!
哈希槽分区算法
- Redis 真正采用的分区算法
- 这种算法的本质就是将 一致性哈希 和 哈希求余 这两种方式给结合了起来
公式:
- hash_slot = crc16(key) % 16384
- hash_slot:表示哈希槽,有了哈希槽便可进一步将这些哈希槽分配到不同的分片上
- crc16:一种计算 hash 值的算法
- 16384:至于此处为啥取 16384 的余数,后文有详细说明
实例理解
- 假设当前有 3个分片,以下是哈希槽一种可能的分配方式
- 0 号分片:[0, 5461],共 5462 个槽位
- 1 号分片:[5462, 10923],共 5642 个槽位
- 2 号分片:[10924, 16383],共 5460 个槽位
注意点一:
- 虽然哈希槽不是严格意义上的均分,但是这三个分片上的数据也算是比较均匀的了
注意点二:
- 此处实例只是一种可能的分配方式
- 实际上 分片是非常灵活的
- 每个分片持有的槽位号,可以是连续的,也可以是不连续的
注意点三:
- 每个分片均会使用 位图 这样的数据结构 表示自己当前有多少槽位号
- 16384 个 bit 位,用每一位 0/1 来区分当前 自己这个分片 是否持有该槽位号
简单理解
服务器扩容
- 当需要进行扩容时,比如新增一个 3号分片,此时便可以针对原有槽位进行重新分配
- 可以将之前每个分片所持有的槽位,各拿出一点给新分片
- 0 号分片: [0, 4095], 共 4096 个槽位
- 1 号分片: [5462, 9557], 共 4096 个槽位
- 2 号分片: [10924, 15019], 共 4096 个槽位
- 3 号分片: [4096, 5461] + [9558, 10923] + [15020, 16383], 共 4096 个槽位
注意点一:
- 针对新增的 3号分片,其槽位号不一定非得是连续的区间
注意点二:
- 在 Reids 中,当前某个分片包含哪些槽位都是可以手动配置的
问题一:
- Redis 集群是最多有 16384 个分片吗?
回答:
- 此时每个分片上就只有一个槽位
- key 是先要映射到槽位,再映射到分片的
- 如果每个分片包含的槽位比较多,且槽位个数相当,就可认为各分片包含 key 数量相当
- 如果每个分片包含的槽位比较少,这时槽位个数就不一定能直观的反应到 key 的数目
- 因为有的槽位可能是有多个 key,有的槽位可能没有 key
- 此时便难以保证数据在各个分片上的均衡性
注意:
- Reids 的作者建议集群分片不应该超过 1000 !
具体理解:
- 如果真分成了 1.6w 个分片,那么整个数据服务器的集群规模就太可怕了
- 由万台主机构成的集群,整个集群的可用性是非常堪忧的!
- 因为机器越多,出故障的概率就越高!
问题二:
- 为什么是 16384 个槽位?
回答:
- 首先,节点之间通过心跳包进行通信,心跳包便包含了该节点持有那些槽位
- 表示 16384 个 槽位,需要的位图大小为 2KB
- 如果给定的 槽位数 更多了,如 65536 个,此时便需要消耗更多的空间,即需要的位图大小为 8KB
- 虽然这对于内存来说不算什么,但是在频繁的网络心跳包中,还是一个不小的开销
- 另一方面,16384 个槽位也基本够用了,且占用的网络带宽也不是很大
注意:
- 网络带宽相较于内存来说更稀有、更贵重

















 2065
2065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











