










一、三十年的激活函数:对 400 种神经网络激活函数的全面调查

1.1、论文概述
标题:三十年的激活函数:对 400 种神经网络激活函数的全面调查
作者:Vladimír Kunc 和 Jiří Kléma
日期:2024年2月15日
1.2、引言
背景:神经网络在许多领域中表现出色,特别是深度学习的普及进一步增强了其在复杂问题处理中的实用性。激活函数在网络中引入了非线性,允许模型捕捉数据中的复杂关系。
问题:尽管有多种激活函数被提出,文献中缺乏一个集中和全面的资源。作者指出这种缺失导致了研究上的重复和对已有激活函数的无意重新发现。
目标:论文旨在提供涉及400种激活函数的详尽综述,成为研究者在选择激活函数时的宝贵参考。
1.3、激活函数的分类
论文将激活函数分为两大类:
固定激活函数(如 sigmoid、tanh 和 ReLU):这些函数的形式是预先定义的,针对所有输入应用相同的变换。
自适应激活函数(AAF):参数可以根据输入数据进行学习,从而改变形状,提供了更高的灵活性和更快的收敛速度。
1.4、文献综述
尽管已有一些关于激活函数的综述文献,许多仅涵盖了常见的激活函数。这限制了对激活函数深入研究的效率。作者分析了这些文献的局限性,并指出许多新的激活函数自上一次综述以来已被提出。
1.5、主要贡献及目标
该论文的主要目标是提供一个包含400个激活函数的广泛资源,以填补文献中的空白,避免不必要的冗余研究。虽然论文并未进行深入的基准测试,但提供的列表将成为研究人员选择激活函数的宝贵参考资源。
1.6、结果与讨论
论文指出固定激活函数和自适应激活函数之间的区别,强调了自适应激活函数在灵活性和训练效果方面的优势。尽管作者承认这项研究没有全面的基准测试,但他们希望通过提供这一详尽的列表,促进激活函数的研究与应用。
总体来说,这篇论文通过提供400种激活函数的广泛调查,为神经网络激活函数的研究提供了重要的参考资料。它不仅帮助研究人员避免了研究的重复,同时也为未来关于激活函数的研究奠定了基础。尽管这个列表可能永远不会完全,但它为探索激活函数的未来研究提供了一个坚实的起点。
二、Sigmoid激活函数
主要用于二分类问题的输出层,或早期神经网络中的隐藏层。
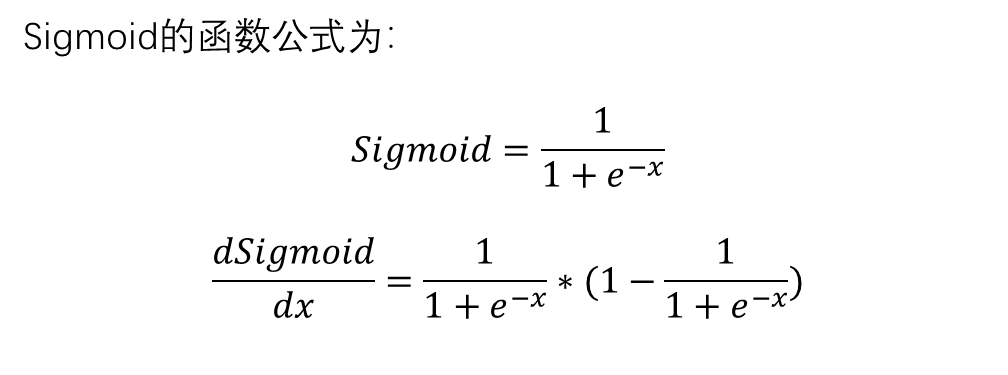
import numpy as np
import matplotlib.pyplot as plt
# Sigmoid激活函数
def sigmoid(x):
# 计算 Sigmoid 函数的值
return 1/(1+np.exp(-x))
def sigmoid_derivative(x):
# 计算 Sigmoid 函数的导数,使用链式法则
return sigmoid(x)*(1-sigmoid(x))
# 生成从 -10 到 10 的 100 个均匀分布的点
x = np.linspace(-10, 10, 100)
# 计算 Sigmoid 函数在 x 上的值
y_sigmoid = sigmoid(x)
# 计算 Sigmoid 函数导数在 x 上的值
y_sigmoid_derivative = sigmoid_derivative(x)
# 创建一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制 Sigmoid 函数
plt.plot(x, y_sigmoid, label='sigmoid')
# 绘制 Sigmoid 导数
plt.plot(x, y_sigmoid_derivative, label='sigmoid_derivative')
# 显示图例
plt.legend()
# 添加网格以便于查看
plt.grid()
# 显示绘图
plt.show() 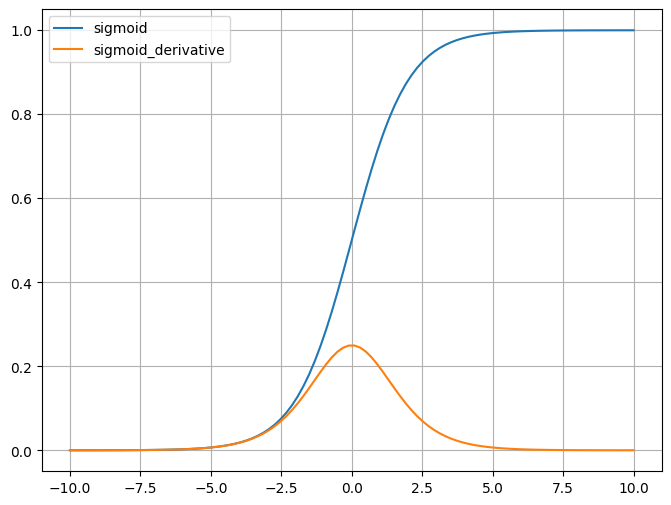
特点:
Sigmoid 函数的输出范围被限制在 0 到 1 之间,这使得它适用于需要将输 出解释为概率或者介于 0 和 1 之间的 任何其他值的场景。 Sigmoid 函数的两端,导数的值非常 接近于零,这会导致在反向传播过程 中梯度消失的问题,特别是在深层神 经网络中。
Sigmoid激活函数有着如下几种缺点:
梯度消失:Sigmoid函数趋近0和1的时候变化率会变得平坦,从导数图像可以看出,当x值趋向两 侧时,其导数趋近于0,在反向传播时,使得神经网络在更新参数时几乎无法学习到低层的特征, 从而导致训练变得困难。
不以零为中心:Sigmoid函数的输出范围是0到1之间,它的输出不是以零为中心的,会导致其参数 只能同时向同一个方向更新,当有两个参数需要朝相反的方向更新时,该激活函数会使模型的收敛 速度大大的降低。 在 Sigmoid 函数中,输出值恒为正。这也就是说,如果上一级神经元采用 Sigmoid 函数作为激 活函数,那么我们无法做到此层的输入 和 符号相反。此时,模型为了收敛,不得不向逆风 前行的风助力帆船一样,走 Z 字形逼近最优解。 模型参数走绿色箭头能够最快收敛,但由于输入值的符号总是为正,所以模型参数可能走类似红色 折线的箭头。如此一来,使用 Sigmoid 函数作为激活函数的神经网络,收敛速度就会慢上不少了。
计算成本高:Sigmoid激活函数引入了exp()函数,导致其计算成本相对较高,尤其在大规模的深度 神经网络中,可能会导致训练速度变慢。
不是稀疏激活:Sigmoid函数的输出范围是连续的,并且不会将输入变为稀疏的激活状态。在某些 情况下,稀疏激活可以提高模型的泛化能力和学习效率。
三、tanh激活函数
常用于隐藏层,因为其更好地适应了输入数据的平均值。
该函数解决了Sigmoid函数不以零为中心的问题,它的取值范围是(-1,1),无限接近1和-1,但永不 相等。
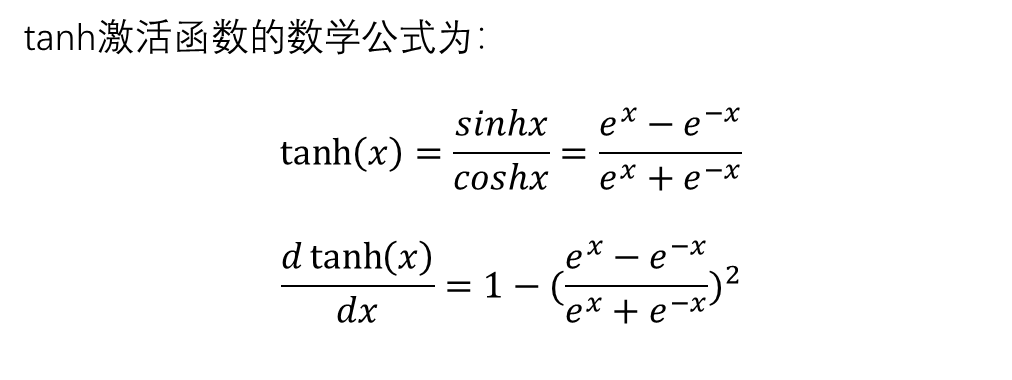
import numpy as np
import matplotlib.pyplot as plt
# tanh激活函数
def tanh(x):
# 计算 tanh 函数的值,使用指数函数的定义
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
def tanh_derivative(x):
# 计算 tanh 函数的导数,利用导数公式 1 - tanh(x)^2
return 1 - tanh(x)**2
# 生成从 -10 到 10 的 100 个均匀分布的点
x = np.linspace(-10, 10, 100)
# 计算 tanh 函数在 x 上的值
y_tanh = tanh(x)
# 计算 tanh 函数导数在 x 上的值
y_tanh_derivative = tanh_derivative(x)
# 创建一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制 tanh 函数
plt.plot(x, y_tanh, label='tanh')
# 绘制 tanh 导数
plt.plot(x, y_tanh_derivative, label='tanh_derivative')
# 显示图例
plt.legend()
# 添加网格以便于查看
plt.grid()
# 显示绘图
plt.show() 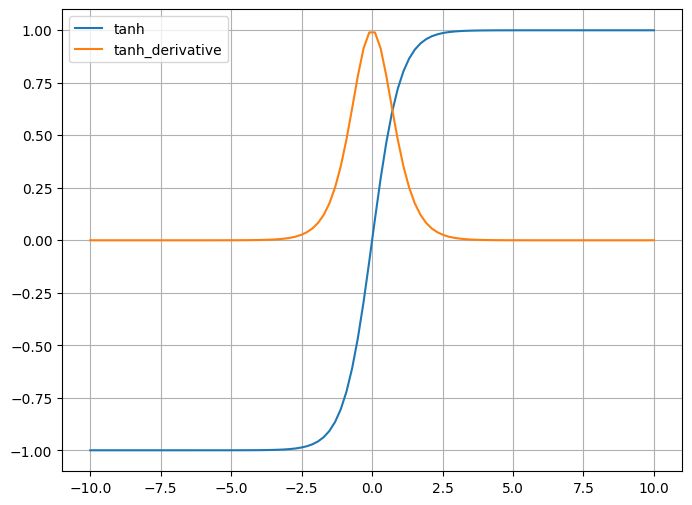
特点:
输出范围:tanh 函数的输出范围被限 制在 -1 到 1 之间,因此它可以使神经 网络的输出更接近于零中心,有助于 减少梯度消失问题。
零中心性:tanh 函数的输出以零为中 心,即在输入为 0 时函数值为 0,这 有助于减少梯度消失问题,并使得神 经网络更容易学习。
相对于Sigmoid函数,优势:
输出以零为中心:tanh函数的输出范围是-1到1之间,其均值为零,因此它是零中心的激活函数。 相比于Sigmoid函数,tanh函数能够更好地处理数据的中心化和对称性,有助于提高网络的学习效 率。
饱和区域更大:在输入绝对值较大时,tanh函数的斜率较大,这使得它在非线性变换上比Sigmoid 函数更加陡峭,有助于提供更强的非线性特性,从而提高了网络的表达能力。
良好的输出范围:tanh函数的输出范围在-1到1之间,相比于Sigmoid函数的0到1之间,输出范围 更广,有助于减少数据在网络中传播时的数值不稳定性。
缺点:
容易出现梯度消失问题:虽然相比于Sigmoid函数,tanh函数在非饱和区域的斜率较大,但在输入 绝对值较大时,其导数仍然会接近于零,可能导致梯度消失问题。
计算难度同样大。
四、ReLU激活函数
广泛用于深度学习的隐藏层,尤其是卷积神经网络(CNN)。
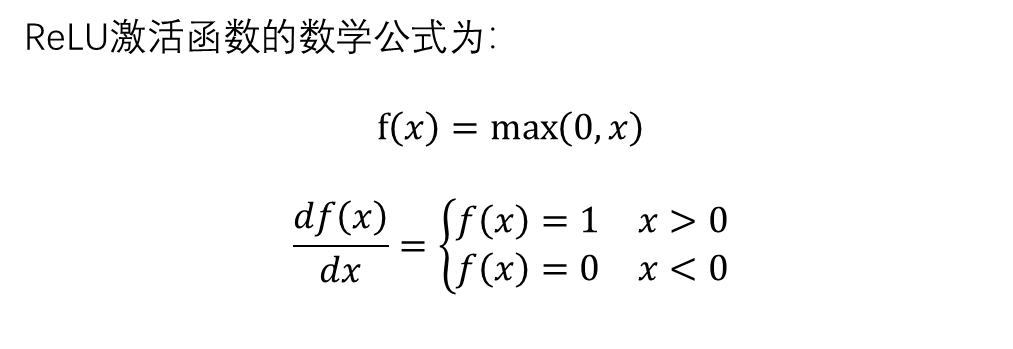
import numpy as np
import matplotlib.pyplot as plt
# ReLU激活函数
def ReLU(x):
# 计算 ReLU 函数的值,返回 x 和 0 中的较大值
return np.maximum(0, x)
def ReLU_derivative(x):
# 计算 ReLU 函数的导数,当 x > 0 时导数为 1,否则为 0
return np.where(x > 0, 1, 0)
# 生成从 -10 到 10 的 100 个均匀分布的点
x = np.linspace(-10, 10, 100)
# 计算 ReLU 函数在 x 上的值
y_ReLU = ReLU(x)
# 计算 ReLU 函数导数在 x 上的值
y_ReLU_derivative = ReLU_derivative(x)
# 创建一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制 ReLU 函数
plt.plot(x, y_ReLU, label='ReLU')
# 绘制 ReLU 导数
plt.plot(x, y_ReLU_derivative, label='ReLU_derivative')
# 显示图例
plt.legend()
# 添加网格以便于查看
plt.grid()
# 显示绘图
plt.show() 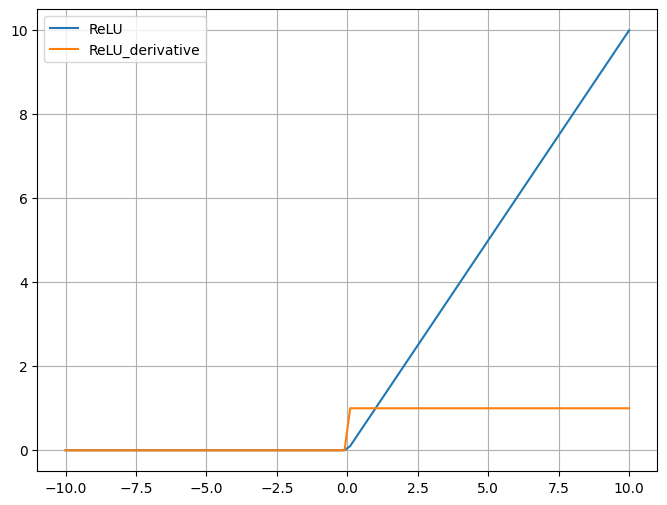
特点:
稀疏性:ReLU 函数的导数在输入为负数时为零, 这意味着在反向传播过程中,只有激活的神经元 会传递梯度,从而促进了稀疏激活的现象,有助 于减少过拟合。
计算高效:ReLU 函数的计算非常简单,并且在 实践中被证明是非常高效的。
解决梯度消失问题: ReLU函数在输入大于零时 输出输入值,这使得在反向传播时梯度保持为常 数1,避免了梯度消失问题。ReLU函数在深度网 络中更容易训练。
ReLU函数的优势:
解决梯度消失问题: ReLU函数在输入大于零时输出输入值,这使得在反向传播时梯度保持为常数 1,避免了梯度消失问题。相比于Sigmoid和tanh函数,ReLU函数在深度网络中更容易训练,使得 网络能够更有效地学习复杂的特征。
计算速度快: ReLU函数的计算非常简单,只需进行一次阈值判断和取最大值操作。这使得在大规 模深度神经网络中,ReLU函数的计算速度远快于Sigmoid和tanh函数,加快了模型训练的速度。
稀疏激活性: 在输入小于零的情况下,ReLU函数的输出是零,这表现为稀疏激活性。这意味着在 激活后,一部分神经元将被激活,而其他神经元则保持不活跃。这有助于减少神经网络中的冗余计 算和参数数量,提高了网络的泛化能力。
劣势:
死亡ReLU问题(Dying ReLU): 在训练过程中,某些神经元可能会遇到“死亡ReLU”问题,即永远 不会被激活。如果某个神经元在训练过程中的权重更新导致在其上的输入始终为负值,那么它的输 出将永远为零。这意味着该神经元不会再学习或参与后续训练,导致该神经元“死亡”,从而减少了 网络的表达能力。
输出不是以零为中心: ReLU函数的输出范围是从零开始,因此输出不是以零为中心的。这可能会 导致训练过程中的参数更新存在偏差,降低了网络的优化能力。
不适合所有问题: 尽管ReLU函数在大多数情况下表现良好,但并不是适合所有问题。对于一些问 题,特别是在处理一些包含负值的数据时,ReLU函数可能不够理想,可能会产生不良的结果。
针对ReLU函数的劣势,研究人员也提出了一些改进的激活函数,如Leaky ReLU、Parametric ReLU和 Exponential Linear Units(ELU)等,这些函数在一定程度上缓解了ReLU函数的问题,并在特定情况下 表现更好。因此,在实际使用中,根据具体问题和实验结果选择合适的激活函数是很重要的。
五、Softmax函数
通常用作多分类问题的输出层。

import numpy as np
import matplotlib.pyplot as plt
# Softmax函数
def Softmax(x):
# 计算 Softmax 函数的值
# Softmax 函数用于将输入向量转换为概率分布
return np.exp(x) / np.sum(np.exp(x))
def Softmax_derivative(x):
# 计算 Softmax 函数的导数
# 导数使用了雅可比矩阵的定义
s = Softmax(x) # 计算 Softmax 值
return np.diagflat(s) - np.outer(s, s) # 返回雅可比矩阵
# 生成从 0 到 10 的 100 个均匀分布的点
x = np.linspace(0, 10, 100)
# 计算 Softmax 函数在 x 上的值
y_Softmax = Softmax(x)
# 计算 Softmax 函数导数在 x 上的值
y_Softmax_derivative = Softmax_derivative(x)
# 创建一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制 Softmax 函数
plt.plot(x, y_Softmax, label='Softmax')
# 创建另一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制 Softmax 导数
plt.plot(x, y_Softmax_derivative, label='Softmax_derivative')
# 显示所有绘图
plt.show() 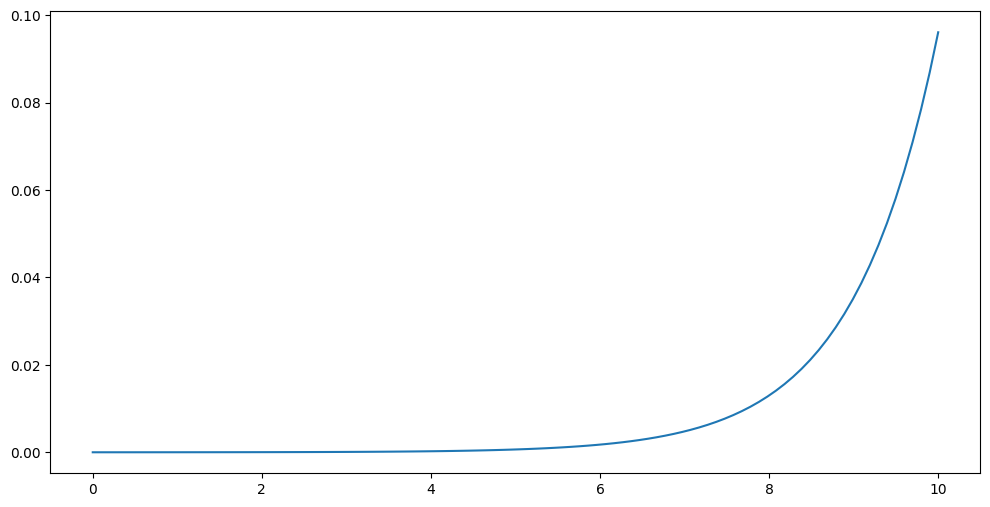
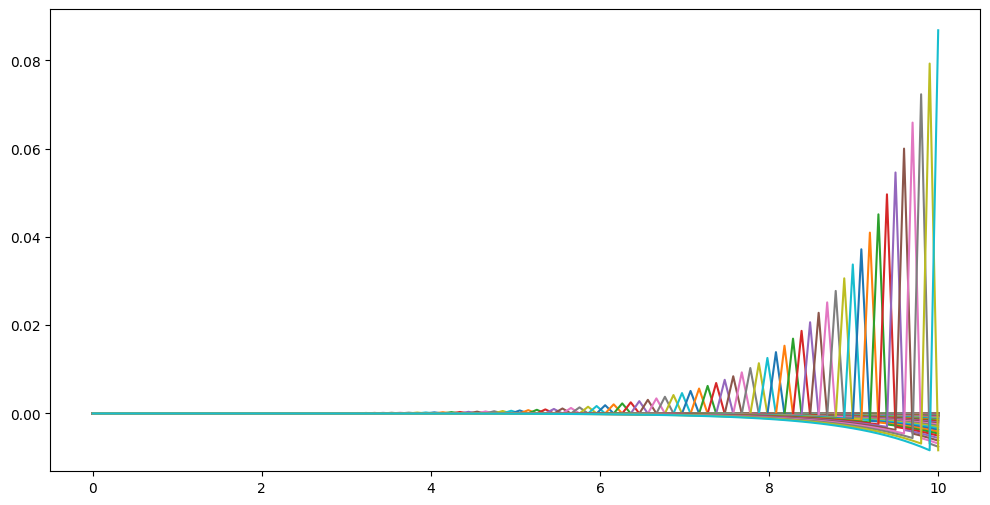
特点:
概率分布:Softmax 函数将输入转换为概率分布,因此在多分 类问题中常用于将模型的原始输出转换为概率值。
连续可导:Softmax 函数是连续可导的,这使得它可以与梯度 下降等优化算法一起使用进行训练。
指数增长:Softmax 函数中的指数运算可能会导致数值稳定性 问题,特别是当输入较大时。为了解决这个问题,可以通过减 去输入向量中的最大值来进行数值稳定的计算。
梯度计算简单:Softmax 函数的导数计算相对简单,可以通过 对 Softmax 函数的定义进行微分得到。
六、Likeay-ReLU激活函数
同样广泛用于深度学习,尤其是在有可能会遇到死神经元的问题时。
 Leaky ReLU 通过在负数区域引入小的正 斜率a来避免ReLU的“死亡”问题,允许负数区域的梯度不为零。
Leaky ReLU 通过在负数区域引入小的正 斜率a来避免ReLU的“死亡”问题,允许负数区域的梯度不为零。
import numpy as np
import matplotlib.pyplot as plt
# Likeay-ReLU激活函数
def Likeay_ReLU(x, alpha=0.01):
# 计算 Likeay-ReLU 函数的值
# 当 x > 0 时直接返回 x;否则返回 alpha * x
return np.where(x > 0, x, alpha * x)
def Likeay_ReLU_derivative(x, alpha=0.01):
# 计算 Likeay-ReLU 函数的导数
# 当 x > 0 时导数为 1;否则导数为 alpha
return np.where(x > 0, 1, alpha)
# 生成从 -10 到 10 的 100 个均匀分布的点
x = np.linspace(-10, 10, 100)
# 计算 Likeay-ReLU 函数在 x 上的值
y_Likeay_ReLU = Likeay_ReLU(x)
# 计算 Likeay-ReLU 函数导数在 x 上的值
y_Likeay_ReLU_derivative = Likeay_ReLU_derivative(x)
# 创建一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制常规 ReLU 函数(需要确保变量 y_ReLU 已定义)
plt.plot(x, y_ReLU, label='ReLU') # 这里需要注意 y_ReLU 需要存在
# 绘制 Likeay-ReLU 函数
plt.plot(x, y_Likeay_ReLU, label='Likeay_ReLU')
# 添加图例
plt.legend()
# 添加网格以便于查看
plt.grid()
# 显示图形
plt.show()
# 创建另一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制 Likeay-ReLU 函数
plt.plot(x, y_Likeay_ReLU, label='Likeay_ReLU')
# 绘制 Likeay-ReLU 导数
plt.plot(x, y_Likeay_ReLU_derivative, label='Likeay_ReLU_derivative')
# 添加图例
plt.legend()
# 添加网格以便于查看
plt.grid()
# 显示图形
plt.show() 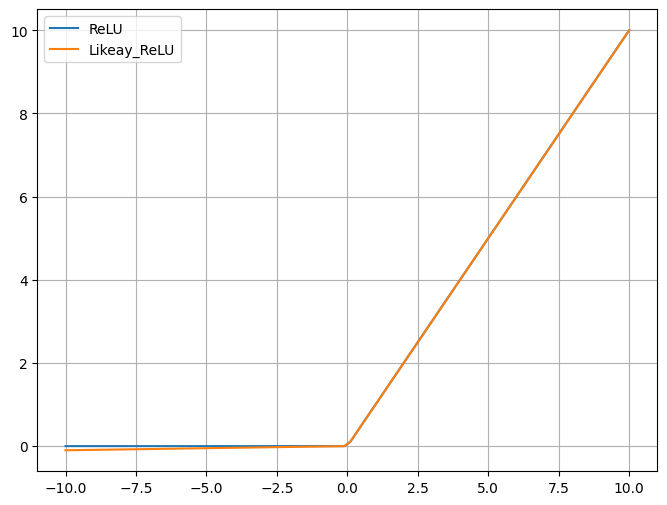

特点:
解决了 ReLU 的“死神经元”问题,因为在 x<0x<0 时依然有一小部分梯度(αα)。
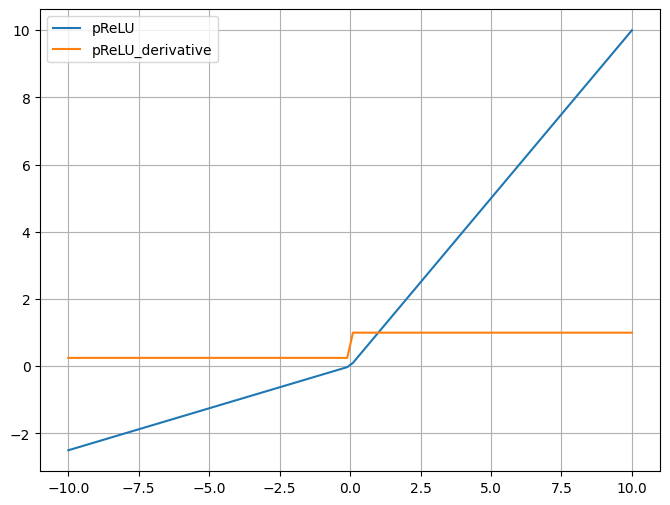
七、PReLU激活函数
常用于深度神经网络中,特别是在对性能要求较高的任务中。
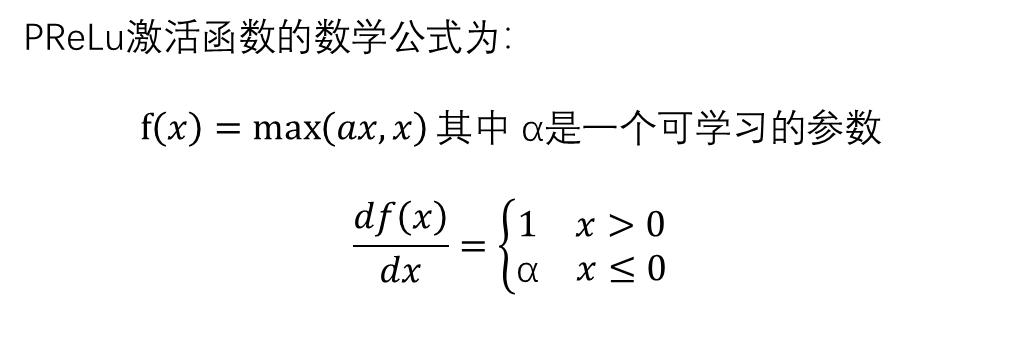
PReLU是Leaky ReLu的一个变种,其 中a是通过学习得到的,这使得模型可以适应性地改变其行为 。
import numpy as np
import matplotlib.pyplot as plt
# PReLU激活函数
def pReLU(x, alpha=0.25):
# 计算 PReLU 函数的值
# 当 x > 0 时直接返回 x;否则返回 alpha * x
return np.where(x > 0, x, alpha * x)
def pReLU_derivative(x, alpha=0.25):
# 计算 PReLU 函数的导数
# 当 x > 0 时导数为 1;否则导数为 alpha
return np.where(x > 0, 1, alpha)
# 生成从 -10 到 10 的 100 个均匀分布的点
x = np.linspace(-10, 10, 100)
# 计算 PReLU 函数在 x 上的值
y_pReLU = pReLU(x)
# 计算 PReLU 函数导数在 x 上的值
y_pReLU_derivative = pReLU_derivative(x)
# 创建一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制常规 ReLU 函数(需要确保变量 y_ReLU 已定义)
plt.plot(x, y_ReLU, label='ReLU') # 这里需要注意 y_ReLU 需要存在
# 绘制 PReLU 函数
plt.plot(x, y_pReLU, label='pReLU')
# 添加图例
plt.legend()
# 添加网格以便于查看
plt.grid()
# 显示图形
plt.show()
# 创建另一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制 PReLU 函数
plt.plot(x, y_pReLU, label='pReLU')
# 绘制 PReLU 导数
plt.plot(x, y_pReLU_derivative, label='pReLU_derivative')
# 添加图例
plt.legend()
# 添加网格以便于查看
plt.grid()
# 显示图形
plt.show() 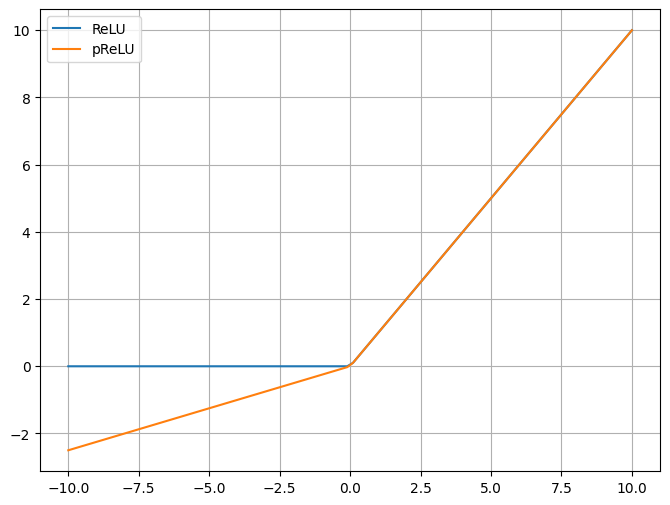
特点:
比 Leaky ReLU 更灵活,因为它允许每个神经元学习自己的泄漏率。
八、ELU激活函数
逐渐在一些深度学习架构中取代 ReLU,已被证明能够在某些情况下提高模型性能。
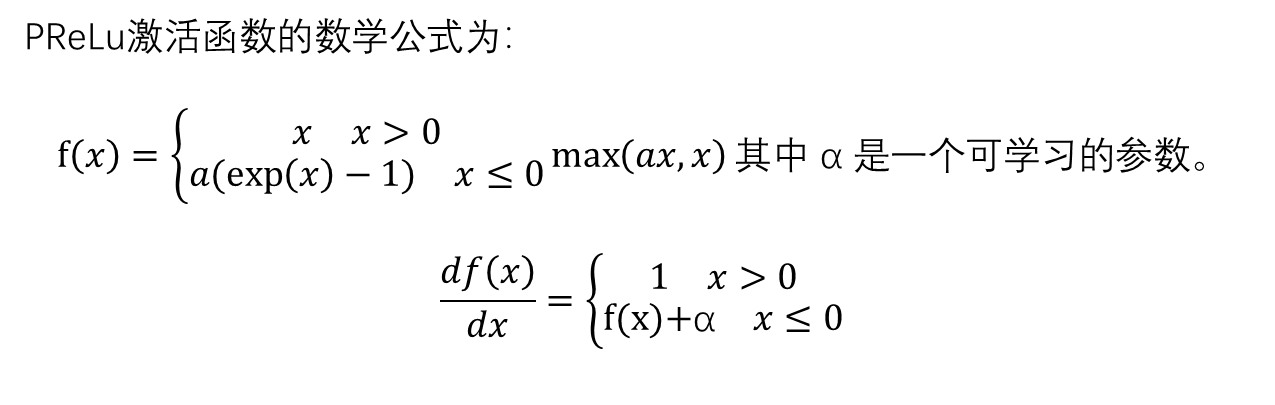
ELU通过在负数区域引入指数衰减,能 够减少ReLU的“死亡”问题,同时保持 负值的输出,有助于保持平均激活接 近零,这有助于加快学习。
import numpy as np
import matplotlib.pyplot as plt
# ELU激活函数
def ELU(x, alpha=0.25):
# 计算 ELU 函数的值
# 当 x > 0 时直接返回 x;否则返回 alpha * (exp(x) - 1)
return np.where(x > 0, x, alpha * (np.exp(x) - 1))
def ELU_derivative(x, alpha=0.25):
# 计算 ELU 函数的导数
# 当 x > 0 时导数为 1;否则为 ELU(x) + alpha
return np.where(x > 0, 1, ELU(x) + alpha)
# 生成从 -10 到 10 的 100 个均匀分布的点
x = np.linspace(-10, 10, 100)
# 计算 ELU 函数在 x 上的值
y_ELU = ELU(x)
# 计算 ELU 函数导数在 x 上的值
y_ELU_derivative = ELU_derivative(x)
# 创建一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制常规 ReLU 函数(需要确保变量 y_ReLU 已定义)
plt.plot(x, y_ReLU, label='ReLU') # 这里需要注意 y_ReLU 需要存在
# 绘制 ELU 函数
plt.plot(x, y_ELU, label='ELU')
# 添加图例
plt.legend()
# 添加网格以便于查看
plt.grid()
# 显示图形
plt.show()
# 创建另一个 8x6 英寸的绘图
plt.figure(figsize=(8, 6))
# 绘制 ELU 函数
plt.plot(x, y_ELU, label='ELU')
# 绘制 ELU 导数
plt.plot(x, y_ELU_derivative, label='ELU_derivative')
# 添加图例
plt.legend()
# 添加网格以便于查看
plt.grid()
# 显示图形
plt.show() 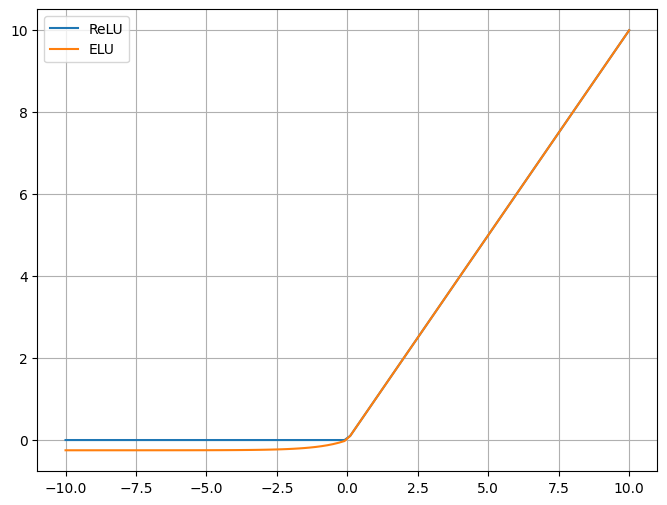
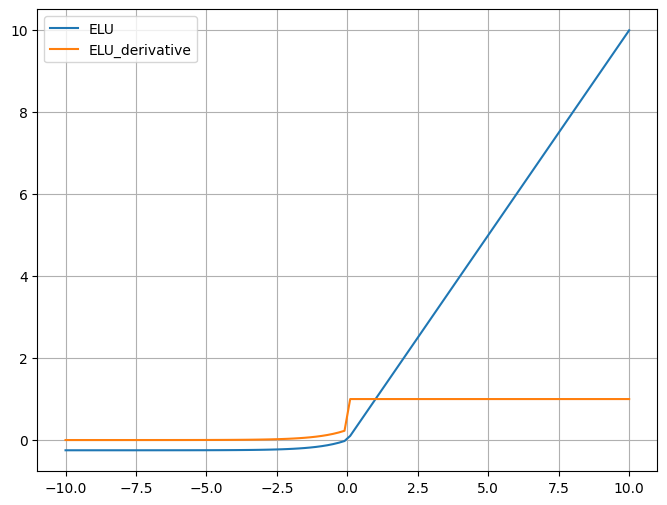
特点:
对于 x<0x<0 会有非零的输出,有助于减少偏移并加速学习。
在 x<0x<0 时,输出接近于某个负值,使得均值接近于零,从而加速学习。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









