







数据科学入门必知:6种概率分布的原理、应用与可视化(附Python代码)
作为数据科学新手,理解概率分布就像学习「数据分析的字母表」。本文通过直观的图像展示、简单的代码示例和实际案例,帮助你快速掌握核心分布的原理与应用场景。
首先了解几个基本概念:
概率密度函数(Probability Density Function, PDF):概率密度函数描述了随机变量取某个值的可能性。对于连续型随机变量,概率密度函数 f ( x ) f(x) f(x) 的值并不是该点发生的概率,而是表示单位区间内取值的概率。
累积分布函数(Cumulative Distribution Function,简称CDF):是概率论和统计学中描述随机变量取值小于或等于某个特定值的概率的函数。它是概率分布的一个重要特征,可以提供关于随机变量的完整概率信息。定义:对于一个随机变量 X X X,其累积分布函数 F(x) 定义为: F(x)=P( X X X≤x) 这意味着 F(x) 给出了随机变量 X X X 取值小于或等于 x 的概率。
概率质量函数(Probability Mass Function, PMF)是用于描述离散随机变量在其所有可能取值上的概率分布的函数。具体来说,对于一个离散随机变量$ X$,其概率质量函数 P ( X = x ) P(X=x) P(X=x) 给出了随机变量 X 取特定值 x 的概率。
概率质量函数(PMF)用于描述离散随机变量在各可能取值上的概率,而概率密度函数(PDF)则用于描述连续随机变量在某一区间内取值的概率密度。
简而言之:
- PMF:离散随机变量取特定值的概率。
- PDF:连续随机变量在某区间内的概率密度,其下的面积表示该区间内的概率。
自由度:自由度(df)表示数据中可以自由变化的“数量”。它通常通过以下方式计算:如果你有一个分类数据表,自由度是(行数 - 1)乘以(列数 - 1)。自由度为什么重要呢?因为它决定了我们如何判断结果是否具有统计意义。自由度越高,我们对结果的“容忍度”也越高,也就是说,我们需要更强的证据来拒绝原假设。简单来说,自由度帮助我们理解数据中有多少信息是独立的,从而正确地进行统计检验。(卡方分布中常用)
先验分布:在统计学中,先验分布(Prior Distribution)是贝叶斯统计中的一个核心概念。它代表了在观测到任何数据之前,我们对某个未知参数的信念或知识。换句话说,它是基于以前的经验或主观判断对参数可能取值的概率分布进行描述的一种方式。Beta分布常被用作二项分布的共轭先验分布。
1. 正态分布(钟形曲线)
原理:数据围绕均值对称分布,越靠近均值频率越高,形状像钟。也被称为高斯分布。
公式:
f
(
x
)
=
1
σ
2
π
e
−
(
x
−
μ
)
2
2
σ
2
f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}
f(x)=σ2π1e−2σ2(x−μ)2
图像:
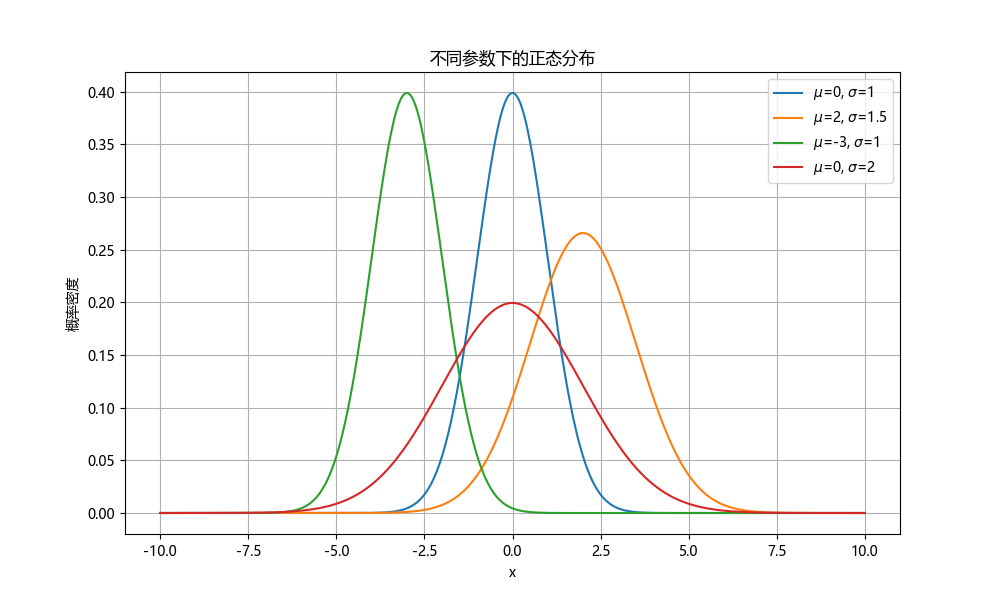
-
均值(μ):
- 正态分布的均值决定了分布的中心位置。图中有四条曲线,分别对应不同的均值:μ=0(蓝色)、μ=2(橙色)、μ=-3(绿色)和μ=0(红色)。
- 从图中可以看到,均值为0的曲线(蓝色和红色)是对称的,而均值为2(橙色)和-3(绿色)的曲线则分别向右和向左移动。
-
标准差(σ):
- 标准差决定了分布的宽度。标准差越大,分布越宽,曲线越平坦;标准差越小,分布越窄,曲线越陡峭。
- 图中,蓝色曲线的标准差为1,橙色曲线的标准差为1.5,红色曲线的标准差为2。可以看到,标准差越大,曲线越宽,峰值越低。
-
对称性:
- 正态分布是对称的,即曲线关于均值对称。图中所有曲线都展示了这种对称性。
-
概率密度:
- 概率密度函数的值表示在该点附近取值的概率密度。值越大,表示在该点附近取值的概率越高。
- 图中,蓝色曲线在x=0处达到最高点,表示在均值附近取值的概率最高。
-
曲线下的面积:
- 正态分布曲线下的总面积等于1,表示所有可能取值的概率之和。
- 由于正态分布是连续的,我们通常关注的是特定区间内的概率,而不是单个点的概率。
-
常用
P ( μ − σ ≤ x ≤ μ + σ ) = 0.6826 P(\mu - \sigma \leq x \leq \mu + \sigma) = 0.6826 P(μ−σ≤x≤μ+σ)=0.6826
P ( μ − 2 σ ≤ x ≤ μ + 2 σ ) = 0.9545 P(\mu - 2\sigma \leq x \leq \mu + 2\sigma) = 0.9545 P(μ−2σ≤x≤μ+2σ)=0.9545
P ( μ − 3 σ ≤ x ≤ μ + 3 σ ) = 0.9973 P(\mu - 3\sigma \leq x \leq \mu + 3\sigma) = 0.9973 P(μ−3σ≤x≤μ+3σ)=0.9973
通过这幅图,我们可以直观地理解正态分布的均值和标准差如何影响其形状和位置,以及正态分布的基本特性。
Python代码:
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体,这里以微软雅黑为例。请确保你的系统中安装了该字体。
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题
# 定义画布
plt.figure(figsize=(10, 6))
# 定义x轴范围
x = np.linspace(-10, 10, 500)
# 不同的μ和σ值
params = [(0, 1), (2, 1.5), (-3, 1), (0, 2)]
# 绘制不同参数下的正态分布曲线
for mu, sigma in params:
y = 1/(sigma * np.sqrt(2*np.pi)) * np.exp(-(x-mu)**2 / (2*sigma**2))
plt.plot(x, y, label=f'$\\mu$={mu}, $\\sigma$={sigma}') # 修改这里
# 设置图表标题和坐标轴标签
plt.title('不同参数下的正态分布')
plt.xlabel('x')
plt.ylabel('概率密度')
# 显示图例
plt.legend()
# 显示网格
plt.grid(True)
# 展示图像
plt.show()
数据科学应用:
- 异常检测:识别3σ外的数据点(如信用卡欺诈交易)
- 数据标准化:将特征转换为标准正态分布(Z-score标准化)
应用就不展开了,感兴趣的同学可以私下自己学习了解。
做个例题巩固一下吧~
题目
在一个正态分布的班级考试成绩中,假设均值 μ=80 分,标准差 σ=10 分。根据正态分布的性质,以下哪个选项描述的是不正确的?
A. 大约 68.26% 的学生得分在 70 分到 90 分之间。
B. 大约 95.45% 的学生得分在 60 分到 100 分之间。
C. 大约 99.73% 的学生得分在 50 分到 110 分之间。
D. 大约 68.26% 的学生得分在 50 分到 110 分之间。
解析:D
根据正态分布的“68-95-99.7”规则:
- 68.26%的数据在均值一个标准差内,即70到90分之间。选项A正确。
- 95.45%的数据在均值两个标准差内,即60到100分之间。选项B正确。
- 99.73%的数据在均值三个标准差内,即50到110分之间。选项C正确。
- 选项D错误,因为68.26%对应的是均值一个标准差的范围,而不是三个标准差。
2. 二项式分布(成功次数的计数器)
原理:二项分布描述的是在固定次数 n 的独立实验中,每次实验成功的概率为 p,失败的概率为 1−p,成功次数 k 的概率分布。
公式:
P
(
k
)
=
C
n
k
p
k
(
1
−
p
)
n
−
k
P(k) = C_n^k p^k (1 - p)^{n - k}
P(k)=Cnkpk(1−p)n−k
图像:
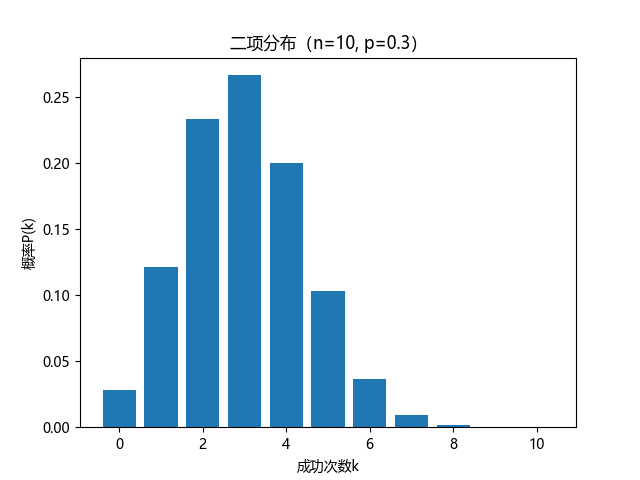
-
组合数如何求解:
C n k = n ! k ! ( n − k ) ! C_n^k = \frac{n!}{k!(n-k)!} Cnk=k!(n−k)!n! -
期望和方差:
- 期望(均值):E(X)=np
- 方差:Var(X)=np(1−p)
- 二项分布的图形通常是一个对称或偏斜的钟形曲线,具体形状取决于 n 和 p 的值。当 n 较大且 p 接近0.5时,二项分布接近正态分布。
代码:
from scipy.stats import binom
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体,这里以微软雅黑为例。请确保你的系统中安装了该字体。
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题
n, p = 10, 0.3 # 试验次数与成功概率
k_values = np.arange(0, n+1)
probabilities = binom.pmf(k_values, n, p)
plt.bar(k_values, probabilities)
plt.title(f"二项分布(n={n}, p={p})")
plt.xlabel("成功次数k")
plt.ylabel("概率P(k)")
plt.show()
数据科学应用:
- A/B测试:计算广告点击率的置信区间 ABtest是数据分析岗位需要掌握的必须知识,有该岗位求职意向的同学请着重学习
- 分类模型评估:预测正确次数服从二项分布
做个例题巩固一下吧~
假设你抛一枚公平的硬币10次,每次抛硬币正面朝上的概率是0.5。请问在这10次抛掷中,恰好出现3次正面朝上的概率是多少?
A. 0.0215
B. 0.0439
C. 0.0977
D. 0.2461
正确答案
C. 0.0977 代入公式即可
3. 泊松分布(低概率事件的记录仪)
原理:泊松分布是数据科学中用于建模稀有事件发生次数的核心工具。它特别适用于事件发生概率低、独立且单位时间/空间内平均发生率恒定的场景。
公式:
P
(
k
)
=
λ
k
e
−
λ
k
!
P(k) = \frac{\lambda^k e^{-\lambda}}{k!}
P(k)=k!λke−λ
λ(lambda):单位时间/空间内事件的平均发生次数(如图中λ=3)
k:实际观察到的事件发生次数(横轴值)
e:自然常数(约2.71828)
图像:
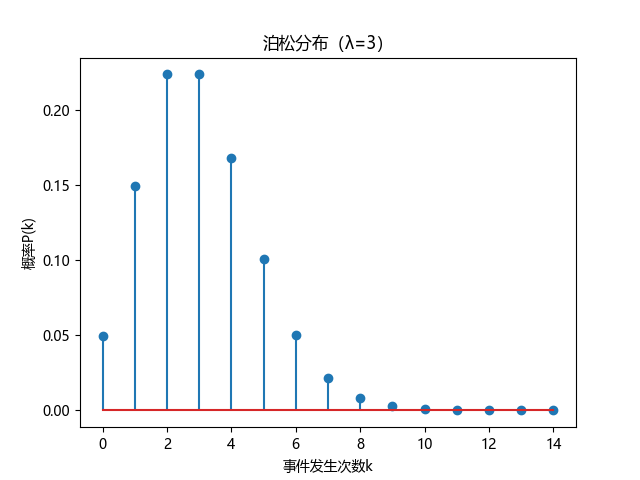
关键假设:
- 事件独立发生
- 单位时间内事件发生率恒定
- 事件不同时发生
数据科学应用:
- 用户行为分析:预测网站每分钟的访问量波动
- 文本分析:建模文档中罕见词的出现频率
做个例题巩固一下吧~
假设某医院平均每天有4个新生儿诞生,我们想要计算在一天内恰好有3个新生儿诞生的概率。
在这个问题中,λ=4(平均每天新生儿诞生次数),k=3(我们想要计算的新生儿诞生次数)。将这些值代入公式中,我们可以计算出概率。
P ( X = 3 ) = e − 4 4 3 3 ! P(X=3)=\frac{e^{−4}4^3}{3!} P(X=3)=3!e−443
计算这个表达式,我们可以得到在一天内恰好有3个新生儿诞生的概率。
4. 均匀分布(公平的骰子)
原理:均匀分布是数据科学中最基础且直观的概率分布之一,其核心特点是所有可能结果出现的概率密度完全相等。无论是随机抽样还是算法设计,均匀分布都扮演着重要角色。
连续型公式:
f
(
x
)
=
1
b
−
a
(
a
≤
x
≤
b
)
f(x) = \frac{1}{b - a} \quad (a \leq x \leq b)
f(x)=b−a1(a≤x≤b)
图像:
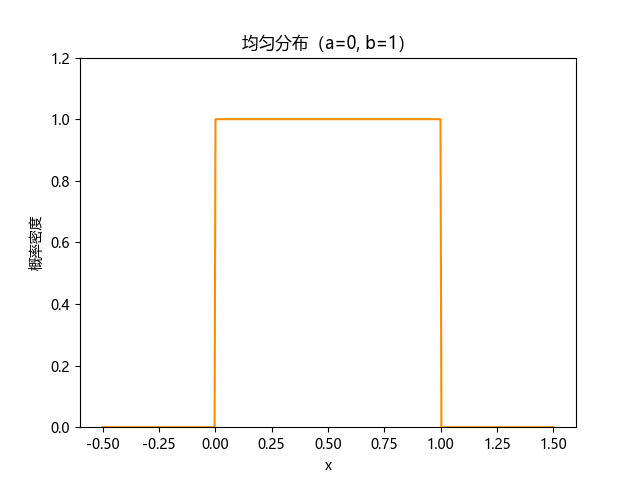
区间[a, b]内概率密度恒定
核心性质:
- 区间内概率密度恒定,形状为矩形
- 累积分布函数(CDF)呈线性增长
- 方差为 ( b − a ) 2 12 \frac{(b−a)^2}{12} 12(b−a)2,反映区间宽度的影响
数据科学应用:
- 随机森林:随机选择特征子集
- 数据增强:对图像添加随机旋转角度(0°~360°均匀分布)
做个例题巩固一下吧~
题目:
某在线课程的每周学习时长统计显示,学生的学习时间均匀分布在每周的2小时到6小时之间。请回答以下问题:
- 写出学习时间的概率密度函数(PDF)。
- 计算学生学习时间在3小时到5小时之间的概率。
- 求学生学习时间的期望值和方差。
解答:
概率密度函数(PDF)
连续型均匀分布在区间 [a,b][a,b] 上的概率密度函数为:
f ( x ) = { 1 b − a 当 a ≤ x ≤ b 0 其他情况 f(x) = \begin{cases} \frac{1}{b-a} & \text{当 } a \leq x \leq b \\ 0 & \text{其他情况} \end{cases} f(x)={b−a10当 a≤x≤b其他情况
代入 a=2小时,b=6 小时:
f ( x ) = { 1 4 当 2 ≤ x ≤ 6 0 其他情况 f(x) = \begin{cases} \frac{1}{4} & \text{当 } 2 \leq x \leq 6 \\ 0 & \text{其他情况} \end{cases} f(x)={410当 2≤x≤6其他情况区间概率计算
在区间 [c,d]内的概率为:
p ( c ≤ x ≤ d ) = d − c b − a p(c \leq x \leq d)=\frac{d-c}{b-a} p(c≤x≤d)=b−ad−c代入 c=3,d=5,a=2,b=6:
p ( 3 ≤ x ≤ 5 ) = 5 − 3 6 − 2 = 2 4 = 0.5 p(3 \leq x \leq 5 )=\frac{5-3}{6-2}=\frac{2}{4}=0.5 p(3≤x≤5)=6−25−3=42=0.5
答案: 概率为 50%。期望值与方差
期望值(均值):
E ( x ) = a + b 2 = 2 + 6 2 = 4 小时 E(x)=\frac{a+b}{2}=\frac{2+6}{2}=4 \text{小时} E(x)=2a+b=22+6=4小时
方差:
V a r ( X ) = ( b − a ) 2 12 = ( 6 − 2 ) 2 12 = 16 12 = 4 3 ≈ 1.333 小时 2 Var(X)=\frac{(b−a)^2}{12}=\frac{(6−2)^2}{12}=\frac{16}{12}=\frac{4}{3}≈1.333 \text{小时}^2 Var(X)=12(b−a)2=12(6−2)2=1216=34≈1.333小时2
5. 卡方分布(差异的裁判员)
原理:正态变量的平方和,用于衡量观察值与期望值的差异。
公式:
Q
=
∑
(
观测值
−
期望值
)
2
期望值
∼
χ
2
(
d
f
)
Q = \sum \frac{(\text{观测值} - \text{期望值})^2}{\text{期望值}} \sim \chi^2(df)
Q=∑期望值(观测值−期望值)2∼χ2(df)
图像:
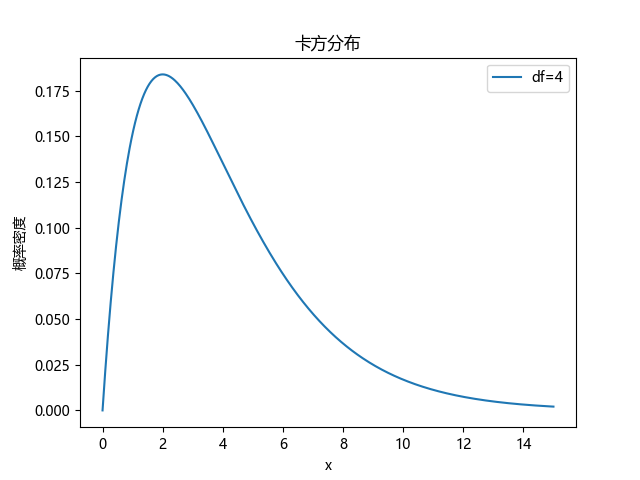
- 卡方分布是由 k 个独立的标准正态分布随机变量的平方和得到的。如果 Z1,Z2,…,Zk 是 k 个独立的标准正态分布随机变量,那么随机变量 X = Z 1 2 + Z 2 2 + . . . + Z k 2 X=Z_1^2+Z_2^2+...+Z_k^2 X=Z12+Z22+...+Zk2服从自由度为 k 的卡方分布。
- 卡方分布由一个参数确定,即自由度 k,它是一个正整数,表示独立标准正态分布随机变量的个数。
- 期望(均值): E ( X ) = k E(X)=k E(X)=k 方差: V a r ( X ) = 2 k Var(X)=2k Var(X)=2k
- 卡方分布的图形通常是一个单峰的钟形曲线,随着自由度 k 的增加,分布的形状会变得更加平坦,接近正态分布。
代码:
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体,这里以微软雅黑为例。请确保你的系统中安装了该字体。
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题
from scipy.stats import chi2
df = 4 # 自由度
x = np.linspace(0, 15, 500)
y = chi2.pdf(x, df)
plt.plot(x, y, label=f"df={df}")
plt.title("卡方分布")
plt.xlabel("x")
plt.ylabel("概率密度")
plt.legend()
plt.show()
数据科学应用:
- 特征选择:检验类别特征与目标变量的独立性
- 模型评估:比较预测分布与实际分布的拟合优度
做个例题巩固一下吧~
题目
假设你正在分析一组数据,这些数据来源于一个标准正态分布(均值为0,方差为1)。你从这个分布中随机抽取了25个样本,并计算了这些样本的平方和。根据你的统计知识,你知道这个平方和服从自由度为n的卡方分布。
问题:
- 如果你抽取的样本量是25,那么这个平方和服从自由度为多少的卡方分布?
- 给定自由度的情况下,求该卡方分布的期望值和方差。
解答提示
- 自由度:当从一个正态分布中抽取样本并计算它们的平方和时,若样本量为n,则此平方和服从自由度为n的卡方分布。因此,在本题中,自由度为25。
- 期望值和方差:
- 卡方分布的期望值等于其自由度,所以对于自由度为25的卡方分布,期望值为25。
- 卡方分布的方差等于其自由度的两倍,因此方差为2 * 25 = 50。
6.Beta分布(概率的概率)
原理:描述某个概率p的不确定性,范围[0,1]。
公式:
f
(
p
)
=
p
α
−
1
(
1
−
p
)
β
−
1
B
(
α
,
β
)
f(p) = \frac{p^{\alpha-1}(1-p)^{\beta-1}}{B(\alpha,\beta)}
f(p)=B(α,β)pα−1(1−p)β−1
图像:
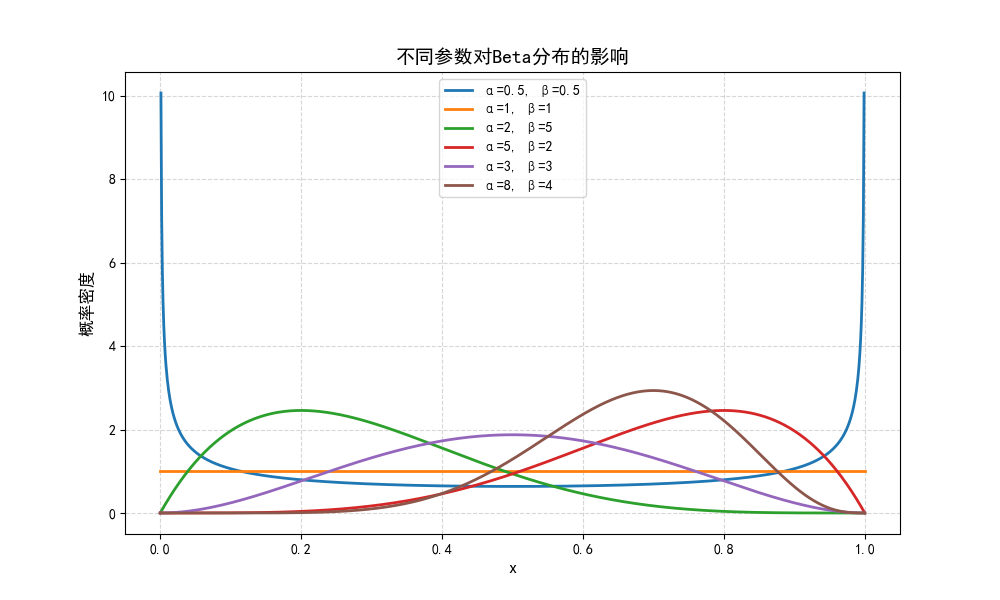
- α 和 β:这两个参数都是正实数,它们决定了分布的形状。当 α=β=1 时,Beta 分布退化为在 [0, 1] 上的均匀分布。
- Beta 分布的图形可以是对称的,也可以是偏斜的,具体取决于 α 和 β 的值。当 α=β 时,分布是对称的;当 α 和 β 不等时,分布是偏斜的。
- α=β=1
- 分布形态:均匀分布(所有值概率相等)。
- 现实意义:表示对事件结果无任何先验知识,适用于完全未知的场景。
- α=0.5, β=0.5
- 分布形态:U型分布(两端概率高,中间概率低)。
- 现实意义:表示极端事件更可能发生,例如用户要么完全喜欢要么完全讨厌新产品。
- α>β(如α=2, β=5)
- 分布形态:右偏(峰值靠近0)。
- 现实意义:预期事件发生的概率较低,例如广告点击率的悲观估计。
- α<β(如α=5, β=2)
- 分布形态:左偏(峰值靠近1)。
- 现实意义:预期事件发生的概率较高,例如高转化率版本的A/B测试。
- α=β>1(如α=3, β=3)
- 分布形态:对称钟型(中心在0.5)。
- 现实意义:表示对事件结果有中等信心,例如用户评分分布。
- α≫β(如α=8, β=4)
- 分布形态:高瘦右偏(置信度强)。
- 现实意义:经过大量数据更新后的贝叶斯后验分布,例如长期优化的推荐算法。
代码:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import beta
# 设置中文字体(可选)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
params = [
(0.5, 0.5), # U型分布
(1, 1), # 均匀分布
(2, 5), # 右偏分布
(5, 2), # 左偏分布
(3, 3), # 对称钟型分布
(8, 4) # 高置信度右偏
]
x = np.linspace(0, 1, 1000) # 生成0到1之间的数据点
plt.figure(figsize=(10, 6))
for a, b in params:
y = beta.pdf(x, a, b)
plt.plot(x, y, label=f"α={a}, β={b}", lw=2)
plt.title("不同参数对Beta分布的影响", fontsize=14)
plt.xlabel("x", fontsize=12)
plt.ylabel("概率密度", fontsize=12)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
数据科学应用:
- 贝叶斯A/B测试:根据先验分布更新转化率估计
- 推荐系统:建模用户点击概率的不确定性
做个例题巩固一下吧~
题目
假设某在线游戏的用户留存率(即在注册后至少登录一次的用户比例)可以用Beta分布来建模。为了简化问题,考虑两种情况:
- 情况A:公司初步估计新用户的留存率为50%,但是由于数据量较小,他们决定使用一个较为保守的先验分布,即Beta(2, 2)。
- 情况B:随着收集了更多数据,发现留存率为60%,并且基于更大的样本量,使用了更精确的先验分布Beta(12, 8)。
问题:
- 解释为什么Beta分布适合用来建模这种类型的概率问题?
- 对于情况A和情况B,分别计算其期望值,并解释这两个期望值的实际意义是什么。
- 比较情况A和情况B中Beta分布的概率密度函数图(你不需要实际画出图形,但请描述两个分布形状上的差异及其背后的原因)。
- 在哪种情况下,模型对留存率的估计更为确定?为什么?
解答
为什么选择Beta分布:
- Beta分布非常适合用于建模概率或比率的不确定性,因为它定义在区间[0, 1]上,正好对应了概率值的范围。此外,它具有灵活性,可以通过调整参数 α \alpha α和 β \beta β来反映不同水平的先验知识或信念。
计算期望值:
- 情况A中的期望值为 E [ X A ] = α α + β = 2 2 + 2 = 0.5 E[X_A] = \frac{\alpha}{\alpha + \beta} = \frac{2}{2+2} = 0.5 E[XA]=α+βα=2+22=0.5,意味着根据先验信息,预计的新用户留存率为50%。
- 情况B中的期望值为 E [ X B ] = 12 12 + 8 = 0.6 E[X_B] = \frac{12}{12+8} = 0.6 E[XB]=12+812=0.6,表明基于更多的数据,预计的新用户留存率提高到了60%。
比较两个分布的形状:
- 情况A中的Beta(2, 2)是一个对称且相对扁平的分布,表明我们对于留存率的具体数值不太确定,分布覆盖了从低到高的广泛可能性。
- 情况B中的Beta(12, 8)相比起来更加尖锐,并且偏向右侧(因为 α \alpha α> β \beta β),这反映了更高的置信度在留存率约为60%左右。较高的 α \alpha α和 β \beta β值使得分布更加集中,减少了不确定性。
确定性比较:
- 情况B中,由于较大的 α \alpha α和 β \beta β值导致的更窄、更集中的分布,说明相比于情况A,模型对留存率的估计更加确定。这是因为随着观测数据量的增加,我们对真实留存率有了更加准确的认识。在统计学中,这通常表现为方差减小,即预测的不确定性降低。
结束~
点赞关注收藏,获取更多专业知识~




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











