







单列集合的基本概念
文章目录
一、集合的引入
Java是一种面向对象语言,如果我们要针对多个对象进行操作,就必须对多个对象进行存储。而数组长度固定,不能满足变化的要求。所以,java提供了集合。
二、集合的作用
集合是用来存放对象的容器,它可以存储任意数据类型的对象。
而且长度可变。在程序中可能无法预先知道有多少个对象,如果用数组来装对象,那么长度不好定义,而集合正解决了这样的问题。
集合提供了许多的方法为使我们更方便地对数据进行操作。
集合的体系
集合分为单列集合(Collection)与双列集合(Map)。
单列集合每个元素只包含一个值,
双列集合包含两个值(键值对)
集合结构图
单列集合
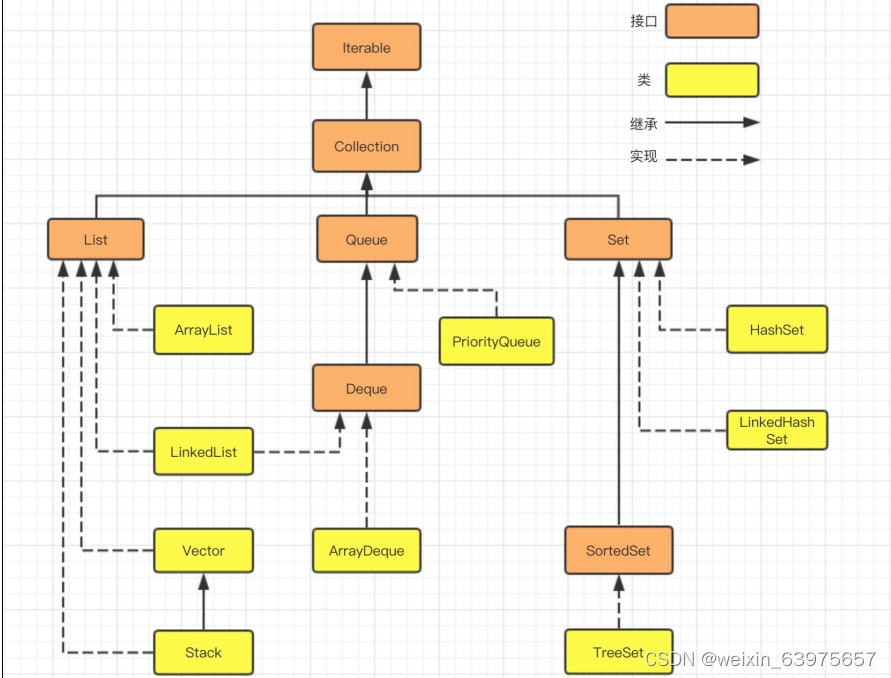
Collection的常用接口有List和Set
List集合存储的特点:一个有序的容器,元素可以重复,可以存入多个null值,每个元素都有索引。常用实现类有ArrayList 、LinkedList。
关于ArrayList
简介:ArrayList是一个动态数组结构,支持随机存取,尾部插入删除方便,内部插入删除效率低,因为要移动数组元素;
扩容机制:
默认情况下,第一次创建该对象时的初始容量为0,调用之后第一次扩容为10,如需扩容,以后每一次扩容后的容量都是前一次的1.5倍。1.5倍的实现是通过位运算的右移一位实现的。
扩容机制详细见这篇文章http://t.csdnimg.cn/ZhJRC
线程安全问题:
ArrayList的线程是不安全的,可以通过以下方式保证ArrayList的线程安全:
方法一:使用 Collections.synchronizedList() 方法:Java 提供了 Collections 类中的 synchronizedList() 方法,可以将一个普通的 ArrayList 转换成线程安全的 List。
方法二、使用 java.util.concurrent.CopyOnWriteArrayList 类: CopyOnWriteArrayList 是 Java 并发包(java.util.concurrent)中提供的一个线程安全的列表实现。它在读取操作上没有锁,并且支持在迭代期间进行修改操作,而不会抛出 ConcurrentModificationException 异常。
方法三、写一个myArrayList继承自Arraylist,然后重写或按需求编写自己的方法,这些方法要写成synchronized,在这些synchronized的方法中调用ArrayList的方法。
方法四、使用显式的锁:可以使用 java.util.concurrent.locks 包中提供的显式锁(如 ReentrantLock)来手动实现对 ArrayList 的同步。这需要在访问 ArrayList 的地方显式地获取和释放锁,从而确保在同一时刻只有一个线程可以访问 ArrayList。
关于LinkedLIst
简介:LinkedList是一个双向链表结构,在任意位置插入删除都很方便,不支持随机取值,每次都只能从一端开始遍历,直到找到查询的对象,然后返回;不过,它不像 ArrayList 那 样需要进行内存拷贝,因此相对来说效率较高,但是因为存在额外的前驱和后继节点指针,因此占 用的内存比 ArrayList 多一些。
ArrayList和LinkedList的区别:
①ArrayList的底层是动态数组的结构,LinkedList是链表的结构
②ArrayList随机访问的效率高,因为它是基于索引的数据结构,可以直接映射到,但它插入删除效率低,LinkedList则相反它随机访问的效率低,插入删除的效率高
③ArrayList的开销比LinkedList的开销小,因为LinkedList的节点除了存储数据之外还需要存储引用
Set集合存储的特点:不允许元素重复,不会记录元素添加的先后顺序,set的常用实现类有:Hashset、LinkedHashSet、TreeSet
关于HashSet类
简介:
-
HashSet实现了Set接口
-
HashSet底层实质上是HashMap,底层是哈希表的数据结构
-
可以存放null值,但是只能有一个null
-
HashSet不保证元素是有序的,取决于hash后,再确定索引的结果,即不保证存放元素的顺序和取出顺序一致
-
不能有重复元素/对象
HashSet去重原理
通过将集合中的元素作为HashMap的key,来判断集合汇总是否存在相同的元素,当集合中存在多个元素时,会调用hashCode()方法来计算每个元素的hash值;
如果不相等,则不重复,如果相等,则调用equals方法比对key是够相等,不相等则不重复;
如果hash和key都相等,则重复了,新值会覆盖旧值。
关于TreeSet
简介:
TreeSet集合底层实际上是一个TreeMap,而TreeMap集合底层是一个二叉树 。元素不可重复 ,且它可以自动按照元素的大小进行排序。
对自定义类型排序:
虽然TreeSet是可以排序的,但它对自定义类型是不能自动排序的。要想实现自定义类型的排序有以下两种方法:
①实现Comparable接口:
自定义类需要实现Comparable接口并且重写compareTo方法
compareTo方法通过this(调用者)和传入的参数进行合理的逻辑判断
②实现java.util.Comparator接口
自定义比较类实现java.util.Comparator接口
重写该接口里的compare方法逻辑
然后在实例化treeSet对象时,添加匿名自定义比较对象(里面含有排序规则)
使用迭代器进行遍历取出并打印值即可
Comparable和Comparator接口的区别
Java提供了只包含一个compareTo()方法的Comparable接口。这个方法可以给两个对象排序。具体来说,它返回负数,0,正数来表明输入对象小于,等于,大于已经存在的对象。
Java提供了包含compare()和equals()两个方法的Comparator接口。compare()方法用来给两个输入参数排序,返回负数,0,正数表明第一个参数是小于,等于,大于第二个参数。equals()方法需要一个对象作为参数,它用来决定输入参数是否和comparator相等。只有当输入参数也是一个comparator并且输入参数和当前comparator的排序结果是相同的时候,这个方法才返回true。
TreeSet和HashSet的区别
总结
本文仅仅简单介绍了单列集合的结构以及常用实现类















 1974
1974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









