






该项目是根据员工的坐标x,y以及员工过去的签到位置来预测下一次签到位置
1. 准备数据库.
 https://www.kaggle.com/navoshta/grid-knn/data
https://www.kaggle.com/navoshta/grid-knn/data一共有三个数据集,样本包sample,训练集train以及测试集test,将其保存到目录下
2.加载数据以及处理数据
由于k-近邻算法处理大型数据库较为困难,便使用抽样来进行训练,利用pandas.read_csv来读取存放在根目录的train.csv,并利用DataFrame.query()API来进行抽样,查看其属性

row_id指员工的id,x和y来代表坐标,time代表当前时间,place_id代表员工签到地址编号
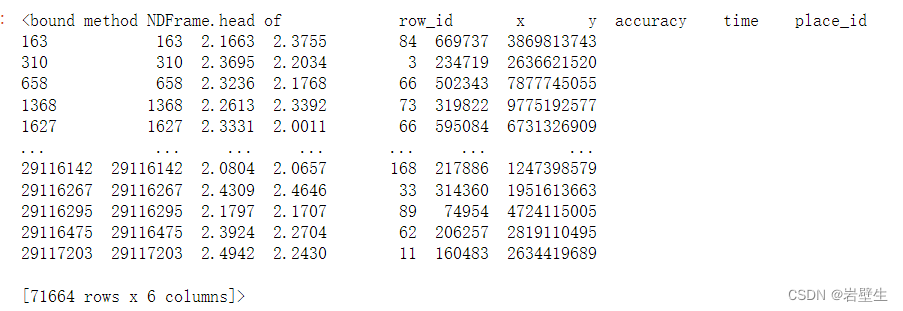
然而时间采用了时间戳进行计时,便于统计,需要将其进行转化
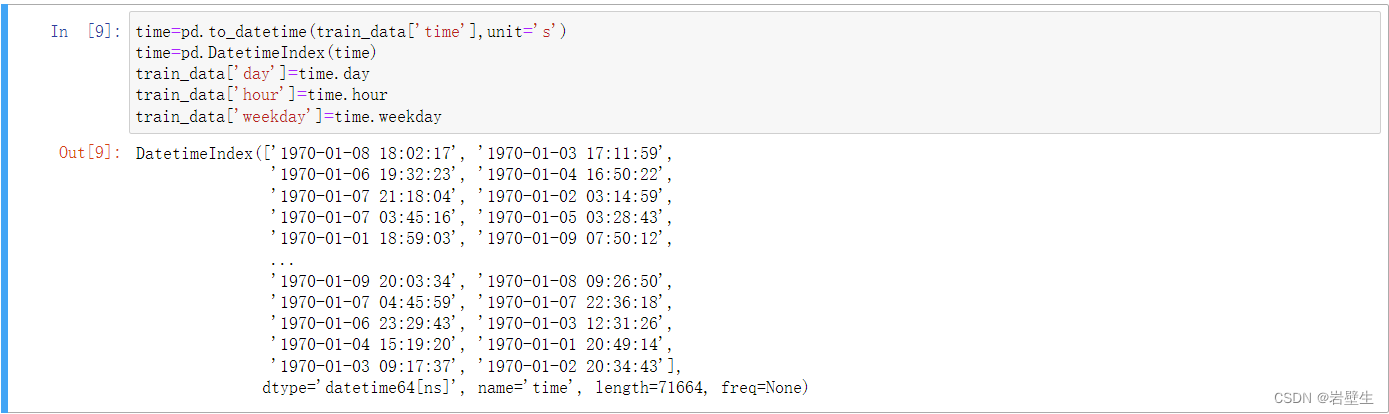 利用pandas.to_datatime的api,将时间戳转换为常规时间,并用pandas.DatetimeIndex来将其转化为dataframe形式,并将time['day'],time['hour'],time['weekday']加入到原数据中,便多出了三列常规时间的数据
利用pandas.to_datatime的api,将时间戳转换为常规时间,并用pandas.DatetimeIndex来将其转化为dataframe形式,并将time['day'],time['hour'],time['weekday']加入到原数据中,便多出了三列常规时间的数据
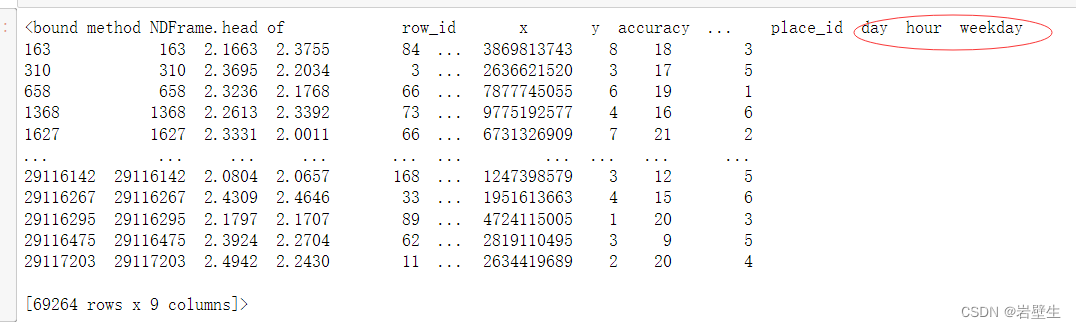
然而,有的地方只被签到了一次,由此进行训练时便会产生误差,为了尽可能的减小误差,我们需要删除掉签到次数过少的噪声点(以3为例)
我们使用pandas内置的分类聚合函数pandas.groupby来对地区进行分组并统计每个地区被签到次数之和来聚合
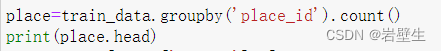

接着利用条件筛选,place['row_id'>3],大于3的将被置为True,否则被置为False,再将其重新赋给place,然后查看train_data里的'place_id'是否在里面出现,出现的保留,否则剔除
![]()
3. 将数据分为训练集和测试集
首先将目标列以及条件列列出
x=train_data[['x','y','accuracy','day','hour','weekday']]
y=train_data[['place_id']]
再使用深度学习库sklearn的内置函数train_test_split将train_data以8:2的比例切分成训练集和测试集
![]()
4. 将对数据做正规化处理
为了数据便于计算以及减少噪声点的影响,进行深度学习时通常对数据进行归一化或正规化处理,利用sklearn里的StandardScaler函数,其默认将数据转化为均值为0,方差为1的数据。

5 . 对数据进行训练
网格搜索功能:提供多个超参数,进行多次计算来选取损失最小的超参数
k-近邻算法:计算样本在样本空间中与其最近样本的欧氏距离,确定其目标值,需要传入n_neighbors参数来确定受几个邻居影响,若取较大,便失去了模型的意义,取值较小便极易受噪声点影响,且处理大数据时通常较慢。
sklearn里有内置的k-近邻算法库,需上传的参数为n_neighbors,首先创建estimator评估器,接下来将要进行网格搜索以字典形式创建,最后对训练集进行拟合。

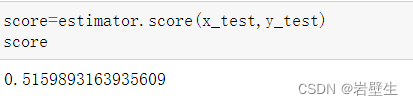
最后进行测试,查看得分56分。















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









