






 本文详细介绍了如何在Linux系统上安装ifconfig、vim、设置静态IP、配置Hadoop环境,包括Java8、环境变量、伪分布式配置,以及解决常见问题如SSH配置和Hadoop环境变量设置。
本文详细介绍了如何在Linux系统上安装ifconfig、vim、设置静态IP、配置Hadoop环境,包括Java8、环境变量、伪分布式配置,以及解决常见问题如SSH配置和Hadoop环境变量设置。
安装ifconfig
sudo apt install net-tools -y
sudo apt install net-tools -y
安装vim:
sudo apt-get install vim-gtk
设置静态IP
查看ip地址,子网掩码,网关地址
ifconfig
route -n
设置root权限密码
sudo passwd root
新增用户
sudo useradd -m hadoop -s /bin/bash
设置密码:
sudo passwd hadoop
添加sudo权限
sudo adduser hadoop sudo
安装java8
更新apt
sudo apt-get update
sudo apt-get install openjdk-8-jdk
配置环境变量
Vim ~/.bashrc
让配置生效
source ~/.bashrc
下载hadoop,使用wget下载
Wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/hadoop-3.3.6.tar.gz
然后解压
Tar -zxvf hadoop-3.3.6.tar.gz -C /usr/local
修改文件操作权限
sudo chown -R hadoop ./hadoop
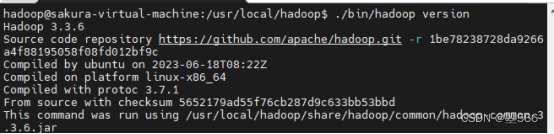
查看hadoop版本号
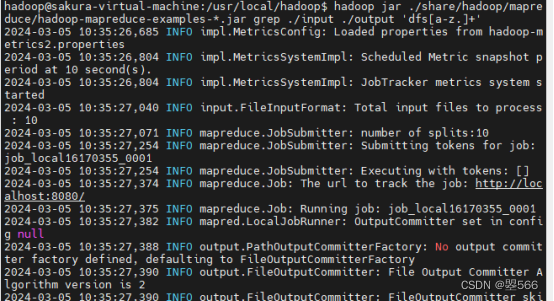
通过一个案例测试hadoop(查询符合条件的单词个数,结果保留到output文件夹)
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
创建一个input文件夹
Mkdir input
复制一些文件到input中,然后运行示例,结果保存在output文件夹当中
实现伪分布式需要修改的配置文件
sudo vim ./etc/hadoop/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other
temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
sudo vim ./etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
启动hdfs的namenode和守护进程
./bin/hdfs namenode -format
./sbin/start-dfs.sh
通过jps命令查看是否启动成功

Bug记录:有的时候会无法启动成功,比如jps命令只显示了jps进程
这里记录一下我的解决方案:
首先查看前面的配置文件是否配置成功
检查ssh是否配置成功
方式:ssh localhost
如果还需要输入密码才能登录就代表ssh没有配置成功
解决方案:我是因为密钥的问题而导致的,所以只需要重新生成密钥并保存到指定为止即可解决
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
还有可能会遇到localhost: Error: JAVA_HOME is not set and could not be found.这种报错
但是Java -version又是正常的情况
这个需要修改hadoop下的一个配置文件来解决
sudo vim/usr/local/hadoop/etc/hadoop/hadoop-env.sh
把自己的Java安装路径放进去
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
完成以后就可以在浏览器看到以下界面
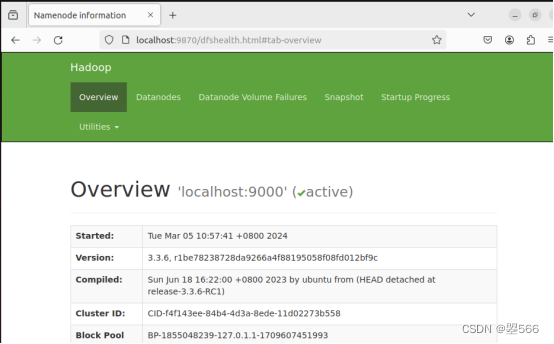
关闭就是运行sbin目录下的停止脚本
















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









