







 本文介绍了词法分析中的词性标注和自动分词,重点讲解了最大匹配法(包括正向和逆向)在分词中的应用,以及基于隐马尔可夫模型(HMM)的词性标注过程,讨论了评估指标和参数学习。文章还展示了如何使用Viterbi算法解决解码问题和参数学习的实例。
本文介绍了词法分析中的词性标注和自动分词,重点讲解了最大匹配法(包括正向和逆向)在分词中的应用,以及基于隐马尔可夫模型(HMM)的词性标注过程,讨论了评估指标和参数学习。文章还展示了如何使用Viterbi算法解决解码问题和参数学习的实例。
词是自然语言中能够独立运用的最小单位, 是自然语言处理的基本单位。
自动词法分析就是利用计算机对自然语言 的形态 (morphology) 进行分析,判断词的结构 和类别等。
词性或称词类(Part-of-Speech, POS)是词汇 最重要的特性,是连接词汇到句法的桥梁。
英语基本任务
- 单词识别
- 形态还原
形态还原
(不考核,简单了解) - 有规律变化单词的形态还原(如去 ed,去 ing)
- 动词、名词、形容词、副词不规则变化单词的形态还原
- 对于表示年代、时间、百分数、货币、序数词的 数字形态还原
- 合成词的形态还原
汉语自动分词
自动分词是汉语句子分析的基础
最大匹配法 (Maximum Matching, MM)
简单的举个例子!
![[图片]](https://img-blog.csdnimg.cn/direct/482e2b86f2ec4b10a09ac44e6f93ea84.png)
下面为算法代码实现(python 语言)
正向最大匹配算法 (Forward MM, FMM)
def forward_maximum_matching(input_sentence, word_dictionary, max_word_length):
“”"
该方法实现了前向最大匹配分词算法。
word_dictionary是有限字典,max_word_length是字典中最长单词的长度。
:param input_sentence: 需要进行分词的句子。
:param word_dictionary: 有限字典,用于匹配单词。
:param max_word_length: 字典中最长单词的长度。
:return: 分词完成的结果。
"""
sentence_length = len(input_sentence)
segmented_result = [] # 存放分词结果的列表
index = 0
# 开始匹配
while index < sentence_length:
current_word = ""
for word_length in range(min(max_word_length, sentence_length - index), 0, -1):
current_word = input_sentence[index:index + word_length]
# 找到了最长正向匹配词
if current_word in word_dictionary:
segmented_result.append(current_word)
index += word_length
break
# 没有找到,则将单个字符作为分词
if current_word not in word_dictionary:
segmented_result.append(input_sentence[index])
index += 1
return segmented_result
逆向最大匹配算法 (Backward MM, BMM)
def backward_maximum_matching(sentence, word_set, max_length):
“”"
该方法完成逆向最大匹配分词算法。
word_set和max_length是从文本预处理中获取的变量。
:param sentence: 需要逆向分词的句子。
:param word_set: 有限字典,用于匹配单词。
:param max_length: 字典中最长单词的长度。
:return: 分词完毕的结果。
"""
sentence_length = len(sentence)
segmented_result = []
i = sentence_length
while i > 0:
current_word = ""
for word_length in range(min(max_length, i), 0, -1):
current_word = sentence[i - word_length:i]
if current_word in word_set:
i -= word_length
segmented_result.append(current_word)
break
if current_word not in word_set:
segmented_result.append(sentence[i - 1])
i -= 1
segmented_result.reverse() # 完成反转,因为是从后往前分词
return segmented_result
方法特点
最大匹配分词算法是一种简单的基于词表的分词 方法,有着非常广泛的应用。这种方法只需要最少的语言资源(仅需要一个词表,不需要任何词法、句法、语义知识),程序实现简单,开发周期短,是一个简单实用的方法,但对歧义字段的处理能力不够强大。
最少分词法
应该不考,但是可以简要了解
基本思想
设待切分字串 S=c1 c2…cn,其中 ci (i =1, 2, …, n) 为单个的字, n 为串的长度,n>=1。建立一个节点数 为 n+1 的切分有向无环图 G,各节点编号依次为 V0, V1,V2,…,Vn。 v0 v1 c1 c2 … vi-1 ci-1 ci … cj vj cj+1 … vn cn
![[图片]](https://img-blog.csdnimg.cn/direct/4a6604419b84478980e8e3d30715cb8e.png)
求最短路径:贪心法或简单扩展法。
算法步骤
-
相邻节点 vk-1 , vk 之间建立有向边 <vk-1 , vk,边对应的词默 认为 ck ( k =1, 2, …, n)。
-
如果 w= cici+1…cj (0<i<j<=n) 是一个词,则节点 vi-1 , vj 之间建 立有向边 <vi-1 , vj,边对应的词为 w。
 -
重复步骤(2),直到没有新路径(词序列)产生。
-
从产生的所有路径中,选择路径最短的(词数最少的)作为 最终分词结果。
评价指标
假设得到了如下的矩阵:

指标分别如下:
- 精准率:Precise:P = a / (a+b)
- 召回率: Recall: R = a/ (a+c)
- F measure: F1 = 2PR / (P+R)
- 正确率:Accuracy: Acc = (a+d) / (a+b+c+d)
词性标注
隐马尔可夫模型
对于马尔科夫链的前置知识不再赘述,可以自行学习
简述马尔可夫链【通俗易懂】
基本概念
隐马尔可夫模型是对马尔可夫链的扩展
- 状态(State):词性序列
- 观测(Obsrvation):词序列
图模型如下:
![[图片]](https://img-blog.csdnimg.cn/direct/c53d02d27b76486e96c7c01c27a3f802.png)
参数
参数说明
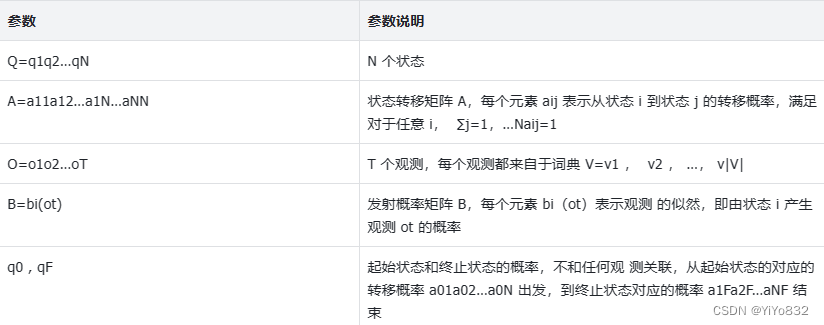
举个例子:
假设你是一个在 2215 年研究气候变暖的气象学家,却找不到北京 2015 年夏天的天气数据记录,但是有 Lee 的日记,记录了夏天每天吃了多少根冰淇淋,你的工作:推算出这个夏天有多热
给定:
Ice Cream 序列(观测):1, 2, 3, 2, 2, 2, 3…
求解:
Weather 序列(状态):Hot, Cold, Hot, Hot, Hot, Cold…?
解答:
假设最后建立如下模型
![[图片]](https://img-blog.csdnimg.cn/direct/cd43b832735a4740965ffcdf0ba866cc.png)
三个基本问题
Problem 1 (估算问题):
– 给定观测序列 O=(o1o2…oT ),及 HMM 模型参数λ= (A,B)
– 如何计算 P(O|Φ),即计算产生某个观测序列的概率(观测的似 然)
Problem 2 (解码问题):
– 给定观测序列 O=(o1o2…oT ),及 HMM 模型参数λ= (A,B)
– 如何计算最优的状态序列 Q=(q1q2…qT )(i.e。, 能最好解释观测 O 的状态序列)
Problem 3 (参数学习):
– 如何学习模型参数λ = (A,B) 使 P(O|λ)最大化
估算问题
假设回到我们刚刚假设的冰淇淋问题,现在给定观测,冰淇淋的数量序列为 3-1-3,如何计算该观测序列发生的概率?
朴素想法
- 枚举每一个可能的三个状态序列转移
- 对每一个可能出现状态,求取发生观测序列(根据发射概率求解)
- 将步骤 1 和步骤 2 的概率相乘
- 将步骤 3 的所有可能序列概率相加
P ( 313 ) = P ( 313 , c o l d c o l d c o l d ) + P ( 313 , c o l d c o l d h o t ) + P ( 313 , h o t h o t c o l d ) . . . P(313) = P(313, coldcoldcold)+P(313, coldcoldhot)+P(313, hothotcold) ... P(313)=P(313,coldcoldcold)+P(313,coldcoldhot)+P(313,hothotcold)...
前向传播
利用格栅,减少计算,下面是示例:
![[图片]](https://img-blog.csdnimg.cn/direct/7d26e555942f499ba4c8801d0f66eb70.png)
不再赘述
后向算法
(略)
解码问题
假设回到我们刚刚假设的冰淇淋问题,现在给定观测,冰淇淋的数量序列为 3-1-3,如何计算最有可能的状态序列?
算法和估算问题的差不多,可以利用格栅解决,下面给出示例:
Viterbi 算法
![[图片]](https://img-blog.csdnimg.cn/direct/4ac026ca4df94ebe8b68747c0c198831.png)
找到最大概率后,再进行回退找到序列:
![[图片]](https://img-blog.csdnimg.cn/direct/2ad51d757c5649a98d6bb0a43d024025.png)
参数学习
略
例题
给出 A 矩阵
![[图片]](https://img-blog.csdnimg.cn/direct/ef02bfed2f704ba5940b2e609aa63c4f.png)
给出 B 矩阵
![[图片]](https://img-blog.csdnimg.cn/direct/283ebe19883b4bcf82563a91389f63b1.png)
即可进行求解:
![[图片]](https://img-blog.csdnimg.cn/direct/2ae00ebcc0ae44c69441030e6ee0672d.png)
图没给全,可以自己脑补
最后的词性标注为:
I(PPSS) want(VB) to(TO) race(VB)
概率为:
P
=
0.067
∗
0.37
∗
0.23
∗
0.0093
∗
0.035
∗
0.99
∗
0.83
∗
0.00012
P = 0.067 * 0.37 * 0.23 * 0.0093 * 0.035*0.99 * 0.83*0.00012
P=0.067∗0.37∗0.23∗0.0093∗0.035∗0.99∗0.83∗0.00012
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









