






java语言中,实现线程有三种基本方式
第一种方式
编写一个类,直接 继承 java.lang.Thread,重写 run方法。
-
怎么创建线程对象? new继承线程的类。
-
怎么启动线程呢? 调用线程对象的
start()方法。
伪代码:
// 定义线程类
public class MyThread extends Thread{
public void run(){
}
}
// 创建线程对象
MyThread t = new MyThread();
// 启动线程。
t.start();
e.g.
public class ThreadTest02 {
public static void main(String[] args) {
MyThread t = new MyThread();
// 启动线程
//t.run(); // 不会启动线程,不会分配新的分支栈。(这种方式就是单线程。)
t.start();
// 这里的代码还是运行在主线程中。
for(int i = 0; i < 1000; i++){
System.out.println("主线程--->" + i);
}
}
}
class MyThread extends Thread {
@Override
public void run() {
// 编写程序,这段程序运行在分支线程中(分支栈)。
for(int i = 0; i < 1000; i++){
System.out.println("分支线程--->" + i);
}
}
}
注意:
-
t.run() 不会启动线程,只是普通的调用方法而已。不会分配新的分支栈。(这种方式就是单线程。)
-
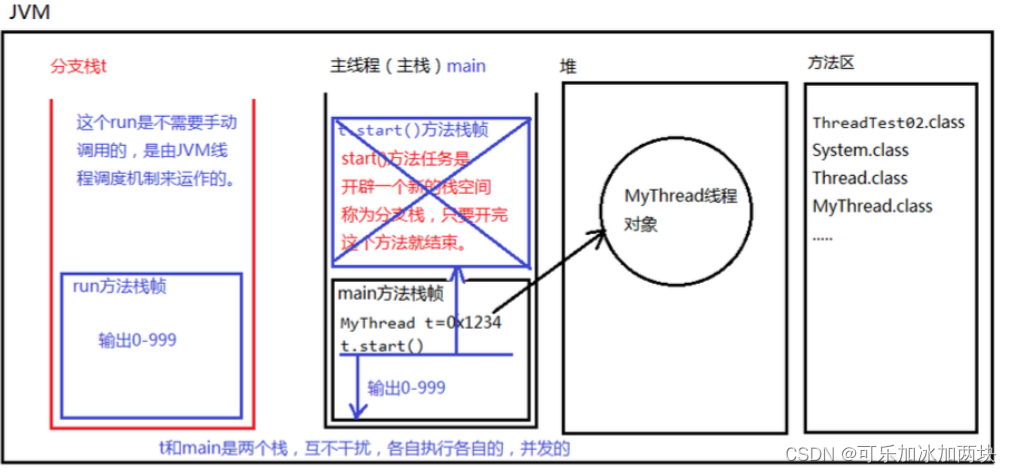
t.start() 方法的作用是:启动一个分支线程,在JVM中开辟一个新的栈空间,这段代码任务完成之后,瞬间就结束了。 这段代码的任务只是为了开启一个新的栈空间,只要新的栈空间开出来,start()方法就结束了。线程就启动成功了。 启动成功的线程会自动调用run方法,并且run方法在分支栈的栈底部(压栈)。 run方法在分支栈的栈底部,main方法在主栈的栈底部。run和main是平级的。
调用run()方法内存图:
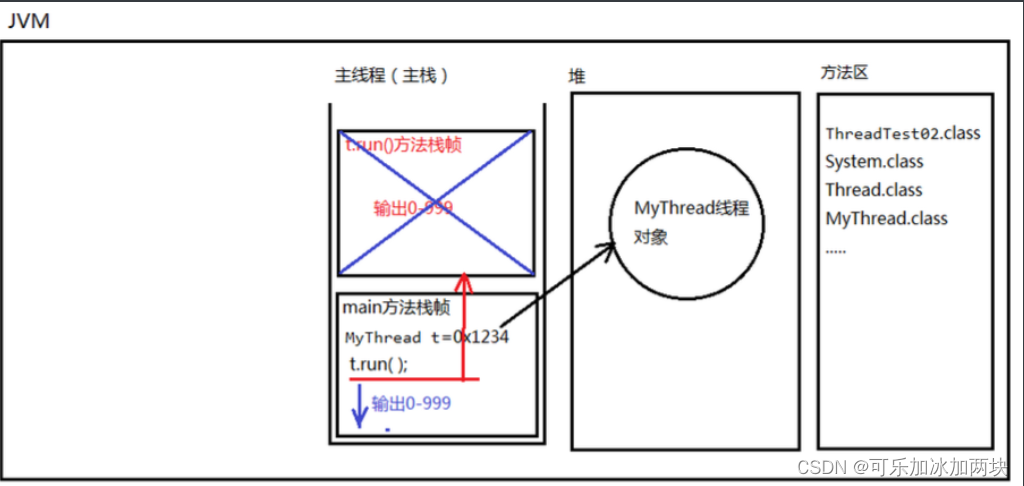
调用start()方法内存图:
第二种方式:
编写一个类,实现 java.lang.Runnable 接口,实现**run方法**。
-
怎么创建线程对象? new线程类传入可运行的类/接口。
-
怎么启动线程呢? 调用线程对象的
start()方法。
伪代码:
// 定义一个可运行的类
public class MyRunnable implements Runnable {
public void run(){
}
}
// 创建线程对象
Thread t = new Thread(new MyRunnable());
// 启动线程
t.start();
eg.
public class ThreadTest03 {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
// 启动线程
t.start();
for(int i = 0; i < 100; i++){
System.out.println("主线程--->" + i);
}
}
}
// 这并不是一个线程类,是一个可运行的类。它还不是一个线程。
class MyRunnable implements Runnable {
@Override
public void run() {
for(int i = 0; i < 100; i++){
System.out.println("分支线程--->" + i);
}
}
}
注意: 第二种方式实现接口比较常用,因为一个类实现了接口,它还可以去继承其它的类,更灵活。
第三种方式
利用Callable接口和Future接口方式实现
Callable接口是Runable接口的增强版。同样用call()方法作为线程的执行体,增强了之前的run()方法。因为call方法可以有返回值,也可以声明抛出异常。
Future接口用来代表Callable接口里的call()方法的返回值,FutureTask类是Future接口的一个实现类,FutureTask类实现了RunnableFuture接口,而RunnnableFuture接口继承了Runnable和Future接口,所以说FutureTask是一个提供异步计算的结果的任务。
步骤如下: 1.创建一个类MyCallable实现Callable接口 2.重写call (是有返回值的,表示多线程运行的结果) 3.创建MyCallable的对象(表示多线程要执行的任务) 4.创建FutureTask的对象(作用管理多线程运行的结果) 5.创建Thread类的对象,并启动(表示线程)
定义任务类,要实现Callable接口,实现接口中的 call() 方法
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int result = 0;
System.out.println(Thread.currentThread().getName() + " Holle world");
for (int i = 0; i < 15; i++) {
result += i;
}
return result;
}
}
创建FutureTask的对象,创建Thread类的对象,并启动
public class ThreadDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
/*多线程的第三种实现方式:
特点:可以获取到多线程运行的结果
*/
//创建MyCallable的对象(表示多线程要执行的任务)
MyCallable mc = new MyCallable();
//创建FutureTask的对象(作用管理多线程运行的结果)
FutureTask<Integer> fu = new FutureTask<>(mc);
FutureTask<Integer> fu1 = new FutureTask<>(mc);
//创建线程的对象
Thread t1 = new Thread(fu);
Thread t2 = new Thread(fu1);
t1.setName("线程1");
t2.setName("线程2");
//启动线程
t1.start();
t2.start();
//获取多线程运行的结果
Integer result1 = fu.get();
Integer result2 = fu1.get();
System.out.println(result1 + " : " + result2);
}
}
线程池
在执行一个异步任务或并发任务时,往往是通过直接new Thread()方法来创建新的线程,这样做弊端较多,更好的解决方案是合理地利用线程池,线程池的优势很明显,如下:
降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的消耗; 提高系统响应速度,当有任务到达时,无需等待新线程的创建便能立即执行; 方便线程并发数的管控,线程若是无限制的创建,不仅会额外消耗大量系统资源,更是占用过多资源而阻塞系统或oom等状况,从而降低系统的稳定性。线程池能有效管控线程,统一分配、调优,提供资源使用率; 更强大的功能,线程池提供了定时、定期以及可控线程数等功能的线程池,使用方便简单。
通用线程工厂
public static class testThreadPoolFactory implements ThreadFactory {
private AtomicInteger threadIdx = new AtomicInteger(0);
private String threadNamePrefix;
public testThreadPoolFactory(String Prefix) {
threadNamePrefix = Prefix;
}
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setName(threadNamePrefix + "-xxljob-" + threadIdx.getAndIncrement());
return thread;
}
}
newCachedThreadPool:
创建一个可缓存的无界线程池,如果线程池长度超过处理需要,可灵活回收空线程,若无可回收,则新建线程。当线程池中的线程空闲时间超过60s,则会自动回收该线程,当任务超过线程池的线程数则创建新的线程,线程池的大小上限为Integer.MAX_VALUE,可看作无限大。
/**
* 可缓存无界线程池测试
* 当线程池中的线程空闲时间超过60s则会自动回收该线程,核心线程数为0
* 当任务超过线程池的线程数则创建新线程。线程池的大小上限为Integer.MAX_VALUE,
* 可看做是无限大。
*/
@Test
public void cacheThreadPoolTest() {
// 创建可缓存的无界线程池,可以指定线程工厂,也可以不指定线程工厂
ExecutorService executorService = Executors.newCachedThreadPool(new testThreadPoolFactory("cachedThread"));
for (int i = 0; i < 10; i++) {
executorService.submit(() -> {
print("cachedThreadPool");
System.out.println(Thread.currentThread().getName());
}
);
}
}
newFixedThreadPool:
创建一个指定大小的线程池,可控制线程的最大并发数,超出的线程会在LinkedBlockingQueue阻塞队列中等待
/**
* 创建固定线程数量的线程池测试
* 创建一个固定大小的线程池,该方法可指定线程池的固定大小,对于超出的线程会在LinkedBlockingQueue队列中等待
* 核心线程数可以指定,线程空闲时间为0
*/
@Test
public void fixedThreadPoolTest() {
ExecutorService executorService = Executors.newFixedThreadPool(5, new testThreadPoolFactory("fixedThreadPool"));
for (int i = 0; i < 10; i++) {
executorService.submit(() -> {
print("fixedThreadPool");
System.out.println(Thread.currentThread().getName());
}
);
}
}
newScheduledThreadPool:
创建一个定长的线程池,可以指定线程池核心线程数,支持定时及周期性任务的执行
/**
* 创建定时周期执行的线程池测试
*
* schedule(Runnable command, long delay, TimeUnit unit),延迟一定时间后执行Runnable任务;
* schedule(Callable callable, long delay, TimeUnit unit),延迟一定时间后执行Callable任务;
* scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit),延迟一定时间后,以间隔period时间的频率周期性地执行任务;
* scheduleWithFixedDelay(Runnable command, long initialDelay, long delay,TimeUnit unit),与scheduleAtFixedRate()方法很类似,
* 但是不同的是scheduleWithFixedDelay()方法的周期时间间隔是以上一个任务执行结束到下一个任务开始执行的间隔,而scheduleAtFixedRate()方法的周期时间间隔是以上一个任务开始执行到下一个任务开始执行的间隔,
* 也就是这一些任务系列的触发时间都是可预知的。
* ScheduledExecutorService功能强大,对于定时执行的任务,建议多采用该方法。
*
* 作者:张老梦
* 链接:https://www.jianshu.com/p/9ce35af9100e
* 来源:简书
* 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
*/
@Test
public void scheduleThreadPoolTest() {
// 创建指定核心线程数,但最大线程数是Integer.MAX_VALUE的可定时执行或周期执行任务的线程池
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(5, new testThreadPoolFactory("scheduledThread"));
// 定时执行一次的任务,延迟1s后执行
executorService.schedule(new Runnable() {
@Override
public void run() {
print("scheduleThreadPool");
System.out.println(Thread.currentThread().getName() + ", delay 1s");
}
}, 1, TimeUnit.SECONDS);
// 周期性地执行任务,延迟2s后,每3s一次地周期性执行任务
executorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ", every 3s");
}
}, 2, 3, TimeUnit.SECONDS);
executorService.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
long start = new Date().getTime();
System.out.println("scheduleWithFixedDelay 开始执行时间:" +
DateFormat.getTimeInstance().format(new Date()));
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = new Date().getTime();
System.out.println("scheduleWithFixedDelay执行花费时间=" + (end - start) / 1000 + "m");
System.out.println("scheduleWithFixedDelay执行完成时间:"
+ DateFormat.getTimeInstance().format(new Date()));
System.out.println("======================================");
}
}, 1, 2, TimeUnit.SECONDS);
}
newSingleThreadExecutor:
创建一个单线程化的线程池,它只有一个线程,用仅有的一个线程来执行任务,保证所有的任务按照指定顺序(FIFO,LIFO,优先级)执行,所有的任务都保存在队列LinkedBlockingQueue中,等待唯一的单线程来执行任务。
/**
* 创建只有一个线程的线程池测试
* 该方法无参数,所有任务都保存队列LinkedBlockingQueue中,核心线程数为1,线程空闲时间为0
* 等待唯一的单线程来执行任务,并保证所有任务按照指定顺序(FIFO或优先级)执行
*/
@Test
public void singleThreadPoolTest() {
// 创建仅有单个线程的线程池
ExecutorService executorService = Executors.newSingleThreadExecutor(new testThreadPoolFactory("singleThreadPool"));
for (int i = 0; i < 10; i++) {
executorService.submit(() -> {
print("singleThreadPool");
System.out.println(Thread.currentThread().getName());
}
);
}
}
线程池原理
Executors类提供4个静态工厂方法:newCachedThreadPool()、newFixedThreadPool(int)、newSingleThreadExecutor和newScheduledThreadPool(int)。这些方法最终都是通过ThreadPoolExecutor类来完成的,这里强烈建议大家直接使用Executors类提供的便捷的工厂方法,能完成绝大多数的用户场景,当需要更细节地调整配置,需要先了解每一项参数的意义。
ThreadPoolExecutor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
创建线程池,在构造一个新的线程池时,必须满足下面的条件:
corePoolSize(线程池基本大小)必须大于或等于0; maximumPoolSize(线程池最大大小)必须大于或等于1;maximumPoolSize必须大于或等于corePoolSize; keepAliveTime(线程存活保持时间)必须大于或等于0; workQueue(任务队列)不能为空; threadFactory(线程工厂)不能为空,默认为DefaultThreadFactory类 handler(线程饱和策略)不能为空,默认策略为ThreadPoolExecutor.AbortPolicy。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
-
corePoolSize(线程池基本大小):当向线程池提交一个任务时,若线程池已创建的线程数小于corePoolSize,即便此时存在空闲线程,也会通过创建一个新线程来执行该任务,直到已创建的线程数大于或等于corePoolSize时,才会根据是否存在空闲线程,来决定是否需要创建新的线程。除了利用提交新任务来创建和启动线程(按需构造),也可以通过 prestartCoreThread() 或 prestartAllCoreThreads() 方法来提前启动线程池中的基本线程。
-
maximumPoolSize(线程池最大大小):线程池所允许的最大线程个数。当队列满了,且已创建的线程数小于maximumPoolSize,则线程池会创建新的线程来执行任务。另外,对于无界队列,可忽略该参数。
-
keepAliveTime(线程存活保持时间):默认情况下,当线程池的线程个数多于corePoolSize时,线程的空闲时间超过keepAliveTime则会终止。但只要keepAliveTime大于0,allowCoreThreadTimeOut(boolean) 方法也可将此超时策略应用于核心线程。另外,也可以使用setKeepAliveTime()动态地更改参数。
-
unit(存活时间的单位):时间单位,分为7类,从细到粗顺序:NANOSECONDS(纳秒),MICROSECONDS(微妙),MILLISECONDS(毫秒),SECONDS(秒),MINUTES(分),HOURS(小时),DAYS(天);
-
workQueue(任务队列):用于传输和保存等待执行任务的阻塞队列。可以使用此队列与线程池进行交互:
如果运行的线程数少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队。 如果运行的线程数等于或多于 corePoolSize,则 Executor 始终首选将请求加入队列,而不添加新的线程。 如果无法将请求加入队列,则创建新的线程,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。
-
threadFactory(线程工厂):用于创建新线程。由同一个threadFactory创建的线程,属于同一个ThreadGroup,创建的线程优先级都为Thread.NORM_PRIORITY,以及是非守护进程状态。threadFactory创建的线程也是采用new Thread()方式,threadFactory创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池内的线程编号);
-
handler(线程饱和策略):当线程池和队列都满了,则表明该线程池已达饱和状态。
ThreadPoolExecutor.AbortPolicy:处理程序遭到拒绝,则直接抛出运行时异常 RejectedExecutionException。(默认策略) ThreadPoolExecutor.CallerRunsPolicy:调用者所在线程来运行该任务,此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。 ThreadPoolExecutor.DiscardPolicy:无法执行的任务将被删除。 ThreadPoolExecutor.DiscardOldestPolicy:如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重新尝试执行任务(如果再次失败,则重复此过程)。
队列排队详解
-
直接提交(SynchronousQueue):
-
使用
SynchronousQueue作为工作队列,任务会直接提交给线程而不会保持在队列中等待。如果没有可用线程来执行任务,将会创建新的线程。这种策略避免了任务在队列中等待时的锁竞争,但通常要求使用无界的maximumPoolSize以避免拒绝新任务。适用于处理具有瞬态突发请求的情况,例如 Web 服务器。
无界队列(LinkedBlockingQueue):
-
使用无界队列,如
LinkedBlockingQueue,允许任务在队列中等待,而不会立即创建新线程。这种方式下,线程池不会超过corePoolSize的数量,即使所有核心线程都在忙碌执行任务。适用于任务之间完全独立且不会相互影响的场景,例如在 Web 服务器中处理请求。
有界队列(ArrayBlockingQueue):
-
使用有界队列,如
ArrayBlockingQueue,可以防止资源耗尽,但也可能导致较难调整和控制。队列大小和最大池大小的选择需要进行权衡:使用大型队列和小型池可以降低 CPU 使用率和操作系统资源开销,但可能会降低系统的吞吐量。相反,使用小型队列可能会增加 CPU 使用率,但可能会遇到不可接受的调度开销,从而降低吞吐量。
-
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorExample {
public static void main(String[] args) {
// 核心线程数为 5,最大线程数为 10,空闲线程存活时间为 30 秒,使用有界队列作为任务队列
ThreadPoolExecutor executor = new ThreadPoolExecutor(
5, // 核心线程数
10, // 最大线程数
30, // 线程空闲时间
TimeUnit.SECONDS, // 时间单位
new ArrayBlockingQueue<>(100) // 任务队列,这里使用有界队列,可以根据需要调整队列大小
);
// 提交任务给线程池执行
for (int i = 1; i <= 10; i++) {
Runnable task = new TaskRunnable("Task " + i);
executor.execute(task);
}
// 关闭线程池
executor.shutdown();
}
// 示例任务,实现 Runnable 接口
static class TaskRunnable implements Runnable {
private String taskName;
public TaskRunnable(String taskName) {
this.taskName = taskName;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " executing " + taskName);
try {
Thread.sleep(2000); // 模拟任务执行时间
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " completed " + taskName);
}
}
}















 1765
1765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









