









一、梯度消失(Vanishing Gradient)
在深度神经网络中,特别是很深的网络中,梯度消失是一个常见问题。
这指的是在反向传播过程中,网络较深层的权重更新梯度变得非常小,甚至趋于零。
这样的话,底层的权重几乎没有更新,导致网络难以学习到底层的特征。
原因:
在反向传播中,每一层的梯度都是通过链式法则计算得到的,梯度值是前一层梯度和 权重的乘积。当这个乘积小于1时,通过多个层传递下来的梯度就会指数级地减小, 最终趋近于零。
解决方法:
使用激活函数:选择合适的激活函数,如ReLU(Rectified Linear Unit), Leaky ReLU等。这些激活函数能够在一定程度上缓解梯度消失问题。
使用批标准化(Batch Normalization):通过规范化输入数据,可以加速训练 过程并减轻梯度消失问题。
使用残差连接(Residual Connections):在网络中添加跳跃连接,允许梯度直 接通过跳跃连接传播,有助于缓解梯度消失。
二、梯度爆炸(Exploding Gradient)
与梯度消失相反,梯度爆炸是指在反向传播中,网络某一层的梯度变得非常大,甚至 趋于无穷。这会导致权重的更新值变得非常大,破坏网络的稳定性。
原因
当网络权重初始化较大时,反向传播中的梯度也会变得较大。在网络层数较多的情况 下,这些大的梯度会导致权重的更新值变得非常大。
解决方法
权重初始化:使用适当的权重初始化方法,如Xavier初始化,可以缓解梯度爆炸 问题。
梯度裁剪(Gradient Clipping):设置一个梯度阈值,当梯度超过这个阈值时, 将其裁剪为阈值,防止梯度爆炸。
使用梯度规范化技术:如梯度标准化(Gradient Normalization)等,通过规范 化梯度来控制其大小。
在实际应用中,通常需要综合使用这些方法,根据具体情况来解决梯度消失或梯 度爆炸的问题。
三、RNN
3.1、RNN结构
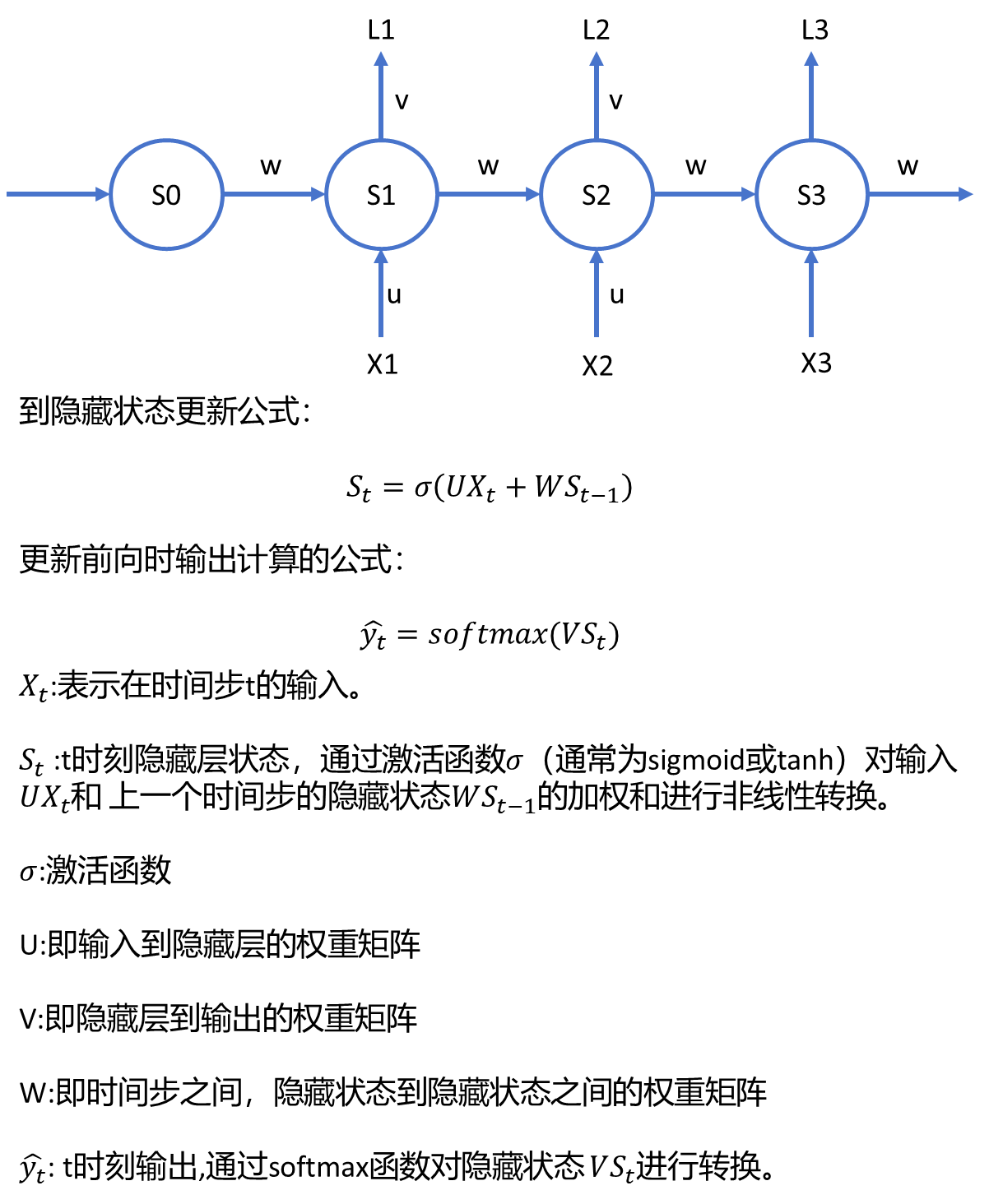
这个结构表明RNN在每个时间步都考虑当前输入和前一个时间步的隐藏状态,使其能 够捕捉序列信息。而交叉熵损失函数则用于衡量模型输出与实际标签之间的差异,是 常用于分类问题的损失函数。
3.2、损失函数

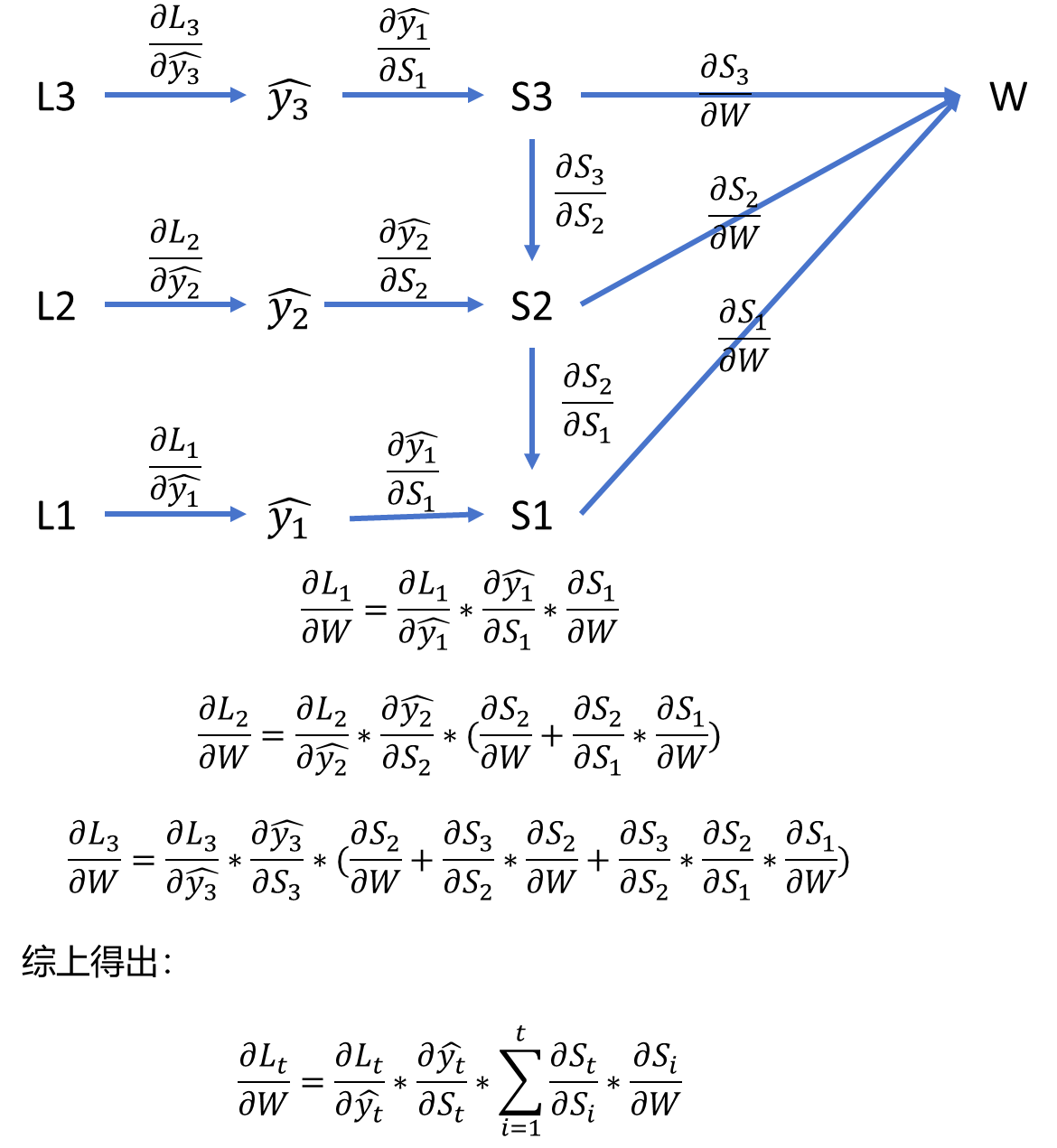
3.3、反向传播
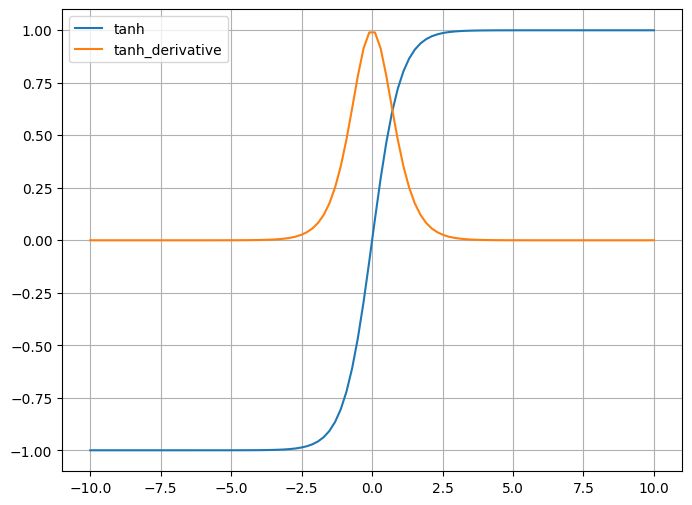
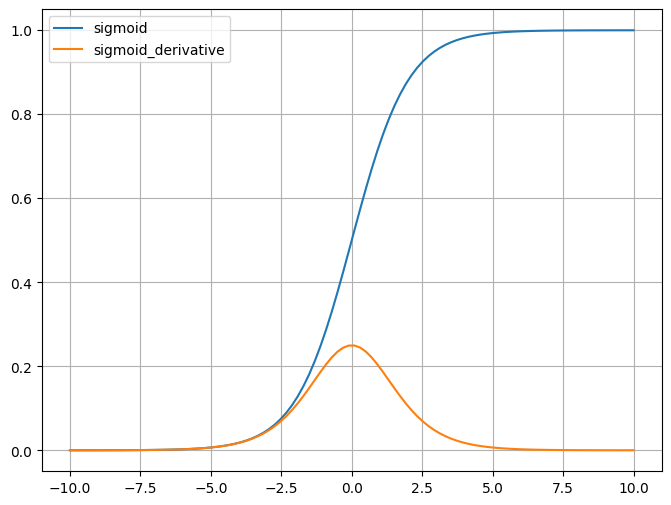
3.4、激活函数
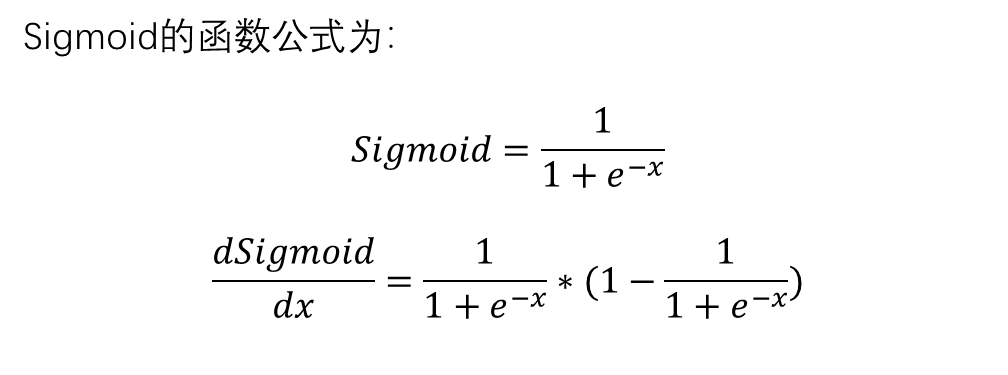
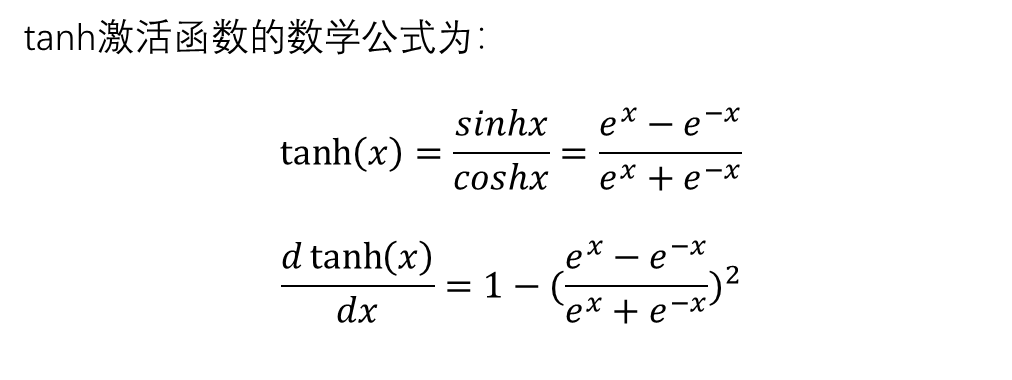
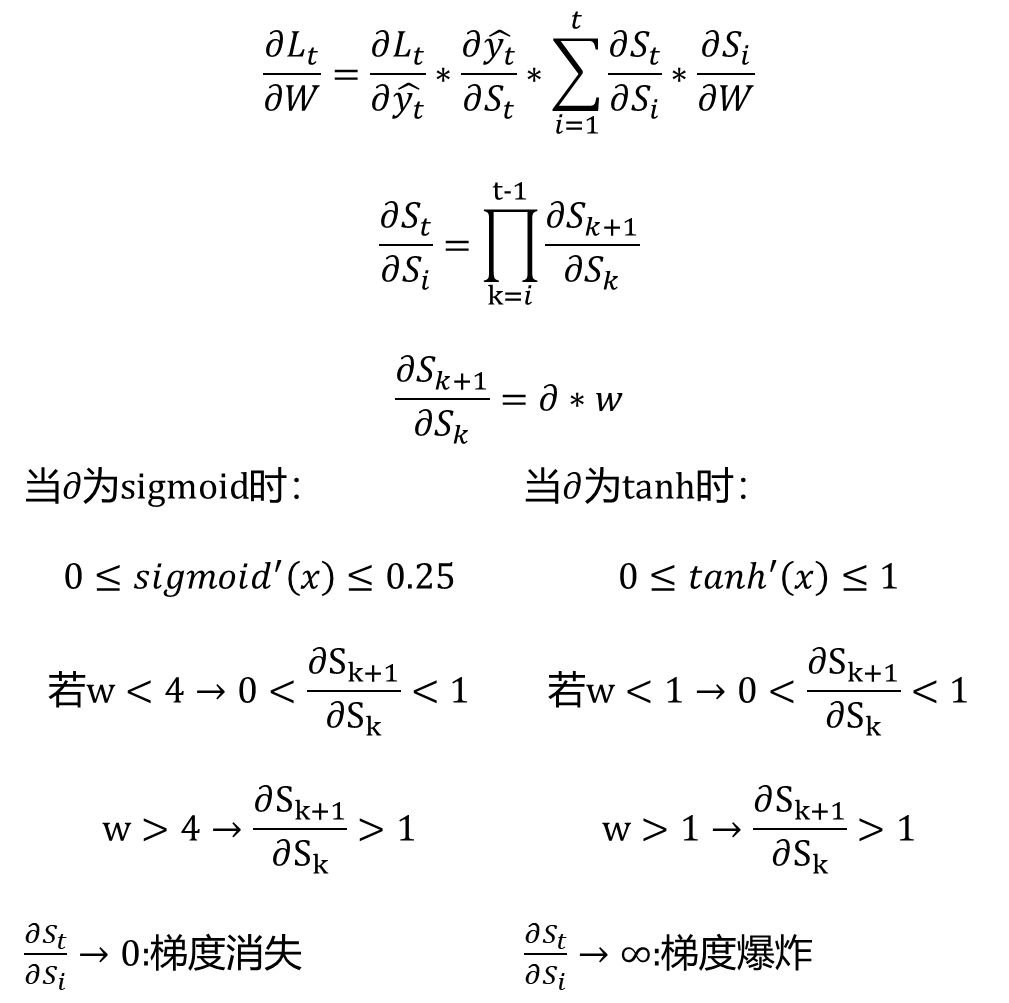
3.5、 梯度爆炸/梯度消失
3.6、设计思路
import numpy as np
import torch
import torch.nn as nn
# 设置随机种子以便于复现
np.random.seed(42)
torch.manual_seed(42)
# 定义一个简单的RNN模型
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(SimpleRNN, self).__init__()
self.Wxh = nn.Parameter(torch.randn(hidden_size, input_size))
self.Whh = nn.Parameter(torch.randn(hidden_size, hidden_size))
self.bh = nn.Parameter(torch.zeros(hidden_size))
def forward(self, x, h):
# torch.mm 是专用于 2D 张量的矩阵乘法。
# torch.matmul 是通用的矩阵乘法函数,支持更高维度的张量和广播操作。
# torch.mm(self.Wxh, x)是输入到隐藏状态的权重矩阵 Wxh 与输入向量 x 的矩阵乘法,这一步计算了输入的线性变换。
# torch.mm(self.Whh, h)是上一个时间步的隐藏状态到当前时间步隐藏状态的权重矩阵 Whh 与上一个时间步的隐藏状态向量 h 的矩阵乘法,这一步计算了循环的部分,即上一个时间步的信息传递到当前时间步。
h_next = torch.tanh(torch.mm(self.Wxh, x) + torch.mm(self.Whh, h) + self.bh)
return h_next
# 准备输入数据
input_size = 10
hidden_size = 5
seq_length = 50 # 50个时间步
# 创建模型实例
rnn = SimpleRNN(input_size, hidden_size)
# 初始化输入和隐藏状态
x = torch.randn(input_size, 1) # 输入向量
h = torch.zeros(hidden_size, 1) # 初始隐藏状态
# 前向传播
for t in range(3):
h = rnn(x, h)
# 计算梯度
loss = torch.sum(h)
loss.backward()
# 打印梯度
print("梯度值:")
print(rnn.Wxh.grad)
print(rnn.Whh.grad)
print(rnn.bh.grad)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









