






一、机器训练学习方式条件
1、典型训练过程
(1)从一个随机初始化参数的模型开始,这个模型基本没有“智能”;
(2) 获取一些数据样本(例如,音频片段以及对应的是或否标签);
(3)调整参数,使模型在这些样本中表现得更好;
(4)重复第(2)步和第(3)步,直到模型在任务中的表现令⼈满意。
2、机器学习中的关键组件
无论什么类型的机器学习问题,都会遇到这些组件:
(1)可以用来学习的数据(data);
(2) 如何转换数据的模型(model);
(3)⼀个目标函数(objective function),用来量化模型的有效性;
(4)调整模型参数以优化目标函数的算法(algorithm)
数据(data)
每个数据集由一个个样本组成,大多时候,它们遵循独立同分布。样本有时也叫做数据点或者数据实例,通常每个样本由一组称为特征(features,或协变量(covariates))的属性组成。
当处理图像数据时,每一张单独的照片即为一个样本,它的特征由每个像素数值的有序列表示。

拥有越多数据的时候,工作就越容易。更多的数据可以被用来训练出更强大的模型,从而减少对预先设想假设的依赖。仅仅拥有海量的数据是不够的,还需要正确的数据。
模型(model)
任一调整参数后的程序被称为模型。 这些模型由神经⽹络错综复杂的交织在一起,包含层层数据转换,因此被称为深度学习。
目标函数(objective function)
“学习”,是指自主提高模型完成某些任务的效能。 在机器学习中,我们需要定义模型的优劣程度的度量,这个度量在大多数情况是“可优化”的,这被称之为目标函数。
- 定义一个目标函数,并优化它到最小值——损失函数。
- 预测数值任务——平方误差:预测值与实际值之差的平方。
- 预测分类任务——最⼩化错误率:预测与实际情况不符的样本⽐例。
- 损失函数是根据模型参数定义的,并取决于数据集。在一个数据集上,可以通过最⼩化总损失来学习模型参数的最佳值。
算法(algorithm)
当我们获得了一些数据源及其表示、一个模型和一个合适的损失函数,接下来就需要一种算法,它能够搜索出最佳参数,以最⼩化损失函数。深度学习中,大多流行的优化算法通常基于一种基本方法——梯度下降(gradient descent) 在每个步骤中,梯度下降法都会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。然后,它在可以减少损失的方向上优化参数。
二、机器学习
机器学习(machine learning,ML)是一类强大的可以从经验中学习的技术。通常采用观测数据或与环境交互的形式,机器学习算法会积累更多的经验,其性能也会逐步提高。
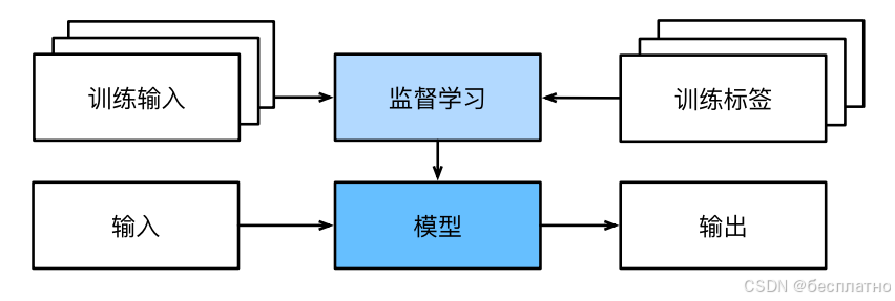
监督学习(supervised learning)
监督学习擅⻓在“给定输⼊特征”的情况下预测标签。每个“特征-标签”对都称为一个样本(example)。我们的目标是生成一个模型,能够将任何输⼊特征映射到标签(即预测)。
- 回归——平方误差损失函数(最简单的监督学习任务之一。例如:房价预测)
- 分类——交叉熵(样本属于“哪一类”的问题。分类问题希望模型能够预测样本属于哪个类别)回归是训练一个回归函数来输出一个数值;分类是训练一个分类器来输出预测的类别。
- 标注问题(学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)。例如:抖音、快手、多目标检测)
- 推荐系统(向特定用户进行“个性化”推荐。例如:电影推荐)
- 序列问题(输入和输出都是可变长度的序列。例如:自动语音识别、机器翻译)
无监督学习(unsupervised learning)
数据中不含有标签的机器学习问题。
- 聚类问题
- 主成分分析问题
- 因果关系和概率图模型
- 生成对抗网络
1、离线学习(offline learning)
不管是监督学习还是无监督学习,都会预先获取大量数据,然后启动模型,不再与环境交互。
- 优点:可以孤⽴地进行模式识别,而不必分心于其他问题。
- 缺点:解决的问题相当有限。
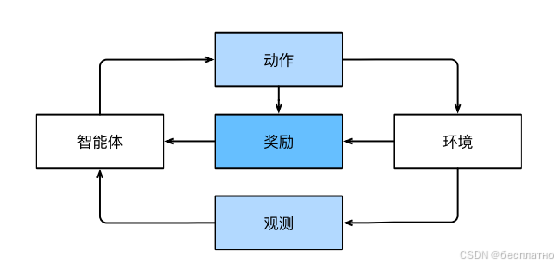
2、在线学习(Online learning)(或强化学习)
智能体在一系列的时间步骤上与环境交互。在每个特定时间点,智能体从环境接收一些观察,并且必须选择一个动作,然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励。此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。
三、机器学习成功案例
21世纪带来了高速互联网,智能手机摄像头、视频游戏等照片共享网站。数据池正在被填满。 廉价又高质量的传感器、廉价的数据存储以及廉价计算的普及,特别是GPU的普及,使大规模的算力唾手可得。
- 图像分类
- 图像目标检测和分割
- 人脸合成
- 机器翻译
- 图像描述
- 自然语言文本合成


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









