







目录
问题描述(数据集、项目代码已资源绑定,见文章开头)

数据集
前瞻
随着工业化和城市化的迅速发展,全球多个城市都面临着空气污染问题,特别是细颗粒物(PM2.5)的增加。这些微小的颗粒物不仅对人体健康造成威胁,还对环境和生态产生长远的影响。因此,对这一问题进行深入研究,从而采取有效措施,对全球各地的居民和环境至关重要。
本报告旨在分析中国几个主要城市的PM2.5浓度,并对其与各城市的地理、气候和经济特点进行关联。通过比较不同数据来源的信息,报告将为读者呈现一个更全面、准确的空气质量概况,以及各大都市所面临的特定挑战。
为了确保数据的准确性和完整性,我们采集了近年的每日PM2.5观测值,并计算出日平均值。数据来自两个主要来源:各城市气象观测站发布的官方数据和美国大使馆发布的数据。这样的对比不仅提供了一个广泛的视角,还有助于对可能存在的偏差和差异进行校正。
在数据处理和分析过程中,我使用了多种先进的统计工具和技术,确保了数据的可靠性和有效性.
数据预处理
清洗数据,处理缺失值
![]()

计算所有PM列的平均值并创建新列'PM_avg'
![]()
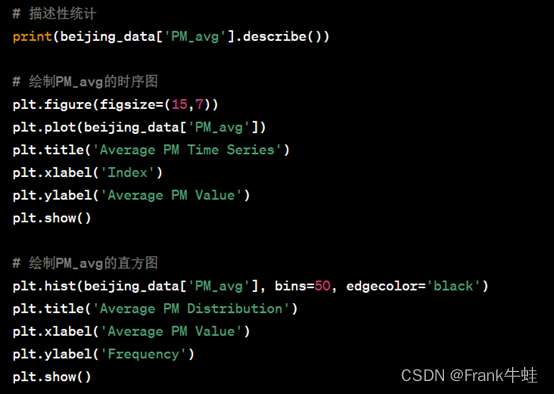
形成结果:
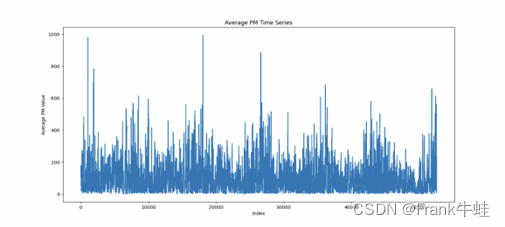
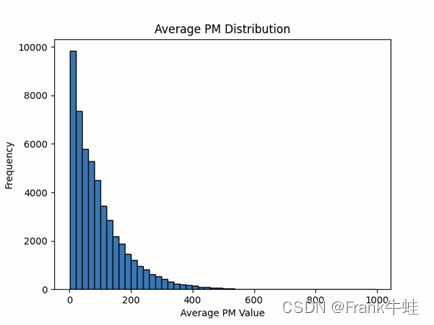
预处理报告
平均 PM 仿真图描述
从“平均下午时间序列”可以观察到以下特点:
1.波动性:平均PM值在整个气候中显示出明显的波动。这可能与一年中的不同季节、天气条件、工业活动和交通流量等因素有关。
2.尖峰:存在一些明显的尖峰,表明在某些时刻特定PM2.5的浓度迅速上升。这些尖峰可能与特定的事件或活动相关,例如燃烧、工业排放或不利的天气条件。
3.趋势:虽然说有很多短期的波动,但整体上没有明显的长期上升或下降趋势。然而,为了更准确地识别可能的趋势,可能需要进一步的时间序列分析。
平均 PM 分布图描述
从“平均PM分布”得出可以得出以下结论:
1.长尾:虽然大部分值都较低,但图形显示出明显的长尾。这意味着还有一些提高,PM2.5的浓度远低于平均水平。
2.高污染日:在600至1000的范围内,有部分数据点。这可能代表了特定的高污染日,当质量空气明显恶化时的数据点。
注意:预处理的作用是概览所有数据,因此并未对PM-US Post 做单列处理
其他四个城市的数据预处理同上
数据可视化
北京
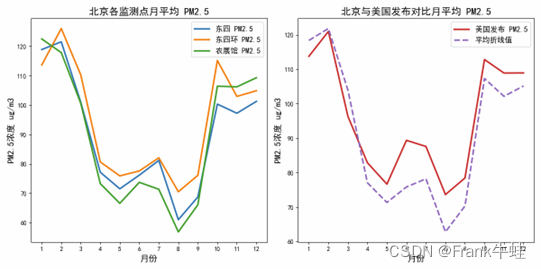
1. 季节性变化:
从图中可以明显看出,PM2.5 浓度在某些月份明显高于其他月份这可能与季节性活动(例如冬季取暖)或者气象条件有关。
2. 与美国发布数据的对比:
在第二个图中,我们可以看到美国发布的 PM2.5 数据与三个监测点的平均值的对比。虽然两者的走势大致相似,但在某些月份(例如1月)存在较大的差距。这可能是因为数据来源、测量方法或其他原因导致的
3. 数据的平滑度:
“平均折线值”作为三个监测点数据的平均,显示出了相对平滑的趋势,而“美国发布 PM2.5”数据则在某些月份有较大的跳动。这可能反映了美国发布的数据更具有局部性或受到某些特定因素的影响。
4. 三个监测点的差异:
在第一个图中,我们可以看到“东四 PM2.5”、“东四环 PM2.5”和“农展馆 PM2.5”三个监测点的数据波动模式大致相似,但数值有所差异。这表明北京市内不同地区的空气质量存在一定差异。
尤其在年初,这三个监测点的数据有明显的分离,其中“东四 PM2.5”浓度最高,而“农展馆 PM2.5”浓度相对较低。
上海
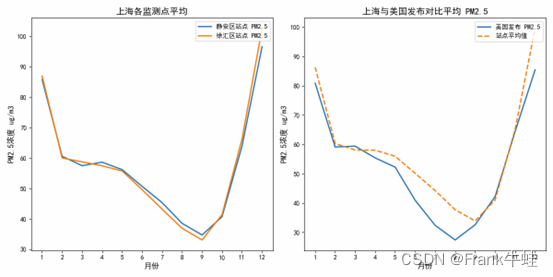
1. 对比“静安区”与“徐汇区”:
从左图中,我们可以看到“静安区”的PM2.5浓度在大部分月份都略高于“徐汇区”。这可能与静安区众多的商业区和旅游热点有关,这里的人流量、车流量较大,可能导致了更高的污染。
2. PM2.5浓度的季节性变化:
在左图和右图中,都可以观察到1月和12月的PM2.5浓度相对较高,而在中间月份逐渐下降。这可能与冬季供暖、燃煤、交通等因素有关,导致冬季的空气质量下降。
3. 数据的差异:
在某些月份,尤其是在5-9月期间,美国的观测值与上海的本地观测值存在较大的差异。这可能是由于两者使用的测量设备、技术或方法不同,或者是由于它们的观测站点位于上海的不同地方。
4. 数据的可信度:
由于两个不同的来源在大部分时间里给出了相似的趋势,这增强了数据的可信度。当两个独立的观测都显示相似的结果时,这通常意味着数据是可靠的。
广州
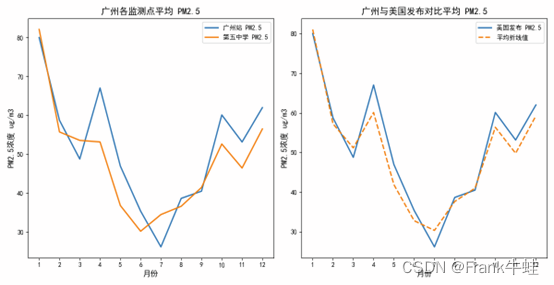
1. 观测与预测:
右图中,蓝色实线代表美国在广州的实际PM2.5观测值,而橙色虚线表示广州的本地预测值。显然,在大部分时期,实际的观测值与预测值都很接近,尤其是在夏季,说明广州的空气质量预测系统相对准确。
2. 季节性变化:
从两张图中都可以看出,广州的PM2.5浓度在冬季(尤其是年初和年末)相对较高,而在夏季(5-8月)较低。这可能与冬季的燃煤取暖、气象条件、大气稳定度等因素有关,而夏季的降雨和风速增加则有助于减少颗粒物。
3. 数据接近度:
在左图中,广州本地的观测值与美国的观测值非常接近,尤其是在6-12月期间,几乎重合。这说明两个数据来源在这段时间内给出了非常一致的结果
成都
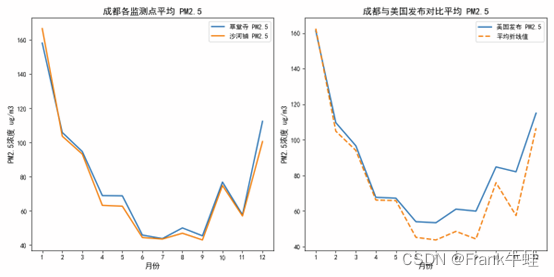
1. 对比其他城市:
如果我们与之前的上海和广州的数据进行比较,成都的PM2.5浓度整体上似乎更高。这可能是由于成都位于盆地中,导致污染物在空气中停留的时间更长。
2. 季节性影响:
如果考虑成都的气候,冬季由于供暖和不利于空气扩散的气候条件,可能会导致PM2.5浓度上升。
3. 观测值差异:
右图中显示了成都当地的PM2.5观测值(蓝线)与美国发布的关于成都的PM2.5观测值(橙线虚线)。总的来说,两者的趋势是相似的,但在某些点上存在一些差异。例如,在年初和年中,美国的观测值要稍微高于成都的当地观测值
沈阳
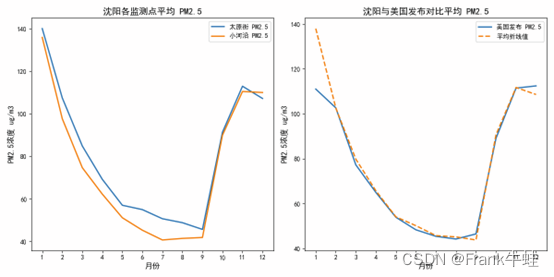
1. 对比其他城市:
与北京相比:北京同样处于北方,冬季也有燃煤取暖的现象。从图中可以看出,沈阳和北京的PM2.5趋势相似,冬季都有明显的高峰。但具体数值和波动可能会有所不同,这与两地的工业结构、交通状况和气候等因素有关。
与上海相比:上海位于东部沿海地区,冬季的取暖需求较小,因此其冬季的PM2.5浓度可能不如沈阳和北京显著。同时,上海作为国内的经济中心,可能由于更严格的环保措施和城市绿化,使得PM2.5浓度相对较低。
2. 冬季的高峰:
沈阳在年初和年末的PM2.5浓度较高,这与许多北方城市在冬季燃煤取暖导致的空气质量下降相吻合。冬季,尤其是在使用煤炭作为主要取暖来源的地区,容易出现雾霾天气,导致PM2.5浓度升高。
3. 不同的数据源:
在图中,我们可以看到两条线代表两种不同的数据源。尽管它们的趋势大致相同,但数值上有所不同。这提醒我们,在对空气质量进行分析时,使用不同的数据源可能会得到略有不同的结果。这也反映了环境监测的复杂性和多样性
总览对比图
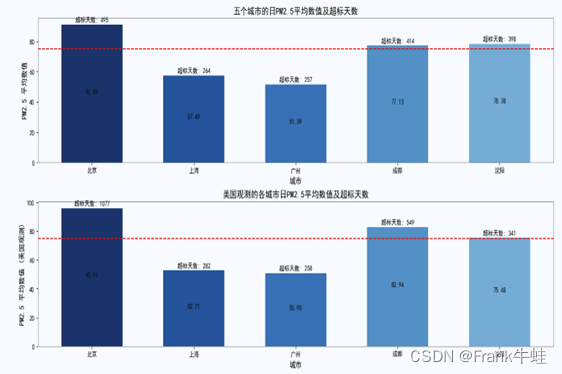
注意:日PM2.5含量超过75ug/m3即为超标
图一数据对比及简单分析:
北京:从图中可以看出,无论是哪个来源,北京的超标天数,平均PM2.5含量都是最多的。这可能是因为北京是国家的首都,人口密集,有大量的交通和工业活动。北京的地理位置使其容易受到周边工业区的污染迁移。
对比中美统计分析差异及原因:
总的来说,美国大使馆和中国官方发布的数据基本一致,符合实际预期。
其中数据存在一些差异的原因可能是:
观测方法和设备差异:不同国家和地方使用的观测设备和技术可能会有所不同。即使在相同的时间和地点,使用不同的设备和方法可能会得到稍微不同的数据。
观测点位置:观测点的地理位置对PM2.5的读数也会产生影响。例如,位于城市中心的观测点与位于城市边缘的观测点可能会得到不同的数据。美国的观测点可能主要位于对外交流较多、人流密集的地区,而中国的官方观测点可能分布得更为广泛。
数据处理和发布:有时,发布的数据可能会经过一些处理,比如平均值、最大值和最小值的计算。不同的处理方法可能会导致数据的差异。
政治和社会因素:空气质量数据的发布可能受到政治和社会因素的影响。某些时候,为了避免公众恐慌或其他考虑,可能会调整或选择不发布某些数据。
部分代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
beijing_data = pd.read_csv(r"D:\PM2.5data\BeijingPM20100101_20151231.csv")
chengdu_data = pd.read_csv(r"D:\PM2.5data\ChengduPM20100101_20151231.csv")
guangzhou_data = pd.read_csv(r"D:\PM2.5data\GuangzhouPM20100101_20151231.csv")
shanghai_data = pd.read_csv(r"D:\PM2.5data\ShanghaiPM20100101_20151231.csv")
shenyang_data = pd.read_csv(r"D:\PM2.5data\ShenyangPM20100101_20151231.csv")
# 设置Matplotlib的字体为"SimHei"以支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
city_data_list = [beijing_data, shanghai_data, guangzhou_data, chengdu_data, shenyang_data] # 假设您的五个城市数据集已经被加载
beijing_data['PM2.5'] =beijing_data[['PM_Dongsi', 'PM_Dongsihuan', 'PM_Nongzhanguan']].mean(axis=1)
shanghai_data['PM2.5'] =shanghai_data[['PM_Jingan', 'PM_Xuhui']].mean(axis=1)
guangzhou_data['PM2.5'] =guangzhou_data[['PM_City Station','PM_5th Middle School']].mean(axis=1)
chengdu_data['PM2.5'] =chengdu_data[['PM_Caotangsi','PM_Shahepu']].mean(axis=1)
shenyang_data['PM2.5'] =shenyang_data[['PM_Taiyuanjie','PM_Xiaoheyan']].mean(axis=1)
data_city1=beijing_data.groupby(['year', 'month', 'day'])['PM2.5'].mean().reset_index()
data_city2=shanghai_data.groupby(['year', 'month', 'day'])['PM2.5'].mean().reset_index()
data_city3=guangzhou_data.groupby(['year', 'month', 'day'])['PM2.5'].mean().reset_index()
data_city4=chengdu_data.groupby(['year', 'month', 'day'])['PM2.5'].mean().reset_index()
data_city5=shenyang_data.groupby(['year', 'month', 'day'])['PM2.5'].mean().reset_index()
data_city1_us=beijing_data.groupby(['year', 'month', 'day'])['PM_US Post'].mean().reset_index()
data_city2_us=shanghai_data.groupby(['year', 'month', 'day'])['PM_US Post'].mean().reset_index()
data_city3_us=guangzhou_data.groupby(['year', 'month', 'day'])['PM_US Post'].mean().reset_index()
data_city4_us=chengdu_data.groupby(['year', 'month', 'day'])['PM_US Post'].mean().reset_index()
data_city5_us=shenyang_data.groupby(['year', 'month', 'day'])['PM_US Post'].mean().reset_index()
data_cities_us=[data_city1_us,data_city2_us,data_city3_us,data_city4_us,data_city5_us]
avg_us = []
for data in city_data_list:
daily_avg = data.groupby(['year', 'month', 'day'])['PM_US Post'].mean()
overall_avg = daily_avg.mean()
avg_us.append(overall_avg)
cities_data =[data_city1, data_city2, data_city3, data_city4, data_city5]
city_names = ["北京","上海","广州","成都","沈阳"]
avg_pm25 = [data['PM2.5'].mean() for data in cities_data]
exceed_days = [data[data['PM2.5'] > 75].shape[0] for data in cities_data]
exceed_days_us = [data[data['PM_US Post'] > 75].shape[0] for data in data_cities_us]
# 设定颜色方案
bar_colors = ['#08306b', '#08519c', '#2171b5', '#4292c6', '#6baed6'] # 从深蓝到浅蓝的渐变色
background_color = '#f7fbff' # 轻柔的背景颜色
# 创建2x1的布局,调整figsize的参数
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(10, 8))
fig.patch.set_facecolor(background_color) # 设置背景颜色
for ax in axes:
ax.set_facecolor(background_color) # 设置子图的背景颜色
ax.spines['top'].set_color('gray')
ax.spines['right'].set_color('gray')
ax.spines['bottom'].set_color('gray')
ax.spines['left'].set_color('gray')
# 在第一个子图中绘制五个城市的PM2.5平均数值
bars1 = axes[0].bar(city_names, avg_pm25, color=bar_colors, width=0.6) # 使用渐变色
for bar, value in zip(bars1, avg_pm25):
height = bar.get_height()
axes[0].text(bar.get_x() + bar.get_width() / 2, height / 2, f'{value:.2f}', ha='center', color='black', fontsize=10) # 调整字体大小
for bar, days in zip(bars1, exceed_days):
height = bar.get_height()
axes[0].text(bar.get_x() + bar.get_width() / 2, height + 2, f'超标天数: {int(days)}', ha='center', fontsize=10) # 调整字体大小
axes[0].axhline(y=75, color='r', linestyle='--')
axes[0].set_xlabel('城市', fontsize=12)
axes[0].set_ylabel('PM2.5 平均数值', fontsize=12)
axes[0].set_title('五个城市的日PM2.5平均数值及超标天数', fontsize=14)
# 在第二个子图中绘制美国观测的各城市平均数值
bars2 = axes[1].bar(city_names, avg_us, color=bar_colors, width=0.6) # 使用渐变色
for bar, value in zip(bars2, avg_us):
height = bar.get_height()
axes[1].text(bar.get_x() + bar.get_width() / 2, height / 2, f'{value:.2f}', ha='center', color='black', fontsize=10) # 调整字体大小
for bar, days in zip(bars2, exceed_days_us):
height = bar.get_height()
axes[1].text(bar.get_x() + bar.get_width() / 2, height + 2, f'超标天数: {int(days)}', ha='center', fontsize=10) # 调整字体大小
axes[1].axhline(y=75, color='r', linestyle='--')
axes[1].set_xlabel('城市', fontsize=12)
axes[1].set_ylabel('PM2.5 平均数值 (美国观测)', fontsize=12)
axes[1].set_title('美国观测的各城市日PM2.5平均数值及超标天数', fontsize=14)
plt.tight_layout()
plt.show()到此结束!
点赞关注,分享更多干货~
由于目前不能上传压缩包资源,我只上传了报告的pdf版本,需要数据集、代码及实验报告的童鞋可以后台私信我~,过段时间再上传就设置成非免费资源啦



















 4057
4057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











