




豆瓣地址 :豆瓣电影 Top 250 (douban.com)
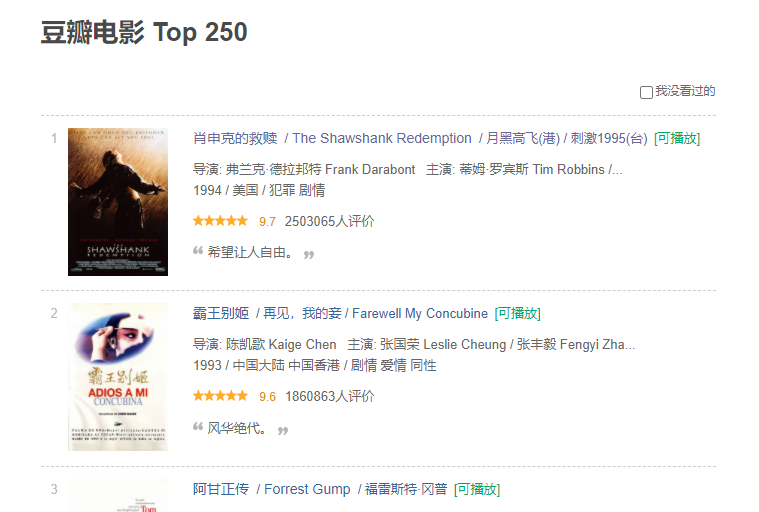
豆瓣界面
1.先分析每一页的url地址

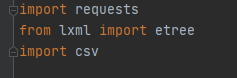
.2.导入要用的模块
3.开始撸代码
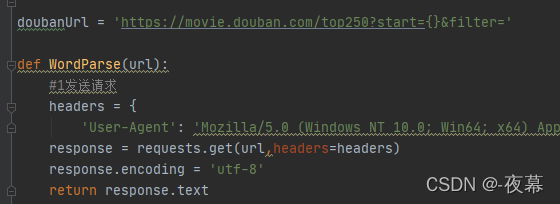
(1)doubanUrl :因为我们要进行多页爬取,先在定义的函数WordParse传入一个url
(2)解析数据
豆瓣界面
1.先分析每一页的url地址
.2.导入要用的模块
3.开始撸代码
(1)doubanUrl :因为我们要进行多页爬取,先在定义的函数WordParse传入一个url
(2)解析数据
 1万+
8334
1万+
8334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


























