






HDFS常用命令操作实战
启动Hadoop集群

创建目录
执行命令:hdfs dfs -mkdir /ied

利用Hadoop WebUI查看创建的目录

创建多层目录
执行命令:hdfs dfs -mkdir /luzhou/lzy,会报错,因为/luzhou目录不存在
当然,可以先创建/luzhou目录,然后在里面再创建lzy子目录,但是也可以一步到位,需要一个-p参数
执行命令:hdfs dfs -mkdir -p /luzhou/lzy

查看目录
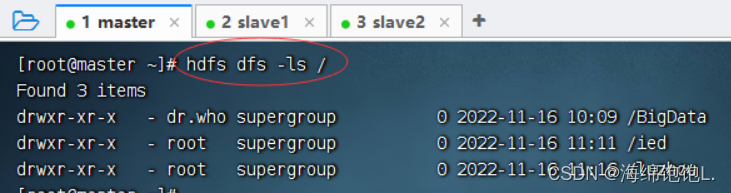
执行命令:hdfs dfs -ls /,查看根目录(可以在任何节点上查看,结果都是一样的)

执行命令:hdfs dfs -ls /luzhou

如果我们要查看根目录里全部的资源,那么要用到地柜参数-R(必须大写)
执行命令:hdfs dfs -ls -R /,递归查看/目录(采用递归算法遍历树结构)

上传本地文件到HDFS
创建test.txt文件,执行命令:echo "hello hadoop world" > test.txt (>:重定向命令)

上传test.txt文件到HDFS的/ied目录,执行命令:hdfs dfs -put test.txt /ied

查看是否上传成功
 利用Hadoop WebUI界面查看
利用Hadoop WebUI界面查看
查看文件内容
执行命令:hdfs dfs -cat /ied/test.txt

下载HDFS文件到本地
先删除本地的test.txt文件

下载HDFS文件系统的/ied/test.txt到本地当前目录不改名,执行命令:hdfs dfs -get /ied/test.txt

可以将HDFS上的文件下载到本地指定位置,并且可以更改文件名
执行命令:hdfs dfs -get /ied/test.txt /home/exam.txt

检查是否下载成功

删除HDFS文件
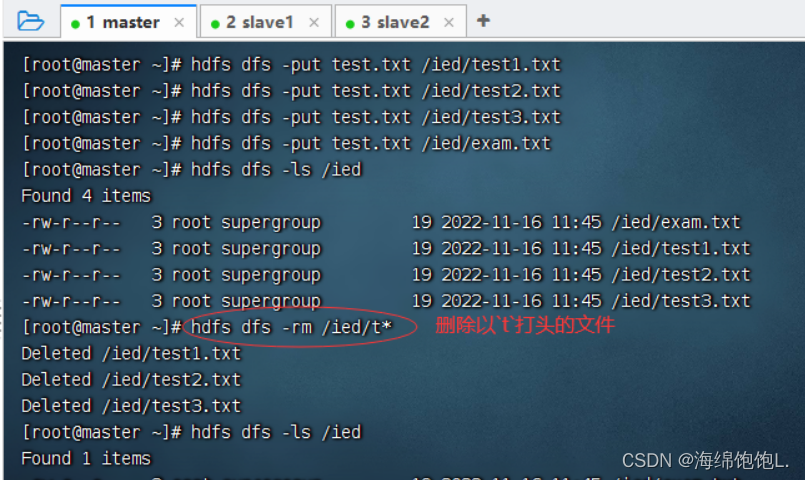
执行命令:hdfs dfs -rm /ied/test.txt
检查是否删除成功

使用通配符,可以删除满足一定特征的文件
删除HDFS目录
执行命令:hdfs dfs -rmdir /luzhou

提示-rmdir命令删除不了非空目录。
要递归删除才能删除非空目录:hdfs dfs -rm -r /luzhou(-r:recursive)

删除空目录/BigData,执行命令:hdfs dfs -rmdir /BigData

移动目录或文件
-mv命令兼有移动与改名的双重功能
将/ied目录更名为/ied01,执行命令:hdfs dfs -mv /ied /ied01


将/ied01/exam.txt更名为/ied/test.txt,执行命令:hdfs dfs -mv /ied01/exam.txt /ied01/test.txt
查看改名后的test.txt文件内容
文件合并下载
现在/ied01里有一个test.txt,创建sport.txt和music.txt并上传
合并/ied01目录的文件下载到本地当前目录的merger.txt,执行命令:hdfs dfs -getmerge /ied01/* merger.txt

下面,查看本地的merger.txt,看是不是三个文件合并后的内容

检查文件信息
检查test.txt文件,执行命令:hdfs fsck /ied01/test.txt -files -blocks -locations -racks

我们知道HDFS里一个文件块是128MB,上传一个大于128MB的文件,hadoop-3.3.4.tar.gz大约663.24MB
128 M B × 5 = 640 M B < 663.24 M B < 768 M B = 128 M B × 6 128 MB\times 5 = 640MB \lt 663.24MB \lt 768MB = 128 MB\times 6128MB×5=640MB<663.24MB<768MB=128MB×6 ,HDFS会将hadoop-3.3.4.tar.gz分割成6块。

执行命令:hdfs dfs -put /opt/hadoop-3.3.4.tar.gz /ied01,将hadoop压缩包上传到HDFS的/ied01目录

查看HDFS上hadoop-3.3.4.tar.gz文件信息,执行命令:hdfs fsck /ied01/hadoop-3.3.4.tar.gz -files -locations -racks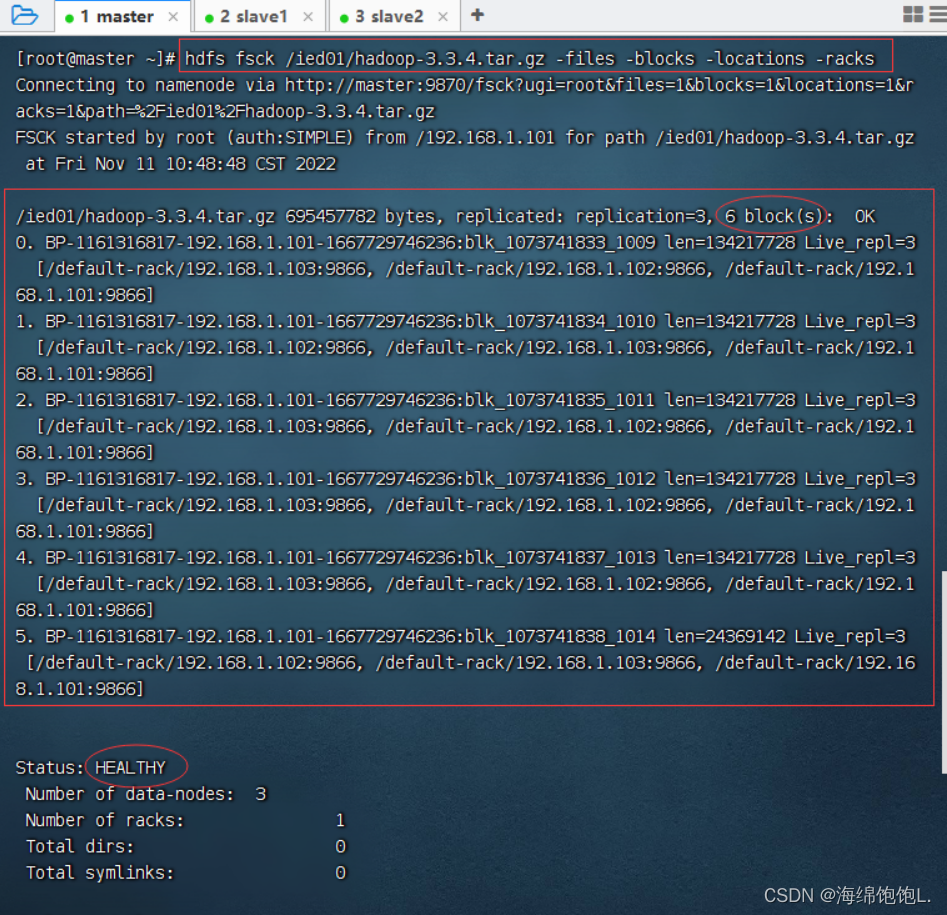
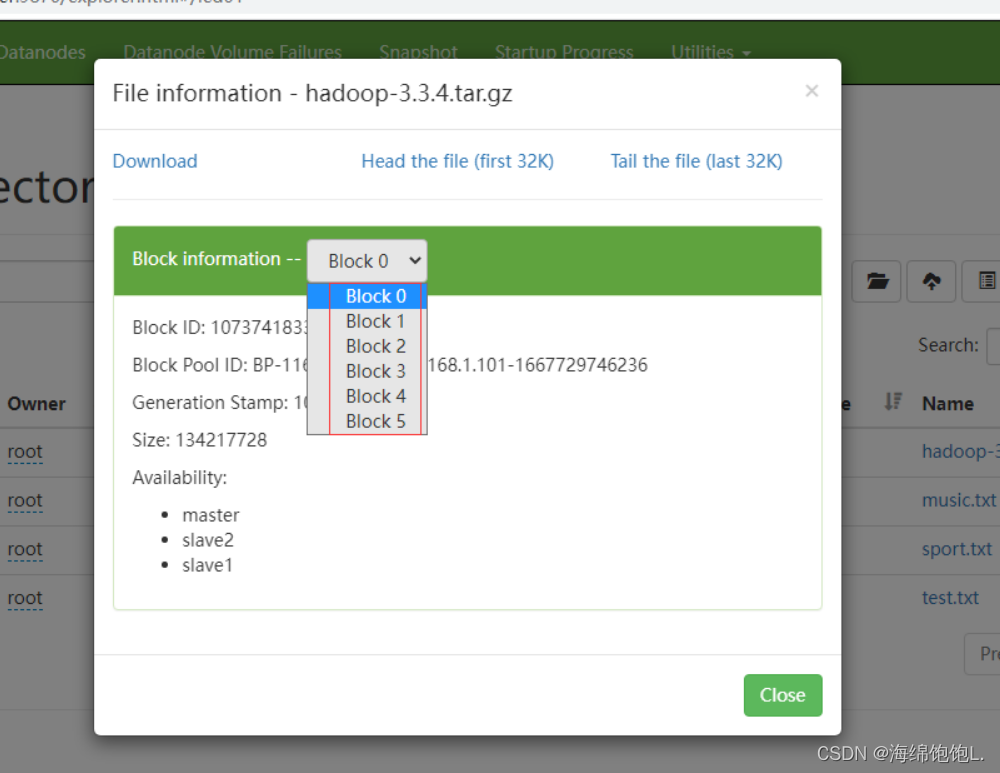
第1个文件块信息
第6个文件块信息 














 2071
2071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









