







维护一个集合,支持如下几种操作:
I x,插入一个数 x;Q x,询问数 x 是否在集合中出现过;
现在要进行 N 次操作,对于每个询问操作输出对应的结果。
输入格式
第一行包含整数 N,表示操作数量。
接下来 N 行,每行包含一个操作指令,操作指令为 I x,Q x 中的一种。
输出格式
对于每个询问指令 Q x,输出一个询问结果,如果 x 在集合中出现过,则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1≤N≤105
−109≤x≤109
输入样例:
5
I 1
I 2
I 3
Q 2
Q 5
输出样例:
Yes
No
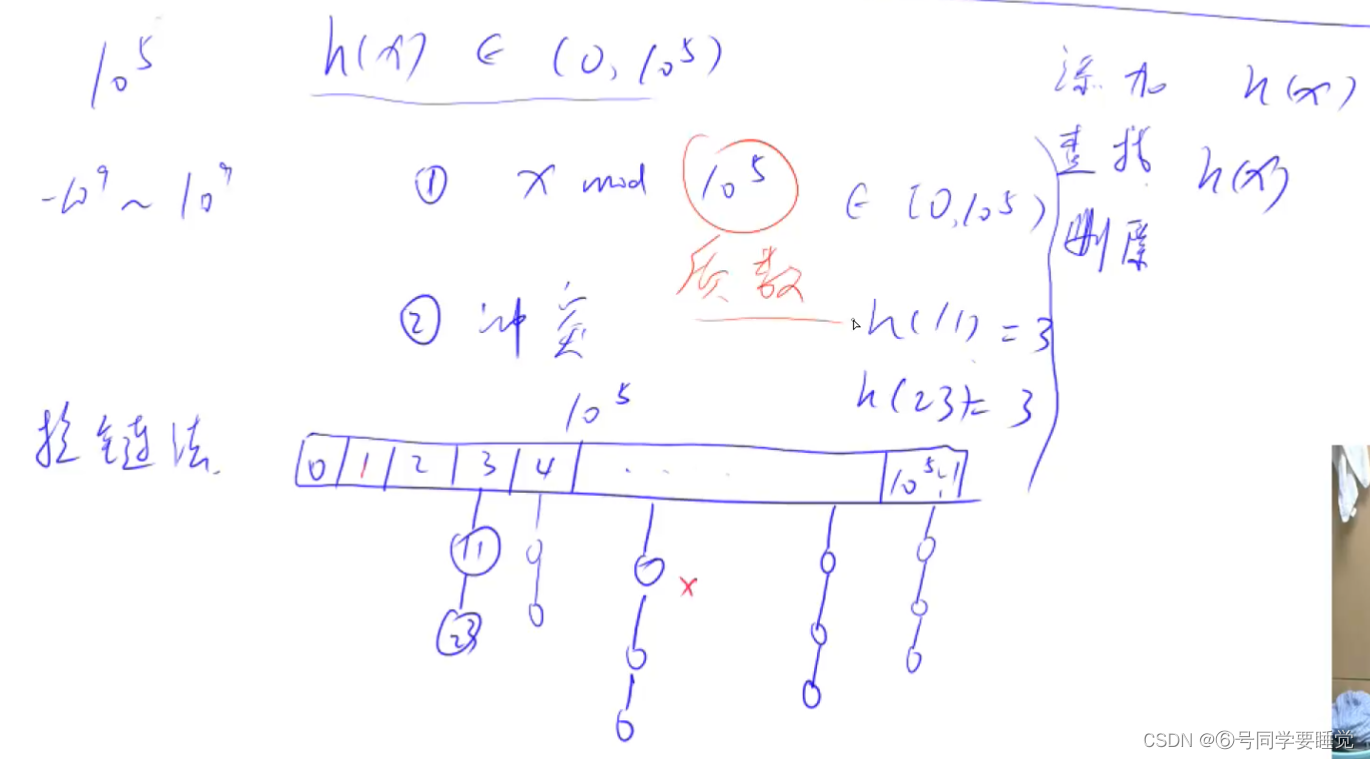
拉链法
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5 + 3;
int ne[N], e[N], h[N];
int n, idx;
void insert(int x){
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx ++ ;
}
bool find(int x){
int k = (x % N + N) % N;
for(int i = h[k]; i != -1; i = ne[i]){
if(e[i] == x)
return true;
}
return false;
}
int main(){
cin >> n;
memset(h, -1, sizeof h);
while(n -- ){
string op;
int x;
cin >> op >> x;
if(op == "I"){
insert(x);
}
else{
if(find(x))
puts("Yes");
else
puts("No");
}
}
return 0;
}
开放寻址法

原文链接:https://www.acwing.com/solution/content/33699/
思路
开放寻址法采用hash函数找到在hash数组中对应的位置,如果该位置上有值,并且这个值不是寻址的值,则出现冲突碰撞,需要解决冲突方案,该算法采用简单的向右继续寻址来解决问题。由于思想简单,将不深入探讨,在次,我们探讨一下文中常常让人摸不着头脑的参数
让人费解的参数
1. const int N = 200003;
1.1开放寻址操作过程中会出现冲突的情况,一般会开成两倍的空间,减少数据的冲突1.2如果使用%来计算索引, 把哈希表的长度设计为素数(质数)可以大大减小哈希冲突
比如
10%8 = 2 10%7 = 3
20%8 = 4 20%7 = 6
30%8 = 6 30%7 = 2
40%8 = 0 40%7 = 5
50%8 = 2 50%7 = 1
60%8 = 4 60%7 = 4
70%8 = 6 70%7 = 0这就是为什么要找第一个比空间大的质数
2.const int null = 0x3f3f3f3f 和 memset(h, 0x3f, sizeof h)之间的关系;首先,必须要清楚memset函数到底是如何工作的
先考虑一个问题,为什么memset初始化比循环更快?
答案:memset更快,为什么?因为memset是直接对内存进行操作。memset是按字节(byte)进行复制的void * memset(void *_Dst,int _Val,size_t _Size);
这是memset的函数声明
第一个参数为一个指针,即要进行初始化的首地址
第二个参数是初始化值,注意,并不是直接把这个值赋给一个数组单元(对int来说不是这样)
第三个参数是要初始化首地址后多少个字节
看到第二个参数和第三个参数,是不是又感觉了
h是int类型,其为个字节, 第二个参数0x3f八位为一个字节,所以0x3f * 4(从高到低复制4份) = 0x3f3f3f3f这也说明了为什么在memset中不设置除了-1, 0以外常见的值
比如1, 字节表示为00000001,memset(h, 1, 4)则表示为0x01010101
3. 为什么要取0x3f3f3f,为什么不直接定义无穷大INF = 0x7fffffff,即32个1来初始化呢?3.1 首先,0x3f3f3f的体验感很好,0x3f3f3f3f的十进制是1061109567,也就是10^9级别的
(和0x7fffffff一个数量级),而一般场合下的数据都是小于10^9的,所以它可以作为无穷大
使用而不致出现数据大于无穷大的情形。
比如0x3f3f3f3f+0x3f3f3f3f=2122219134,这非常大但却没有超过32-bit,int的表示范围,
所以0x3f3f3f3f还满足了我们“无穷大加无穷大还是无穷大”的需求。
但是INF不同,一旦加上某个值,很容易上溢,数值有可能转成负数,有兴趣的小伙伴可以去试一试。3.2 0x3f3f3f3f还能给我们带来一个意想不到的额外好处:如果我们想要将某个数组清零,
我们通常会使用memset(a,0,sizeof(a))这样的代码来实现(方便而高效),但是当我们想
将某个数组全部赋值为无穷大时(例如解决图论问题时邻接矩阵的初始化),就不能使用
memset函数而得自己写循环了(写这些不重要的代码真的很痛苦),我们知道这是因为memset
是按字节操作的,它能够对数组清零是因为0的每个字节都是0,
现在如果我们将无穷大设为0x3f3f3f3f,那么奇迹就发生了,0x3f3f3f3f的每个字节都是0x3f!所以
要把一段内存全部置为无穷大,我们只需要memset(a,0x3f,sizeof(a))。
#include<bits/stdc++.h>
using namespace std;
const int N = 2e5 + 3;
const int null = 0x3f3f3f3f;
int n;
int h[N];
int find(int x){
int k = (x % N + N) % N;
while(h[k] != null && h[k] != x){
k ++ ;
}
if(k == N){
k = 0;
}
return k;
}
int main(){
cin >> n;
memset(h, 0x3f, sizeof h);
while(n -- ){
string op;
int x;
cin >> op >> x;
if(op == "I"){
h[find(x)] = x;
}
else{
if(h[find(x)] == null)
puts("No");
else
puts("Yes");
}
}
return 0;
}题解里看到别的解题方法,贴一下orz
原文链接:https://www.acwing.com/solution/content/8546/















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









