







完整报告已上传至GitHub上:
一、实验内容
1.实验简介
利用 python 综合训练学习到的部分知识尝试多种简易的西安二手房估价模 型。
主要内容如下:
1.利用爬虫爬取西安二手房数据,爬取网站为
https://xa.lianjia.com/ershoufang/pg2co32/
2.利用办公自动化清洗数据,对定类数据进行编码,方便下一步模型建立 分析。
3.利用办公自动化生成相关词云,利用可视化生成各种图表,直观简单地 展示数据特点。
4.利用科学计算相关知识,尝试建立多种简易较为有效的西安二手房估价 模型。
5.对建立的模型进行分析,给出优点缺点。
2.爬取数据
西安二手房数据爬取
2.1 网站的确立
一个好的网站不仅数据全面,而且利于 python 进行爬取。
该任务为爬取西安二手房价数据,首先确定需要爬取的网站和数据,这是 十分重要的。 经过筛选,选取了链家网站的数据,搜索结果如下(部分截图):
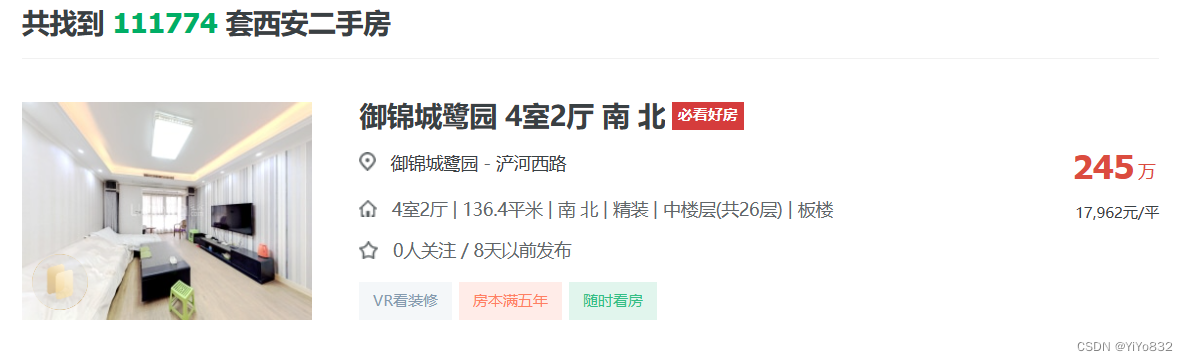
该网站有如下优点:
1.该网站涵盖的数据量巨大,一共含有 111774 个数据,尽管爬取部分数据, 其全面可靠也足够满足建模分析。
2.该网站对于房子的各个特征归纳总结到位,便于分析。
3.该网站便于数据爬取。
2.2 爬取方式的确定
该网站已经整理完毕,并且分类完毕,因此可以选取部分所需数据爬取。
1.进行网站构成分析: 一共有 100 页数据,其中网页链接构成如下:
https://xa.lianjia.com/ershoufang/pg2co32/
构成十分有规律,当进行翻页时,pg 后面的数字加 1 即可,十分利于爬取, 利用一个变量表示页数即可,细节不再赘述。 2.对网页构成分析:发现包含数据的网页不是动态网页,而是静态网页, 直接调用 request 库即可进行访问就可以得到所有所需数据了。
3.对数据包含分析:调用 F12 查看元素可以发现:

所需的数据主要包含在div.info.clear中,可以确定以下几种爬取方式:
1.使用 re 正则匹配式进行查找匹配。该方法直接有效但是容易爬取错误。
2.对于 html 语法树进行匹配,找到对应容器,提取文字即可。该方法不仅 简单有效,而且由于该网站十分规范,不会出现爬取错误数据。
2.3 实战
综上所述,采取了使用lxml包中html语法树进行匹配爬取数据的方式。
核心代码如下:

不再赘述,核心思想就是找到容器,爬取文本。
2.4 爬取的改进
1.加入线程池加速爬取速度 可以知道,如果我们要爬取 100 页,一页一页爬取速度会很慢,因此使用 线程池可以大大加速爬取过程,核心代码如下:

加入线程池后,爬取速度大幅加快,不过出现了 ip 被网站标记,禁止登陆 爬取的问题,最后只爬取到了不到 200 条数据。
2.想办法绕过 ip 封锁 不过这肯定难不倒我,解决办法如下: 访问网页加入 header。 使用time.sleep()缓解了一下我和网页的关系。 代码不再给出,详情可见附录。
2.5 爬取结果及展示
最后通过优化,爬取到了足足 1500 条以上的数据,下面展示部分数据:
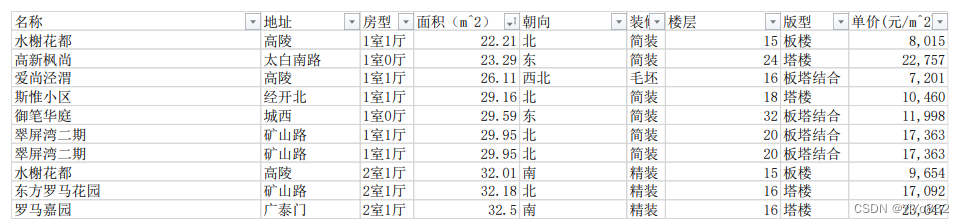
3 可视化实验
3.1 词云
词云有助于我们对文字形成直观清晰的认知,一方面有利于我们进行定量 转换,另一方面有助于我们进行判断数据好坏程度。
3.1.1 数据的选择
理论上所有数据都可以生成词云,但是我选择了二手房地址数据生成词云, 原因如下:
1.地址不好定量转换,最先讨论较好。
2.地址是纯文字,生成词云效果更佳。
3.1.2 代码编写 代码与课堂教学并无过多出入,不再展示,可见附录。
3.1.3 词云展示

可以看到,重点分布在住宅区得多,下面是部分统计分析。

不难得出结论:房子地址也是一个需要考虑的要素,不同地址房子数量分 布不同,进而导致房价波动。
3.2 可视化表格
干巴巴的数字是没有生命力的,但是如果利用各种表格,比如柱状图,折 线图,不仅可以让使用者对数据有清楚的认知,还可以快速找到需要数据的范 围。因此我展开了该实验。
3.2.1 确定图像
想要初步直观观察各个数据的关系,柱状图是比较好的选择。
.2.2 绘图
与课件代码类似,详情见附录,图像如下:
.
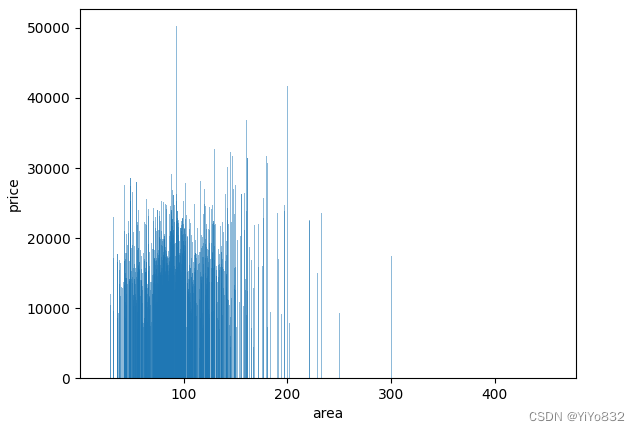
3.2.3 图像分析
通过观察图像可以得到以下结论:
1.大部分房子的面积分布在 50~100 平米之间。
2.90 平左右的房子单价高于附近面积的房子
4 数据清洗及编码
4.1 数据清洗
利用 python 办公自动化,进行了如下情况清洗:
1.装修为“其他”
2.版型为“暂无数据”
3.楼层为“空”
4.单价为“空”
5.其它不符合标准的数据 代码机械重复性工作较多,不再给出,附录也不再给出。
4.2 清洗结果
无法全部展示,但是通过 excel 自带工具可以看到全为有效数据。
4.3 数据编码
进行了如下编码:
1.对装修情况进行编码,编码为 1,2,3… 2.对房型进行编码,编码为 1,2,3… 3.对版型进行编码,编码为 1,2,3… 4.对楼型进行三分位数编码,编码为 1,2,3… 5.对地址进行编码,编码为 1,2,3… 6.对朝向进行编码,编码为 1,2,3… 得到数据部分展示:
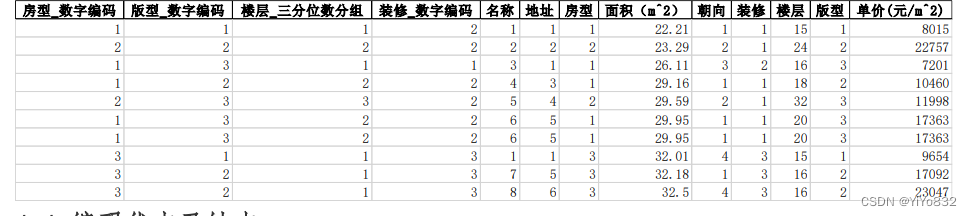
4.4 编码优点及缺点
几乎是不假思索的对所有定量进行了数值化编码,带来了建立模型和分析 方便的好处,但是没有更进一步地思索数据的内在关联,甚至只是粗暴地通过 整数定义。希望未来学习完数学建模可以更进一步地进行改善。
5 基于线性回归模型_尝试 1
5.1 模型的简述
把每个变量都是为线性影响房价,然后根据最小二乘拟合法可以建立起来 一个简单的线性模型。代码主要是根据上课所学。
5.2 符号,公式说明
由于地址变量还是不好量化,暂且不考虑。 定义各个变量:


5.3 代码
与 PPT 上的相差无几,就是多录入几个变量。核心代码如下:
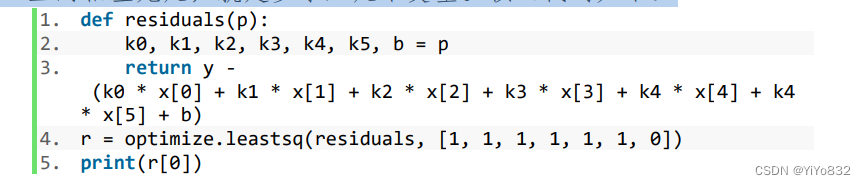
得到的参数如下:

5.4 分析及评估
由初始值和最终参数可知,前四个变量即楼型,版型,楼层,装修提升了 数量级,而面积是负相关,朝向的影响微乎其微。 得到以下结论:
1.房价对楼型,版型,楼层,装修敏感。
2.房价对朝向不敏感
3.房价与面积呈现反相关。
优点:
1.模型简单有效地评估西安二手房价与其它几个变量之间的线性关系。
2.可以反映房价的平均值。
缺点:
1.现实是房价与几个变量不一定呈现线性关系,因此模型并不适用房价。
2.模型与我的编码有极大关系,比如朝向通过编码无法体现线性关系。
3.模型还未考虑地址问题。 4.存在多重共线性问题
6 基于 adaboost 回归模型_尝试 2
6.1 模型简述
我在网上寻找了其它有效的好用的房价预测模型,发现了机器回归模型中 的𝑎𝑑𝑎𝑏𝑜𝑜𝑠𝑡回归模型。 关于模型的介绍不再赘述,因为我也尚未完全掌握。不过,利用该模型我 可以进行定量和定性的分析。
6.2 模型结果
得到的结果如下:
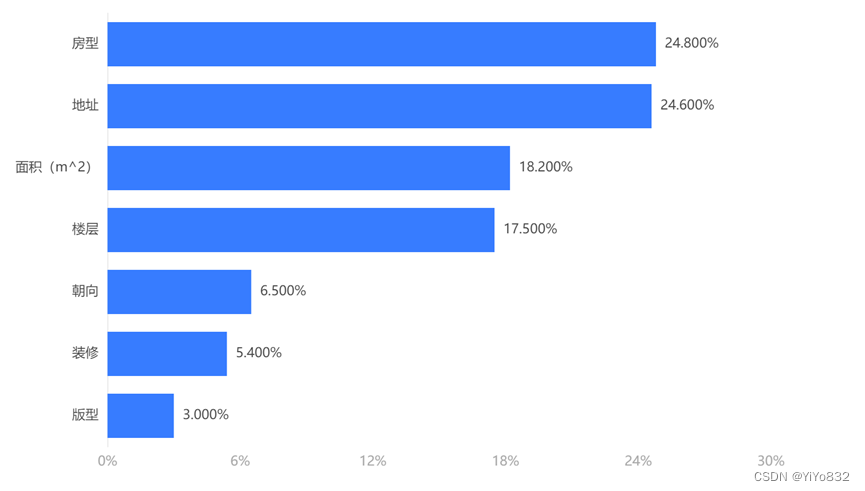
1.特征值重要性
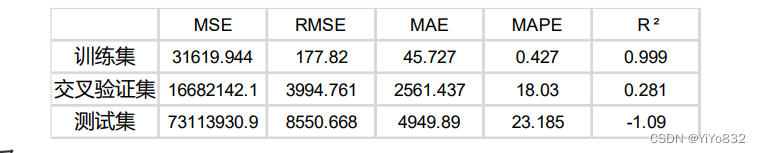
2.模型评估结果
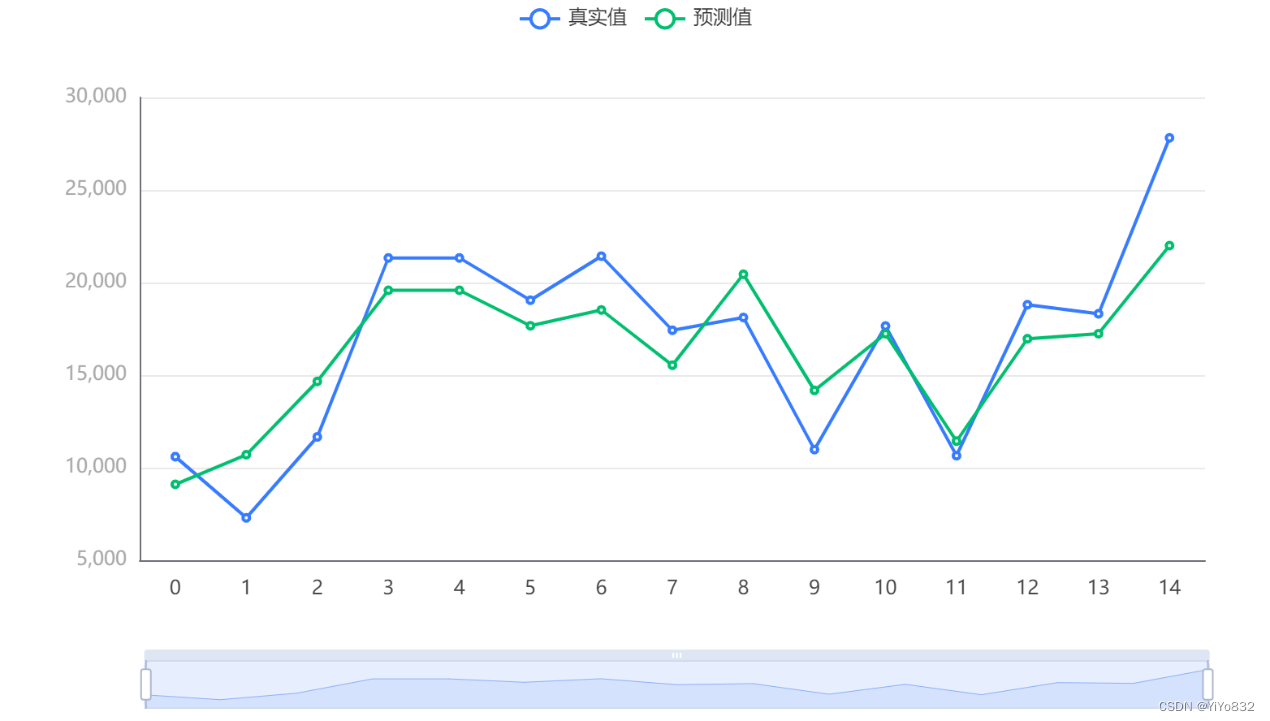
3.预测图
6.3 模型分析
通过上述分析,可以得到以下结论:
1.模型在训练集中表现较好,但测试集中,预测房价的精准度有待提高。
2.影响房价较大的因素表现为房型,地址,面积和楼层。这里可以看到, 地址的作用体现出来了。而在线性模型中较为重要的装修,版型在该模型中不 再被“重视”。
3.在图中可以看到,虽然预测存在误差,但总体趋势保持一致,与线性模型相比算是巨大进步。















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









