






需求是基于redis的zset集合将其中的数据以分页的形式查询,要求是查询过的数据不能重复查询到
基于redis zset集合实现滚动分页功能
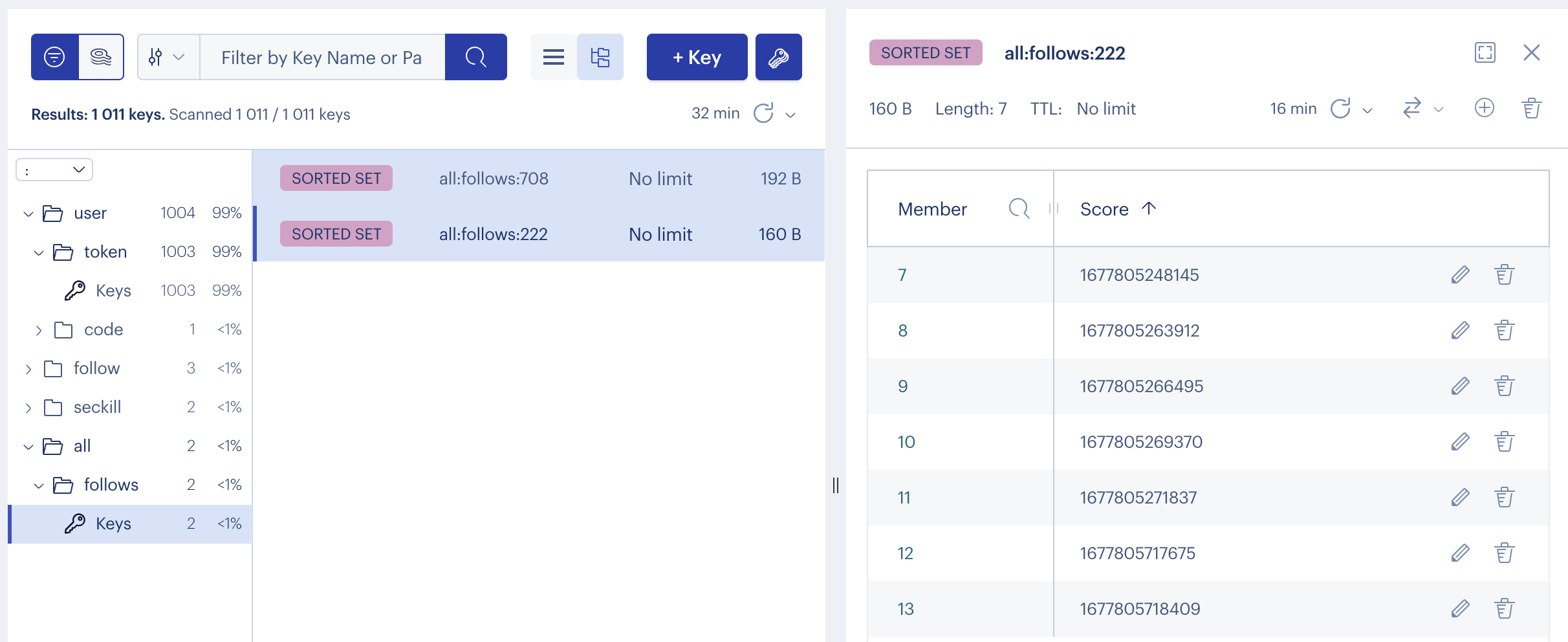
新建个zset集合向里面添加些测试数据
常规分页基于索引查询page:1,size:5,page:2,size:5......存在危害
此时集合中有7条数据执行分页查询第一次查询查询到的的是id为13,12,11,10,9这几条数据
第二次查询为8,7两条,这是正常情况下分页查询到的数据
另一种情况
执行分页查询第一次查询查询到的的是id为13,12,11,10,9这几条数据,如果当前时间其他用户向集合中添加数据那么新数据会在最顶部新增一条id为14score为当前时间戳的数据,那么这条数据会被放到最上方第二次查询到的数据则会变成9,8,7三条9这条数据则重复查询到,在一些特定场景下这种情况是不允许发生的,为此我们需要实现滚动分页这种动态查询
基于stringRedisTemplate.opsForZSet()提供的reverseRangeByScoreWithScores方法可以实现滚动分页查询
内部需要传递5个参数分别为
key:redis数据的key值
min:最小值,根据score打分查询到的最小的边界
max:最大值,根据score打分查询到的最大的边界
offset:如果score值相同需要跳过的个数(如果score值相同那么还是会被查询到的,因为查询到的数据是根据max传输的值来进行查询的:比如最大值我传入10此时集合内score为10打分的数据存在两条,那么这两条都会被查询到,需要跳过几条传入数值即可)
count:相当于传统分页中的分页条数下方代码写死为2条,正常由前端传入
public R queryBLongOfFollow(Long max, Integer offset) {
//获取当前用户id
String userId = threadLocal.get().getId();
//key
String key = "all:follows:" + userId;
//查询收件箱
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().
reverseRangeByScoreWithScores(key, 0, max, offset, 2);
if (typedTuples == null || typedTuples.isEmpty()) {
return R.ok();
}
//笔记id集合
ArrayList<String> listIds = new ArrayList<>();
//记录最小的时间戳
long minTime = 0;
//offset最小的时间戳出现的个数,用来跳过相同分数避免重复数据查询
int os = 1;
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {
//笔记id
String blogId = tuple.getValue();
listIds.add(blogId);
//时间戳
long time = tuple.getScore().longValue();
if (minTime == time) {
os++;
} else {
minTime = time;
os = 1;
}
}
//将笔记id集合以,拼接
String idsStr = StrUtil.join(",", listIds);
//按照顺序查询笔记集合
List<Blog> blogList = query().in("id", listIds)
.last("order by field(id," + idsStr + ")").list();
for (Blog b : blogList) {
isLikeBLong(b);
if (b == null) {
return R.error("查询失败");
}
User user = userService.query().eq("id", b.getUserId()).one();
b.setUser(user);
}
ScrollResult result = new ScrollResult();
result.setList(blogList);
result.setMinTime(minTime);
result.setOffset(os);
return R.ok().data("result",result);
}














 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









