






MySQL百万级数据排序分页查询
1. 需求
按照成绩降序排序,查询字段学号(id),姓名(name),分数(score),带排序的分页查询
数据大小:五百万条
2. 初始状态
浅分页:
# 浅分页
EXPLAIN
SELECT id, name, score from student order by score desc limit 5, 20;
执行效率:执行的为一个全表扫描,并且会额外执行Using filesort
Using filesort表示在索引之外,需要额外进行外部的排序动作。导致该问题的原因一般和order by有者直接关系,一般可以通过合适的索引来减少或者避免。

执行时间:1.394s

深分页:
# 深分页
EXPLAIN
SELECT id, name, score from student order by score desc limit 4500000, 20;
执行效率:和浅分页一样

执行时间:6.071s

结论: 无论深分页还是浅分页,执行时间都是非常长的,并且深分页比浅分页的时间还要更长,因为浅分页的偏移量比较小,而深分页大,所以深分页的扫描行数要比浅分页多,所以时间更长
3. 优化查询1
为order by的排序字段添加索引
# 为order by的排序字段添加索引
ALTER TABLE student ADD INDEX idx_score (score);
浅分页:
# 浅分页
EXPLAIN
SELECT id, name, score from student order by score desc limit 5, 20;
执行效率:直接使用索引,额外执行Backward index scan
Backward index scan 是 MySQL8针对上面场景的一个专用优化项,它可以从索引的后面往前面读,性能上比加索引提示要好的多。在 MySQL 中我们创建的索引,默认索引的叶子节点是从小到大排序的,而此时我们查询排序时,是从大到小,所以,在扫描时,就是反向扫描,就会出现 Backward index scan 。

执行时间:0.032s,加快的查询时间

深分页:
-
执行默认方式
执行效率:走的还是一个全表扫描

执行时间:5.962s,和不使用索引差别不大

-
让深分页强制走索引:FORCE INDEX (idx_score)
EXPLAIN
SELECT id, name, score from student FORCE INDEX (idx_score) order by score desc limit 4500000, 20;
执行效率:和浅分页相同

执行时间:82.011s,查询时间大大增加
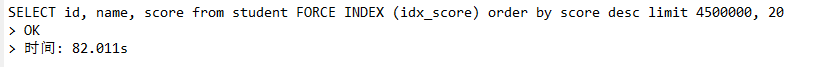
结论:
- 优点:浅分页查询速度得到很好的提升
- 缺点:深分页查询速度没有明显变化,如果走强制索引,查询时间还会大大增加
分析: 在使用索引后,索引需要做一个回表操作,这个需要时间,而排序也需要时间,在执行深分页的时候,偏移量大,造成回表成本增大,所以这时候mysql会帮我们做一个优化,两者之间选一个最优的
4. 优化查询2
为order by和select字段添加联合索引
# 创建联合索引
ALTER TABLE student ADD INDEX idx_score_name_id (score, name, id);
深分页:
# 深分页
EXPLAIN
SELECT id, name, score from student order by score desc limit 4500000, 20;
执行效率:使用索引,并且使用了覆盖索引(Using index)

执行时间:1.117,这里查询时间也是加快的很多

优点:深分页查询速度得到明显提升
缺点:当新增一个查询字段时,索引就会失效
5. 优化查询3
删除联合索引,防止干扰
# 删除联合索引,防止干扰
drop index idx_score_name_id on student;
深分页:
EXPLAIN
SELECT t1.id, t1.name, t1.score from student t1 join
(select id from student order by score desc limit 4500000, 20) t2 on t1.id = t2.id;
执行效率:效执行里面的子查询,查询走的是索引,然后再从子查询中获取到的20条数据在进行查询,查询走的是PRIMARY

查询时间:1.054s

优点: 深查询得到明显提升
缺点: 当子查询结果集过多时不推荐使用
6. 优化查询4
先将所有数据排序好,先根据score进行降序排序,score相同的情况下再根据id进行降序排序,然后在取前20条数据,这里还得和前端配合,前端每次发送请求都携带最后一个的id值和score值
EXPLAIN
SELECT id, name, score from student
WHERE id < 10000000 AND score <= 100
ORDER BY score DESC LIMIT 20;
执行效率:type类型为range

执行时间:0.034s

执行下一页:获取上一页最后一个id值和score值
SELECT id, name, score from student
WHERE id < 4975166 AND score <= 99.9
ORDER BY score DESC LIMIT 20;
7. 总结
- 浅分页可以给order by字段添加索引
- 深分页可以给order by和select字段添加联合索引
- 通过手动回表,走联合索引
- 从业务方面思考,获取对应数据















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









