







第一步:替换文件如下图需替换4个文件:
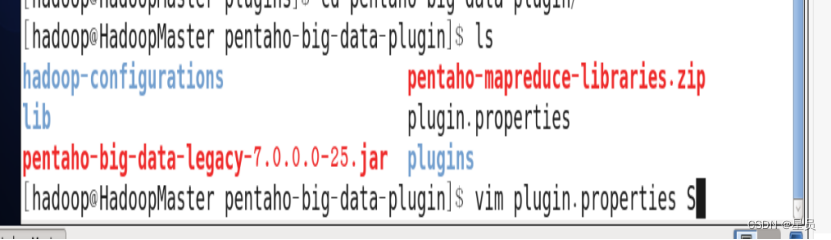
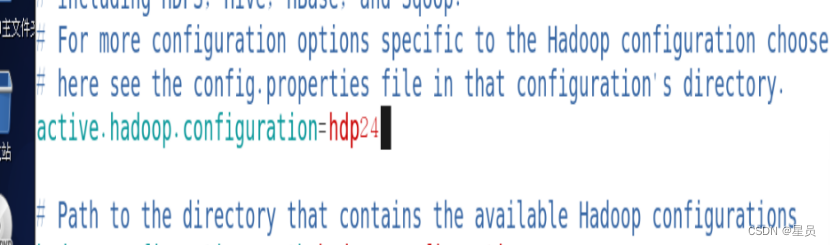
在替换之前先打开plugin.properties进行赋值如下图:
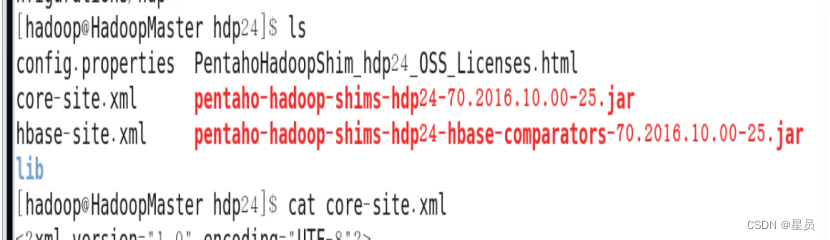
先把目录下需要替换的文件进行删除如下图:

第二步:把文件复制在目标目录下去第一个文件如下:

如下已经复制成功第一个:
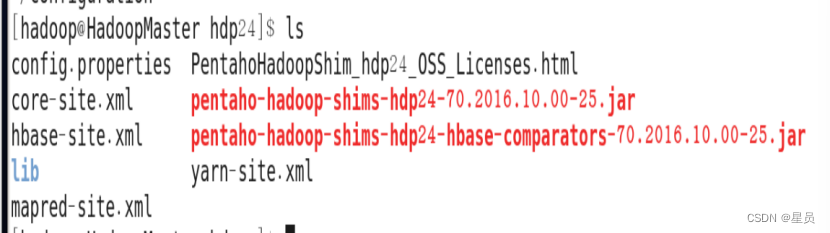
接下来复制mapred-site.xml文件和yarn-site.xml文件如下图:
如图三个文件替换完成:
第三步:启动Hadoop集群,再启动kettle:
输入./spoon.sh启动kettle:

找到BigData,把Hadoop File OutPut拖动出来:

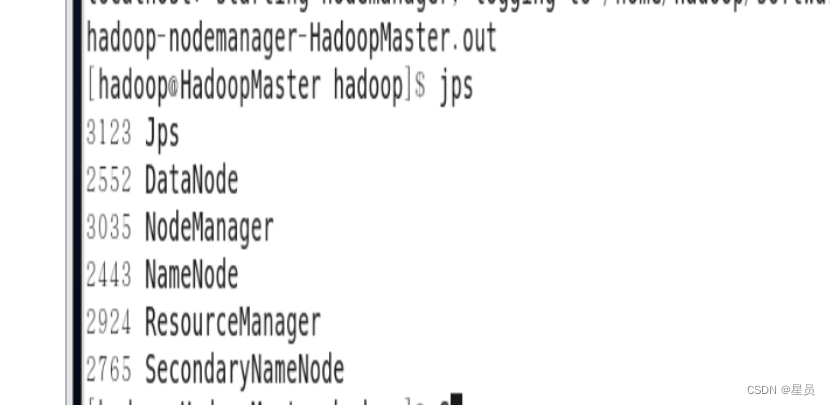
这里可以看出kettle启动成功
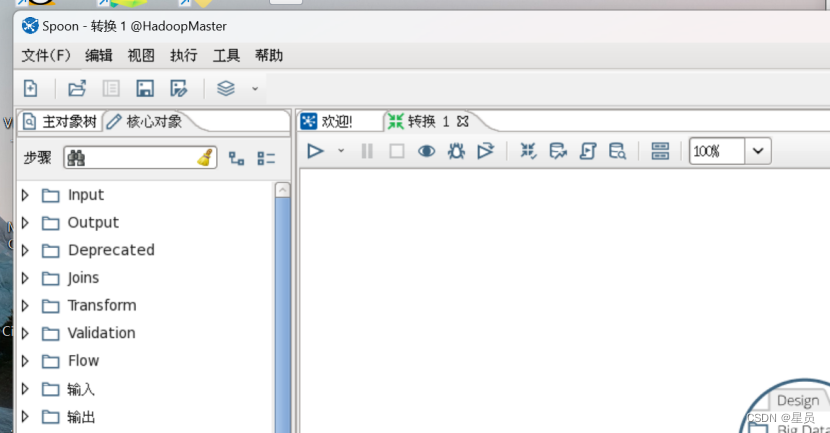
把Hadoop File OutPut拖动出来成功如下图:

第四步:配置Hadoop File OutPut,Hostname:HadoopMaster,Port:9000,配置如下图:
这里备注一点:在虚拟机中如果没有给虚拟机中的MySQL赋权,那么要在虚拟机中的MySQL中输入,MySQL的驱动安装在下面说明,如下指令:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'HadoopMaster' IDENTIFIED BY 'your_password' WITH GRANT OPTION;这里your_password改为自己的密码
FLUSH PRIVILEGES;
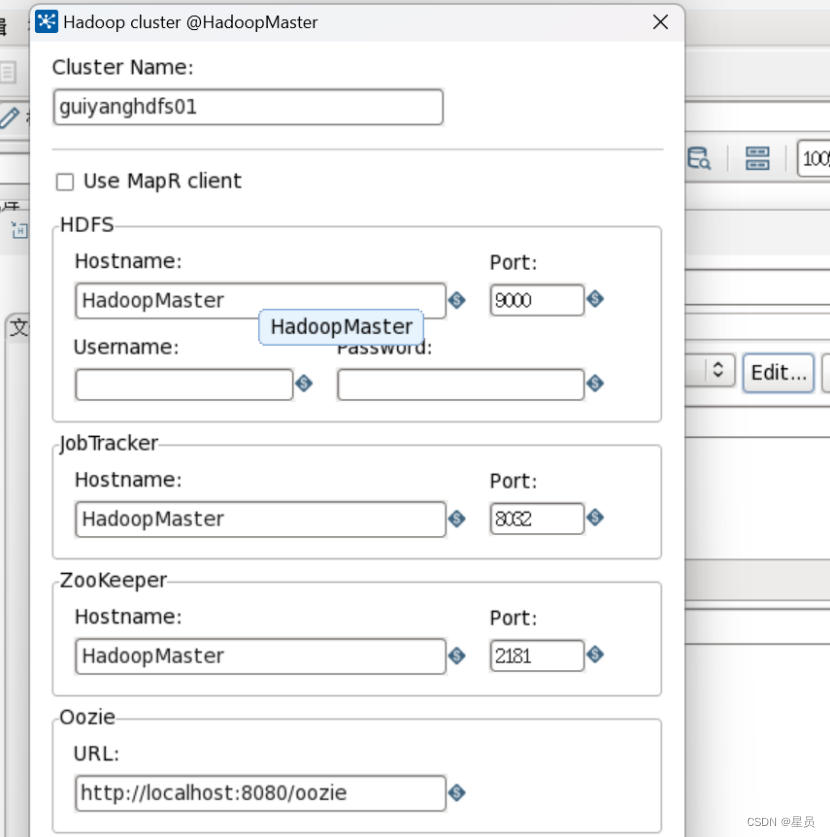
这里可以得出与Hadoop连接成功:
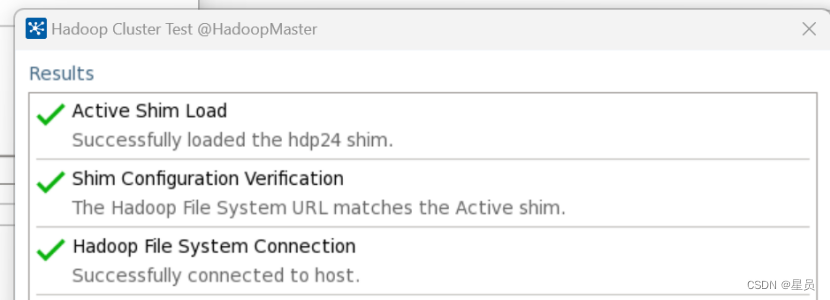
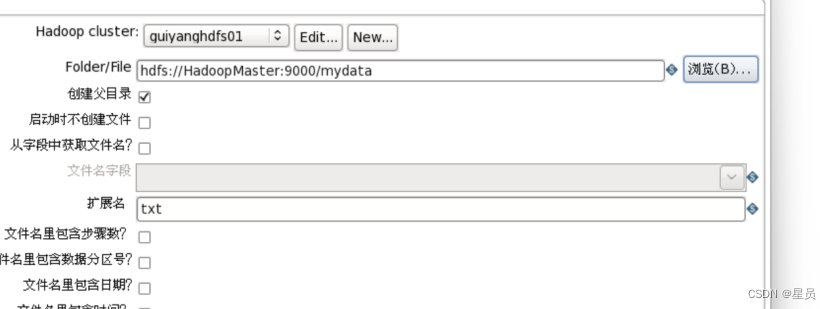
这里我选择的是hdfs下的mydata,当转换运行成功后会生成一个mydata.txt文件,如下图配置:
第五步:表输入,把表输入拖进去:

表输入拖入完成后,去Linux中的MySQL中查看数据库如下图:

接下来就要配置输入表,主机名是:HadoopMaster数据库:hive01,如下图:
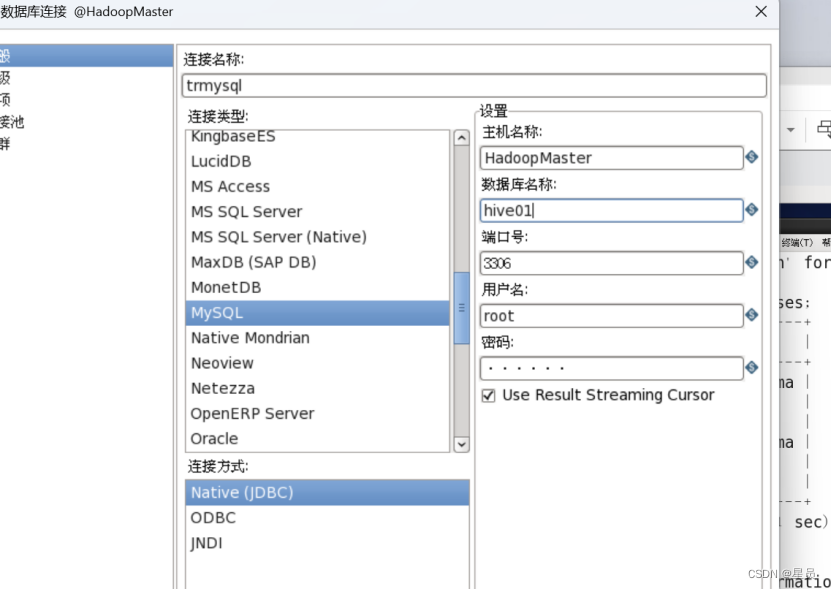
点击测试表示数据库连接正确,这里如果报错,问题可能是存在kettle中没有MySQL的驱动,需要把MySQL的驱动放入到data-integration目录下lib目录中,然后重新启动:
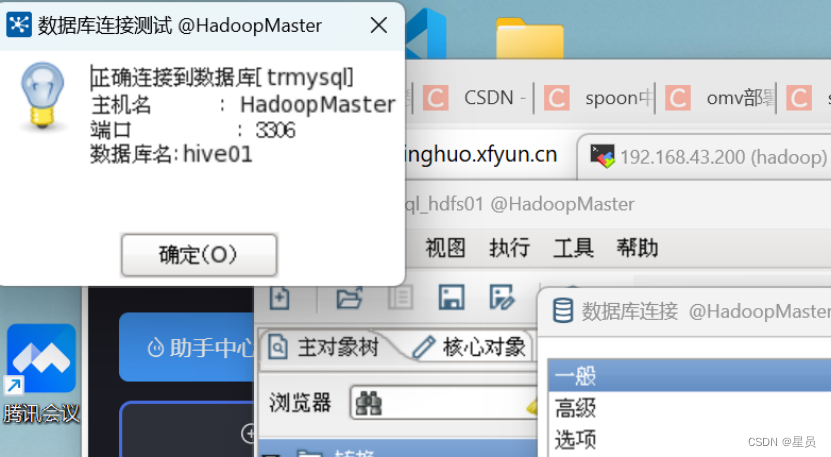
这里是验证表输入的连接,选择预览即可看见hive01数据库中table01表的数据:
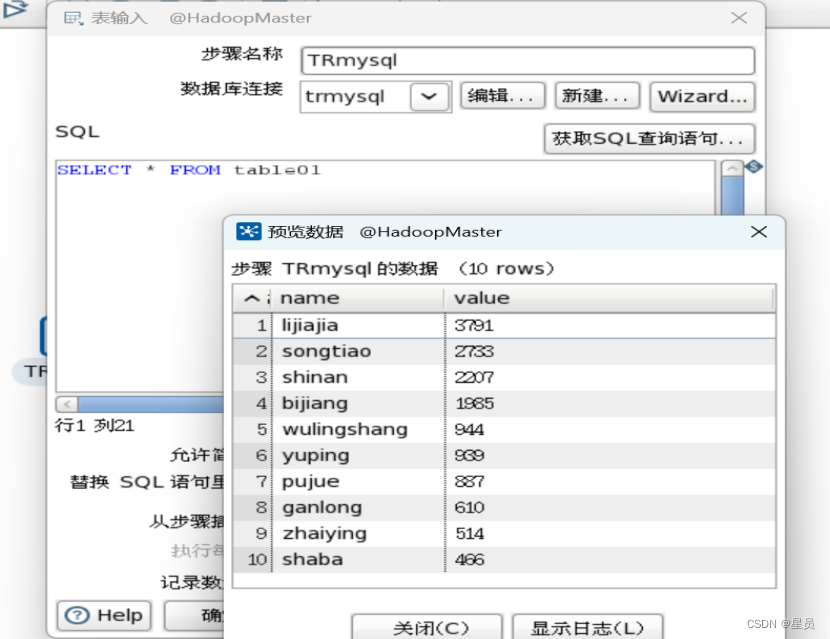
第六步:先保存转换,再启动转换,如下图可以看出启动成功,输入10,输出10,报错为0,说明转换成功:
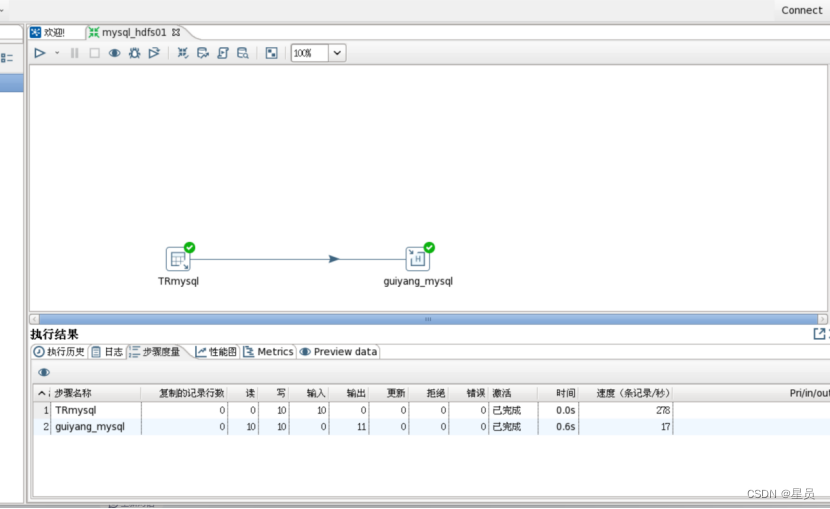
接下来去到hdfs下查看是否生成mydata.txt文件,如图可以看到已经生成这个文件:

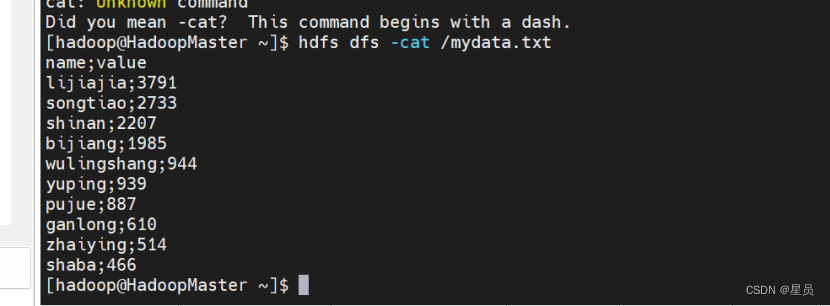
接下来打开mydata.txt文件,如图文件内容正确,说明实验成功,kettle连接HDFS成功,数据同步成功:















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









