






第一章 项目介绍
本项目是一个基于Spark技术的地产数据资产分析系统,针对房地产销售库存、楼盘施工及房源热度等方面进行深入分析。通过Spark处理房地产数据集,并利用其ML算法库中的LinearRegressionModel预测房源的粘度。系统整合了数据存储、大数据分析、Web后端及可视化前端,为用户提供直观的数据展示和决策支持。项目运行便捷,数据文件与SQL文件完备,确保系统的稳定性和易用性。
!!!海量数据集 !!!
!!!有部署文档和视频!!!
!!!有论文参考!!!
!!!可以用作技能提升,毕设,课设等参考学习 !!!
第二章 所用技术
java+hadoop+spark+idea +springnboot+mysql+js+css+html+echarts等2.1 Java
作为后端主要开发语言,Java以其跨平台性、面向对象和丰富的类库支持,为系统提供稳定可靠的基础。
应用于后端服务逻辑的实现,包括数据访问、业务处理、API接口等。
2.2 Hadoop
Hadoop是一个分布式系统基础架构,主要用于存储和分析海量数据。
在本系统中,Hadoop负责存储地产相关的数据,并提供高效的数据存储和读取服务。
利用HDFS(Hadoop Distributed FileSystem)进行数据存储,MapReduce进行批量数据处理。
2.3 Spark
Spark是一个基于内存的分布式计算框架,相比Hadoop的MapReduce,Spark提供了更快的计算速度和更丰富的计算模型。
在本系统中,Spark将用于对存储在Hadoop中的地产数据进行深度分析和挖掘。
利用Spark SQL进行交互式查询,Spark MLlib进行机器学习,Spark Streaming进行实时数据流处理等。
2.4 Spring Boot
Spring Boot是一个基于Spring的框架,旨在简化新Spring应用的初始搭建和开发过程。
在本系统中,Spring Boot用于快速搭建后端微服务,包括API接口服务、数据处理服务等。
利用Spring Boot的自动配置、简化开发、独立运行等特性,提高开发效率。
2.5 MySQL
MySQL是一个流行的关系型数据库管理系统,用于存储和分析数据。
在本系统中,MySQL将用于存储数据分析的结果,方便前端展示和后续的数据挖掘。
2.6 JavaScript、CSS、HTML、ECharts
这些技术用于前端页面的开发和数据可视化。
JavaScript负责前端页面的交互逻辑和数据处理。
CSS用于控制页面的样式和布局。
HTML构建页面的基本结构。
ECharts是一个使用JavaScript实现的开源可视化库,用于生成各种图表,如折线图、柱状图、饼图等,帮助用户更直观地理解数据。
第三章 项目效果图
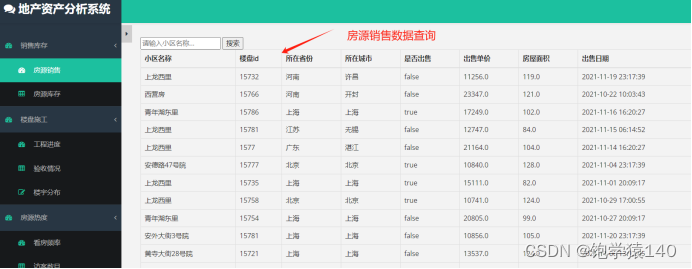
3.1 图1 房源销售数据查询
房源销售相关的数据管理,其中包含如下字段
小区名称,楼盘id,所在省份,所在城市,是否出售,出售单价,房屋面积,出售日期
可以根据小区名称进行搜索。
3.2 图2 房源库存数据查询
房源存储数据管理,其中包含对小区名称,楼盘id,所在省份,所在城市,以及库存数量和户型,并且可以根据条件进行查询和帅选。

3.3 图3 工程进度分析效果图
利用大数据SparkSql技术,针对不同的楼盘进行工程进度的分析,便于更好的把控进度数据源整合:首先,我们需要收集并整合来自不同楼盘的工程进度数据。这些数据可能包括每个楼盘的开工日期、各个阶段的完成日期、关键节点的里程碑信息、投入的资源(如人力、材料、机械等)等。这些数据可能分散在多个系统或数据库中,通过ETL(Extract, Transform, Load)过程,我们可以将这些数据整合到大数据平台中。
Spark SQL分析:使用Spark SQL,我们可以对整合后的数据进行复杂的查询和分析。例如,我们可以计算每个楼盘的当前进度百分比、各阶段的平均完成时间、资源投入的效率等。此外,我们还可以利用Spark SQL的窗口函数、聚合函数等高级特性,进行更深入的分析。
可视化展示:为了更直观地展示分析结果,我们可以使用柱状图等可视化工具。柱状图可以清晰地展示不同楼盘在相同时间点的进度对比,或者同一楼盘在不同时间点的进度变化。通过可视化工具,我们可以快速发现进度异常或问题,并及时采取相应的措施。

3.4 图4 楼宇区域分析结果图
利用大数据技术,我们可以对楼宇数据进行深度分析,通过聚合算法按地区省份进行数据整合。随后,利用可视化技术将这些数据以地图的形式展现,直观地呈现各省份楼宇的分布、数量或相关指标,为决策提供有力支持。

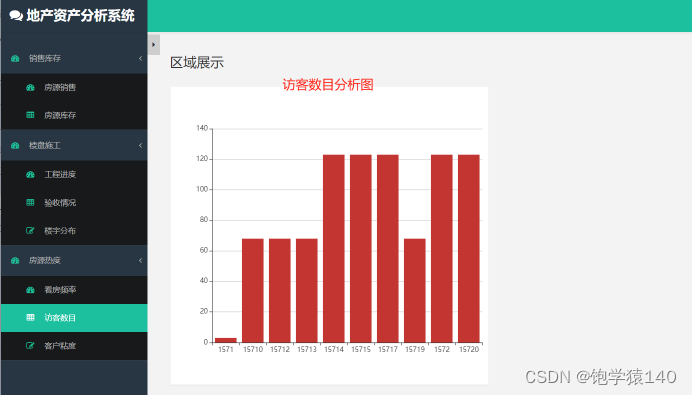
3.5 图5 访客数目分析图
利用大数据技术Spark,我们可以对海量的楼宇数据进行高效的访客数目分析计算。Spark的分布式计算能力使我们能够迅速处理庞大的数据集,并提取出关于访客数量的关键信息。通过聚合和统计各个楼宇的访客数据,我们能够清晰地发现不同楼宇之间的热度差异。最终,我们利用数据可视化技术,将这些分析结果以柱状图的形式展示出来,其中X轴代表各个楼盘的编号,Y轴表示对应的访客数量。这样的展示方式使得数据更加直观易懂,有助于决策者快速把握楼宇的热度情况,从而做出更加明智的决策。
3.6 图6 客户粘度预测
在楼盘的客户粘度预测项目中,我们首先利用已有的样本数据,通过Spark的MLlib算法库中的线性回归模型进行训练。MLlib提供了丰富的机器学习算法,其中线性回归是一种用于预测数值型目标变量的强大工具。我们利用该算法对影响客户粘度的因素进行建模,并训练出预测模型。随后,我们将训练好的模型应用于新的数据,进行客户粘度的预测,并将预测结果存储到数据库中。最后,为了方便查看和分析,我们将预测结果以表格的形式进行展示,从而直观地了解各个楼盘的客户粘度情况。

第四章 相关资料
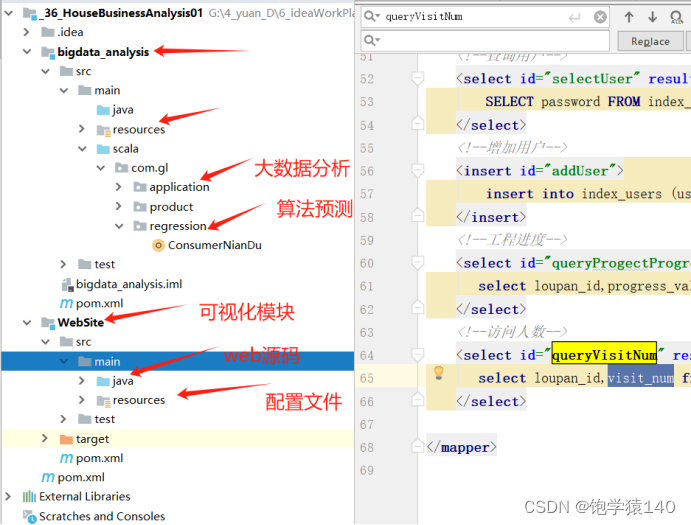
4.1 项目源码结构图
本项目融合了大数据处理与Web可视化技术,通过Scala编写的Spark程序,运用其强大的数据处理能力,对楼盘施工进度,访客数据,区域特点以及客户粘度等指标进行深度分析和算法挖掘。后端服务基于Spring Boot和MyBatis框架,确保系统的高效性和稳定性。前端则采用ECharts和HTML技术,将分析结果以直观、易懂的柱状图等可视化形式展示给用户。整个项目代码结构清晰,逻辑严密,易于上手和维护,为楼盘客户洞察预测提供了强有力的技术支持。
4.2 资料目录图
这份资料集合异常丰富,不仅涵盖了详尽的文档资料用于理解和参考,还包括了项目实现的关键代码,可直接部署或修改的数据库文件,以及处理和分析所需的海量数据集。此外,精美的效果图直观地展示了项目成果,而运行演示视频则动态地呈现了项目的操作流程和效果,为理解和应用提供了全方位的帮助。

4.3 技术支持
若需获取资料、源码、数据或定制开发支持,请随时与我们联系。
















 948
948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









