










一、论文的基本信息
-
标题: ImageNet Classification with Deep Convolutional Neural Networks(使用深度卷积神经网络的ImageNet分类)
-
作者: Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
-
单位: University of Toronto(多伦多大学)
-
发表会议: NIPS 2012
二、主要内容
这篇论文的主要贡献在于,他们训练了一个大型的深度卷积神经网络(CNN),以对ImageNet LSVRC-2010竞赛中的120万张高分辨率图像进行分类,这些图像属于1000个不同的类别。 该网络在测试数据上取得了显著成果,top-1和top-5的错误率分别为37.5%和17.0%,远超当时的现有技术水平。
这个神经网络拥有6000万个参数和65万个神经元,由五个卷积层、一些最大池化层以及三个全连接层和一个1000路softmax层构成。 为了加快训练速度,他们采用了非饱和神经元和高效的GPU卷积运算实现。 为了减少全连接层中的过拟合现象,他们使用了一种称为“dropout”的正则化方法,并证明该方法非常有效。 此外,他们在ILSVRC-2012竞赛中使用了该模型的一个变体,并取得了15.3%的top-5测试错误率,而第二名的成绩为26.2%。
三、研究的背景
当时,物体识别主要依赖于机器学习方法。 为了提高物体识别的性能,可以采用更大的数据集、更强大的模型以及更好的防止过拟合技术。 然而,之前带有标签的图像数据集相对较小(通常只有几万张图像,例如NORB、Caltech-101/256和CIFAR-10/100)。 虽然简单识别任务在这样规模的数据集上表现良好,但现实场景中的物体具有相当大的可变性,因此需要更大的训练集。 ImageNet数据集的出现,包含超过1500万张带有标签的高分辨率图像,解决了这个问题。
为了从数百万张图像中学习数千个对象,需要一个具有强大学习能力的模型。 由于物体识别任务的复杂性,仅仅依靠大型数据集是不够的,模型还需要大量的先验知识。 卷积神经网络(CNN)正是这样一类模型,它们可以通过调整深度和宽度来控制模型容量,并且对图像的性质具有很强且基本正确的假设(例如,统计数据的平稳性和像素依赖的局部性)。 与具有相似大小层的标准前馈神经网络相比,CNN具有更少的连接和参数,因此更容易训练,并且理论上的最佳性能可能仅略逊于前者。
四、数据集
ImageNet是一个包含超过1500万张带有标签的高分辨率图像的数据集,这些图像属于大约22,000个类别。 图像来自网络,并由人工使用Amazon Mechanical Turk众包工具进行标注。 从2010年开始,作为Pascal Visual Object Challenge的一部分,举办了ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)年度竞赛。 ILSVRC使用ImageNet的一个子集,其中包含1000个类别,每个类别大约有1000张图像。 总共有大约120万张训练图像、50,000张验证图像和150,000张测试图像。 由于ILSVRC-2010是唯一提供测试集标签的ILSVRC版本,因此作者在该版本上进行了大部分实验,同时也在ILSVRC-2012数据集上报告了结果。 ImageNet报告两种错误率:top-1和top-5错误率。
由于ImageNet包含各种分辨率的图像,而他们的系统需要固定的输入维度,因此作者将图像下采样到固定的256x256分辨率。 对于矩形图像,他们首先将图像缩放,使较短的边长为256,然后从结果图像中裁剪出中心的256x256区域。 除了从每个像素中减去训练集上的平均活动外,没有对图像进行任何其他预处理。 因此,他们使用像素的原始RGB值(居中处理后)训练网络。
五、网络架构
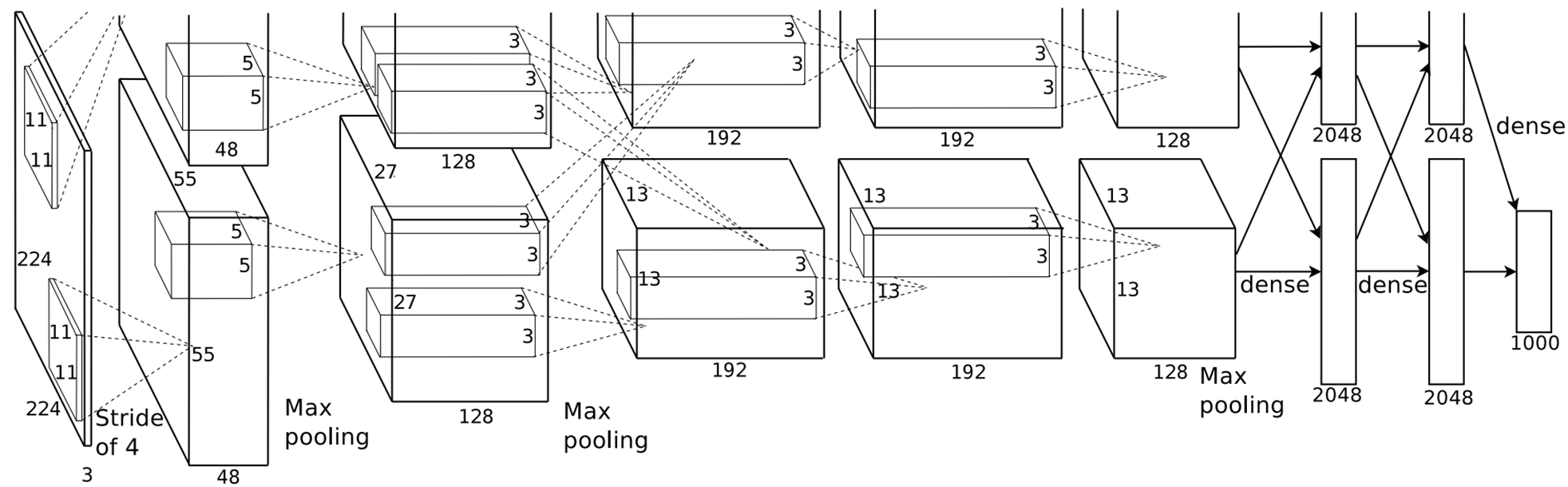
该网络的架构如上图所示,包含八个学习层:五个卷积层和三个全连接层
3.1、ReLU非线性
传统的神经元输出建模方式是使用函数f(x) = tanh(x)或f(x) = (1 + e^(-x))^(-1)。 但就使用梯度下降的训练时间而言,这些饱和非线性函数比非饱和非线性函数f(x) = max(0, x)慢得多。 作者采用了Nair和Hinton提出的方法,将具有这种非线性函数的神经元称为Rectified Linear Units(ReLU)。 带有ReLU的深度卷积神经网络的训练速度比带有tanh单元的网络快好几倍。
3.2、多GPU训练
单个GTX 580 GPU只有3GB的内存,这限制了其上可训练的网络的最大尺寸。 而120万个训练样本足以训练出大到无法放在单个GPU上的网络,因此作者将网络分布在两个GPU上。 他们采用的并行化方案基本上是将一半的核(或神经元)放在每个GPU上,并且只有在某些层进行GPU之间的通信。
3.3、局部响应归一化
LRN 首先是在 AlexNet 中首先,被定义,它的目的在于卷积(即 Relu 激活 函数出来之后的)值进行局部的归一化。
在神经生物学中,有一个概念叫做侧抑制(lateral inhibitio),指的是被激 活的神经元会抑制它周围的神经元,而归一化(normalization)的目的就 是“抑制”,两者不谋而合,这就是局部归一化的动机,它就是借鉴“侧抑制”的 思想来实现局部抑制,当我们使用Relu激活函数的时候,这种局部抑制显得 很有效果。
LRN的主要思想是在神经元输出的局部范围内进行归一化操作,使得激活值 较大的神经元对后续神经元的影响降低,从而减少梯度消失和梯度爆炸的问 题。具体来说,对于每个神经元,LRN会将其输出按照局部范围进行加权平 均,然后将加权平均值除以一个尺度因子(通常为2),最后将结果取平方 根并减去均值,得到归一化后的输出。

3.4、重叠池化
CNN中的池化层用于汇总同一核映射中相邻神经元组的输出。 传统上,相邻池化单元汇总的邻域不重叠。 在这项工作中,作者使用了重叠池化,其中s < z,并且发现这可以稍微提高模型的性能并减少过拟合。
3.5、防止过拟合
AlexNet设置的dropout参数为0.5,AlexNet使用的是 Scale at Training 的 Dropout 实现方式。在训练时,AlexNet通过在前向传播的过程中随机将一 部分神经元的输出置为零,实现了Dropout。在测试时,AlexNet不再使用 Dropout,而是在训练时的基础上将权重按照训练时的概率进行缩放,以保持一致性。
Dropout为什么能够解决过拟合:
(1)减少过拟合: 在标准的神经网络中,网络可能会过度依赖于一些特定 的神经元,导致对训练数据的过拟合。Dropout通过随机丢弃神经元,迫使 网络学习对于任何单个神经元的变化都要更加鲁棒的特征表示,从而减少了 对训练数据的过度拟合。
(2)取平均的作用: 在训练过程中,通过丢弃随机的神经元,每次前向传 播都相当于在训练不同的子网络。在测试阶段,不再进行Dropout,但是通 过保留所有的权重,网络结构变得更加完整。因此,可以看作是在多个不同 的子网络中进行了训练,最终的预测结果相当于对这些子网络的输出取平 均。这种“综合取平均”的策略有助于减轻过拟合,因为一些互为反向的拟合 会相互抵消。
3.6、模型架构细节
3.6.1、输入层(Input Layer)
-
输入尺寸:224×224×3(RGB图像,经中心裁剪和归一化处理)
-
处理步骤:原始图像缩放到224×224
3.6.2、第1层卷积
-
类型:卷积层
-
卷积核:96个,尺寸11×11×3
-
步长(Stride):4
-
填充(Padding):0(实际计算时可能隐式填充2,以保持输出尺寸为整数)
-
输出尺寸:
-
((224-11)+2*P)/4+1=55
-
输出特征图:55*55*96
-
-
激活函数:ReLU
-
附加操作:局部响应归一化(LRN) → 最大池化(Max-Pooling)
-
LRN参数:k=2, n=5, α=10^(-4), β=0.75
-
池化核:3×3
-
池化步长:2(重叠池化)
-
池化后尺寸:27×27×96
-
3.6.3、第2层卷积
-
类型:卷积层
-
卷积核:256个,尺寸5×5×96
-
步长(Stride):1
-
填充(Padding):2(保持输出尺寸不变)
-
输出尺寸:27x27×256
-
激活函数:ReLU
-
附加操作:局部响应归一化(LRN) → 最大池化
-
LRN参数:k=2, n=5, α=10^(-4), β=0.75
-
池化核:3×3
-
池化步长:2(重叠池化)
-
池化后尺寸:13x13×256
-
3.6.4、第3层卷积
-
类型:卷积层
-
卷积核:384个,尺寸3×3×256
-
步长(Stride):1
-
填充(Padding):1(保持输出尺寸不变)
-
输出尺寸:13*13×384
-
激活函数:ReLU
-
附加操作:无池化或归一化
3.6.5、第4层卷积
-
类型:卷积层
-
卷积核:384个,尺寸3×3×192
-
步长(Stride):1
-
填充(Padding):1(保持输出尺寸不变)
-
输出尺寸:13x13×384
-
激活函数:ReLU
-
附加操作:无池化或归一化
3.6.6、第5层卷积
-
类型:卷积层
-
卷积核:256个,尺寸3×3×192(每组GPU处理192个输入通道)
-
步长(Stride):1
-
填充(Padding):1(保持输出尺寸不变)
-
输出尺寸:13×13×256
-
激活函数:ReLU
-
附加操作:最大池化
-
池化核:3×3
-
池化步长:2(重叠池化)
-
池化后尺寸:6×6×256
-
3.6.7、全连接层1
-
类型:全连接层
-
输入尺寸:6×6×256 → 展平为9216维向量(6×6×256=9216)
-
神经元数量:4096
-
激活函数:ReLU
-
附加操作:Dropout(概率0.5)
3.6.8、全连接层2
-
类型:全连接层
-
输入尺寸:4096
-
神经元数量:4096
-
激活函数:ReLU
-
附加操作:Dropout(概率0.5)
3.6.9、输出层
-
类型:全连接层 + Softmax
-
输入尺寸:4096
-
神经元数量:1000(对应ImageNet的1000个类别)
-
输出:1000维概率分布(通过Softmax归一化)
| 层名称 | 操作类型 | 核大小/参数 | 步长 | 填充 | 输入尺寸 | 输出尺寸 | 附加操作 |
|---|---|---|---|---|---|---|---|
| Input | 图像预处理 | - | - | - | 224×224×3 | 224×224×3 | 中心裁剪、归一化 |
| Conv1 | 卷积 | 11×11×3, 96个 | 4 | 2 | 224×224×3 | 55×55×96 | ReLU → LRN → 池化 |
| Pool1 | 最大池化 | 3×3 | 2 | 0 | 55×55×96 | 27×27×96 | - |
| Conv2 | 卷积 | 5×5×48, 256个 | 1 | 2 | 27×27×96 | 27×27×256 | ReLU → LRN → 池化 |
| Pool2 | 最大池化 | 3×3 | 2 | 0 | 27×27×256 | 13×13×256 | - |
| Conv3 | 卷积 | 3×3×256, 384个 | 1 | 1 | 13×13×256 | 13×13×384 | ReLU |
| Conv4 | 卷积 | 3×3×192, 384个 | 1 | 1 | 13×13×384 | 13×13×384 | ReLU |
| Conv5 | 卷积 | 3×3×192, 256个 | 1 | 1 | 13×13×384 | 13×13×256 | ReLU → 池化 |
| Pool5 | 最大池化 | 3×3 | 2 | 0 | 13×13×256 | 6×6×256 | - |
| FC6 | 全连接 | 9216 → 4096 | - | - | 6×6×256 | 4096 | ReLU → Dropout |
| FC7 | 全连接 | 4096 → 4096 | - | - | 4096 | 4096 | ReLU → Dropout |
| FC8 | 全连接 + Softmax | 4096 → 1000 | - | - | 4096 | 1000 | Softmax |
六、网络构建
import torch
import torch.nn as nn
from torchsummary import summary
class AlexNet(nn.Module):
def __init__(self, num=1000): # num: 类别数量
super().__init__()
self.features = nn.Sequential(
# 第1个卷积层: 96个卷积核, 11x11大小, 步长4, 填充2
# 输入: 3x224x224, 输出: 96x54x54 (如果填充=2, 但根据修正后的计算应为 54x54)
nn.Conv2d(3, 96, 11, 4, 2),
nn.ReLU(inplace=True), # ReLU 激活函数, inplace=True 表示原地操作
nn.MaxPool2d(3, 2), # 3x3 最大池化, 步长 2. 输出: 96x26x26 (如果输入是 54x54)
# 第2个卷积层: 256个卷积核, 5x5大小, 步长 1, 填充 2
# 输入: 96x26x26, 输出: 256x26x26
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(inplace=True), # ReLU 激活函数
nn.MaxPool2d(3, 2), # 3x3 最大池化, 步长 2. 输出: 256x12x12
# 第3个卷积层: 384个卷积核, 3x3大小, 步长 1, 填充 1
# 输入: 256x12x12, 输出: 384x12x12
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(inplace=True), # ReLU 激活函数
# 第4个卷积层: 384个卷积核, 3x3大小, 步长 1, 填充 1
# 输入: 384x12x12, 输出: 384x12x12
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(inplace=True), # ReLU 激活函数
# 第5个卷积层: 256个卷积核, 3x3大小, 步长 1, 填充 1
# 输入: 384x12x12, 输出: 256x12x12
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(inplace=True), # ReLU 激活函数
nn.MaxPool2d(3, 2) # 3x3 最大池化, 步长 2. 输出: 256x5x5
)
self.classfiter = nn.Sequential( # 注意: 应该是 "classifier", 这里保持原代码一致
nn.Dropout(p=0.5), # Dropout, 丢弃概率 0.5
nn.Linear(256 * 5 * 5, 4096), # 全连接层, 输入: 256x5x5 展平, 输出: 4096 (修正后的输入大小)
nn.ReLU(inplace=True), # ReLU 激活函数
nn.Dropout(p=0.5), # Dropout, 丢弃概率 0.5
nn.Linear(4096, 4096), # 全连接层, 输出: 4096
nn.ReLU(inplace=True), # ReLU 激活函数
nn.Linear(4096, num), # 全连接层 (输出层), 输出: 类别数量
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1) # 展平特征图, 从维度1开始展平
x = self.classfiter(x)
return x
if __name__ == '__main__':
model = AlexNet()
print(summary(model, (3, 224, 224))) # 打印模型结构和参数信息----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 96, 55, 55] 34,944
ReLU-2 [-1, 96, 55, 55] 0
MaxPool2d-3 [-1, 96, 27, 27] 0
Conv2d-4 [-1, 256, 27, 27] 614,656
ReLU-5 [-1, 256, 27, 27] 0
MaxPool2d-6 [-1, 256, 13, 13] 0
Conv2d-7 [-1, 384, 13, 13] 885,120
ReLU-8 [-1, 384, 13, 13] 0
Conv2d-9 [-1, 384, 13, 13] 1,327,488
ReLU-10 [-1, 384, 13, 13] 0
Conv2d-11 [-1, 256, 13, 13] 884,992
ReLU-12 [-1, 256, 13, 13] 0
MaxPool2d-13 [-1, 256, 6, 6] 0
Dropout-14 [-1, 9216] 0
Linear-15 [-1, 4096] 37,752,832
ReLU-16 [-1, 4096] 0
Dropout-17 [-1, 4096] 0
Linear-18 [-1, 4096] 16,781,312
ReLU-19 [-1, 4096] 0
Linear-20 [-1, 1000] 4,097,000
================================================================
Total params: 62,378,344
Trainable params: 62,378,344
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 11.09
Params size (MB): 237.95
Estimated Total Size (MB): 249.62
----------------------------------------------------------------

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









