







1.划分训练集,验证集,测试集
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42) X :表示特征矩阵,通常是一个二维数组或 pandas 的 DataFrame ,包含了用于模型训练和预测的所有特征。
y :表示标签向量,通常是一个一维数组或 pandas 的 Series ,包含了与特征矩阵 X 中每个样本对应的目标值。
test_size=0.2 :指定测试集在原始数据集中所占的比例,这里设置为 0.2 ,意味着将原始数据集的 20% 划分为测试集,剩下的 80% 作为训练集。
变量赋值 : train_test_split 函数返回四个结果,分别赋值给 X_train (训练集的特征矩阵)、 X_temp (临时集的特征矩阵)、 y_train (训练集的标签向量)和 y_temp (临时集的标签向量)。
2.网格搜索优化KNN模型
print("\n--- 2. 网格搜索优化KNN (训练集 -> 测试集) ---")
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix
# 定义适用于 KNN 的参数网格
param_grid = {
'n_neighbors': [3, 5, 7, 9, 11],
'weights': ['uniform', 'distance'],
'p': [1, 2] # 1 表示曼哈顿距离,2 表示欧几里得距离
}
# 创建网格搜索对象,移除 random_state 参数
grid_search = GridSearchCV(
estimator=KNeighborsClassifier(),
param_grid=param_grid,
cv=5,
n_jobs=-1,
scoring='accuracy'
)
start_time = time.time()
# 在训练集上进行网格搜索
grid_search.fit(X_train, y_train)
end_time = time.time()
print(f"网格搜索耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", grid_search.best_params_)
# 使用最佳参数的模型进行预测
best_model = grid_search.best_estimator_
best_pred = best_model.predict(X_test)
print("\n网格搜索优化后的KNN 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("网格搜索优化后的KNN 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))
accuracy = accuracy_score(y_test, best_pred)
# 对于多分类问题,使用 'weighted' 平均来计算这些指标
precision = precision_score(y_test, best_pred, average='weighted')
recall = recall_score(y_test, best_pred, average='weighted')
f1 = f1_score(y_test, best_pred, average='weighted')
print("\n网格搜索优化后的 KNN 在测试集上的具体指标:")
print(f"准确率: {accuracy:.4f}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"F1 值: {f1:.4f}")输出结果:

3.贝叶斯优化KNN
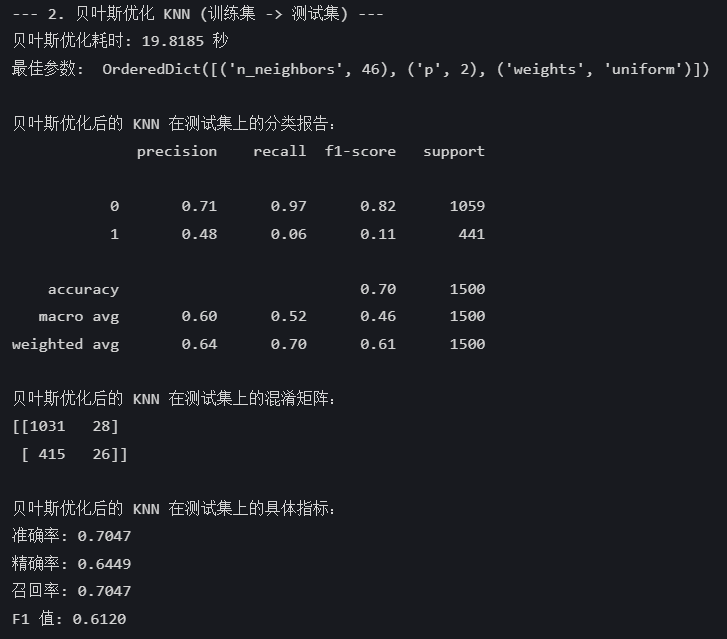
print("\n--- 2. 贝叶斯优化 KNN (训练集 -> 测试集) ---")
from skopt import BayesSearchCV
from skopt.space import Integer, Categorical
# 修改模型导入
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
# 定义 KNN 要搜索的参数空间
search_space = {
'n_neighbors': Integer(1, 50), # K 值范围
'weights': Categorical(['uniform', 'distance']), # 权重策略
'p': Categorical([1, 2]) # 距离度量,1 是曼哈顿距离,2 是欧几里得距离
}
# 创建贝叶斯优化搜索对象,修改为 KNN 模型
bayes_search = BayesSearchCV(
estimator=KNeighborsClassifier(),
search_spaces=search_space,
n_iter=32, # 迭代次数,可根据需要调整
cv=5, # 5折交叉验证,这个参数是必须的,不能设置为1,否则就是在训练集上做预测了
n_jobs=-1,
scoring='accuracy'
)
start_time = time.time()
# 在训练集上进行贝叶斯优化搜索
bayes_search.fit(X_train, y_train)
end_time = time.time()
print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", bayes_search.best_params_)
# 使用最佳参数的模型进行预测
best_model = bayes_search.best_estimator_
best_pred = best_model.predict(X_test)
print("\n贝叶斯优化后的 KNN 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的 KNN 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))
# 计算准确率、精确率、召回率和 F1 值
accuracy = accuracy_score(y_test, best_pred)
precision = precision_score(y_test, best_pred, average='weighted')
recall = recall_score(y_test, best_pred, average='weighted')
f1 = f1_score(y_test, best_pred, average='weighted')
print("\n贝叶斯优化后的 KNN 在测试集上的具体指标:")
print(f"准确率: {accuracy:.4f}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"F1 值: {f1:.4f}")输出结果:
4.网格搜索优化LightGBM
from lightgbm import LGBMClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report, confusion_matrix
import time
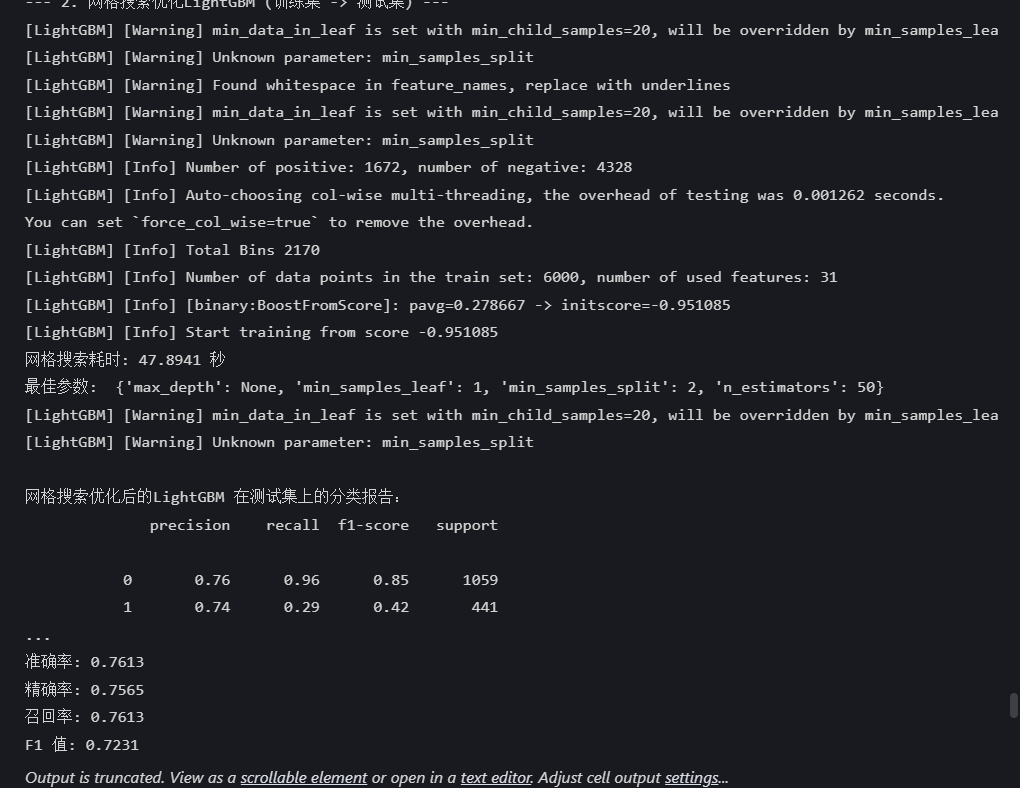
print("\n--- 2. 网格搜索优化LightGBM (训练集 -> 测试集) ---")
from sklearn.model_selection import GridSearchCV
# 定义要搜索的参数网格
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# 创建网格搜索对象
grid_search = GridSearchCV(estimator=LGBMClassifier(random_state=42),
param_grid=param_grid, # 参数网格
cv=5, # 5折交叉验证
n_jobs=-1, # 使用所有可用的CPU核心进行并行计算
scoring='accuracy') # 使用准确率作为评分标准
start_time = time.time()
# 在训练集上进行网格搜索
grid_search.fit(X_train, y_train) # 在训练集上训练,模型实例化和训练的方法都被封装在这个网格搜索对象里了
end_time = time.time()
print(f"网格搜索耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", grid_search.best_params_) #best_params_属性返回最佳参数组合
# 使用最佳参数的模型进行预测
best_model = grid_search.best_estimator_ # 获取最佳模型
best_pred = best_model.predict(X_test) # 在测试集上进行预测
print("\n网格搜索优化后的LightGBM 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("网格搜索优化后的LightGBM 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))输出结果:
5.贝叶斯优化KNN
print("\n--- 2. 贝叶斯优化LightGBM (训练集 -> 测试集) ---")
from skopt import BayesSearchCV
from skopt.space import Integer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
# 定义要搜索的参数空间
search_space = {
'n_estimators': Integer(50, 200),
'max_depth': Integer(10, 30),
'min_samples_split': Integer(2, 10),
'min_samples_leaf': Integer(1, 4)
}
# 创建贝叶斯优化搜索对象
bayes_search = BayesSearchCV(
estimator=LGBMClassifier(random_state=42),
search_spaces=search_space,
n_iter=32, # 迭代次数,可根据需要调整
cv=5, # 5折交叉验证,这个参数是必须的,不能设置为1,否则就是在训练集上做预测了
n_jobs=-1,
scoring='accuracy'
)
start_time = time.time()
# 在训练集上进行贝叶斯优化搜索
bayes_search.fit(X_train, y_train)
end_time = time.time()
print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", bayes_search.best_params_)
# 使用最佳参数的模型进行预测
best_model = bayes_search.best_estimator_
best_pred = best_model.predict(X_test)
print("\n贝叶斯优化后的LightGBM 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的LightGBM 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))
accuracy = accuracy_score(y_test, best_pred)
precision = precision_score(y_test, best_pred, average='weighted')
recall = recall_score(y_test, best_pred, average='weighted')
f1 = f1_score(y_test, best_pred, average='weighted')
print("\n贝叶斯优化后的 KNN 在测试集上的具体指标:")
print(f"准确率: {accuracy:.4f}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"F1 值: {f1:.4f}")输出结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









