







本体下载
-
安装目录为 C:\Users\wyh\AppData\Local\NVIDIA\ChatRTX
-
conda环境目录:C:\Users\wyh\AppData\Local\NVIDIA\ChatRTX\env_nvd_rag
激活方式
conda activate C:\Users\wyh\AppData\Local\NVIDIA\ChatRTX\env_nvd_rag
安装额外模型
-
具体模型需要TensorRT支持
-
TensorRT-LLM/examples at main · NVIDIA/TensorRT-LLM (github.com)一些提供好的tensorRT可量化模型模板
-
以chatglm3-6b为例
下载模型
# 在C:\Users\wyh\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\model 下打开目录
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
# 漫长的等待,46.5G
-
下载完后建立三个文件夹engine,model_checkpoints,tokenizer
使用TensorRT转换模型
-
0.3版本不再自带TensorRT-LLM源文件,需要自己下载
-
打开conda命令行

conda activate C:\Users\wyh\AppData\Local\NVIDIA\ChatRTX\env_nvd_rag #具体路径自行修改
pip show tensort-llm #查看tensort版本-
在Releases · NVIDIA/TensorRT-LLM (github.com)里面下载对应版本源代码,直接下载在model文件夹下即可
-
# 将模型参数转化为TensorRT可用格式 python .\TensorRT-LLM-0.9.0\examples\chatglm\convert_checkpoint.py ` #对应模型的conver_checkpoint文件 --model_dir .\trt-llm-rag-windows-ChatRTX_0.3\model\chatglm3-6b ` # 模型本体路径 --output_dir .\trt-llm-rag-windows-ChatRTX_0.3\model\chatglm3-6b\model_checkpoints #输出路径,路径都需要修改 # 生成TensorRT引擎 trtllm-build --checkpoint_dir .\trt-llm-rag-windows-ChatRTX_0.3\model\chatglm3-6b\model_checkpoints ` --gemm_plugin float16 ` --output_dir .\trt-llm-rag-windows-ChatRTX_0.3\model\chatglm3-6b\engine --max_input_len=4096 --max_output_len=2048max_input_len和max_output_len需要根据模型修改,例如chatglm在tensorRT里面有说明,Using ChatGLM2-6B-32K / ChatGLM3-6B-32K models, we need to guarantee
max_batch_size * max_beam_width * (max_input_len + max_output_len) <= 78398 = 2^31 / (13696 * 2)due to constrain of TensorRT. For example, we will fail to build engine while using default max_batch_size (8) and adding arguments--max_beam_width=4 --max_input_len=20000 --max_output_len=100
编辑config
-
路径
C:\Users\wyh\AppData\Local\NVIDIA\ChatRTX\RAG\trt-llm-rag-windows-ChatRTX_0.3\config\config.json -
在model-support里面修改,下面是参考
{ "name": "ChatGLM 3 6B", "id": "chatglm3-6b", "ngc_model_name": "nvidia/chatglm3-6b-chat:1.0", "is_downloaded_required": false, "downloaded": true, "is_installation_required": false, "setup_finished": true, "min_gpu_memory": 8, "should_show_in_UI": true, "prerequisite": { "checkpoints_files": [ "config.json", "rank0.safetensors" ], "tokenizer_ngc_dir": "tokenizer", "tokenizer_files": { "config": "config.json", "model": "tokenizer.model", "tokenizer_config": "tokenizer_config.json" }, "checkpoints_local_dir": "model_checkpoints", "tokenizer_local_dir": "tokenizer", "engine_build_command": "trtllm-build --checkpoint_dir %checkpoints_local_dir% --output_dir %engine_dir% --gemm_plugin float16 --max_batch_size 1 --max_input_len 7168 --max_output_len 1024", "engine_dir": "engine" }, "metadata": { "engine": "rank0.engine", "max_new_tokens": 512, // 最大输入 "max_input_token": 7168, //最大输出 "temperature": 0.1 }, "model_info": "ChatGLM-6B is an open bilingual language model based on General Language Model framework, with 6.2 billion parameters | <a href= 'https://huggingface.co/THUDM/chatglm3-6b/blob/main/MODEL_LICENSE'> License </a>", "model_license": "<a href= 'https://huggingface.co/THUDM/chatglm3-6b/blob/main/MODEL_LICENSE'> License </a>", "model_size": "15.8GB" }
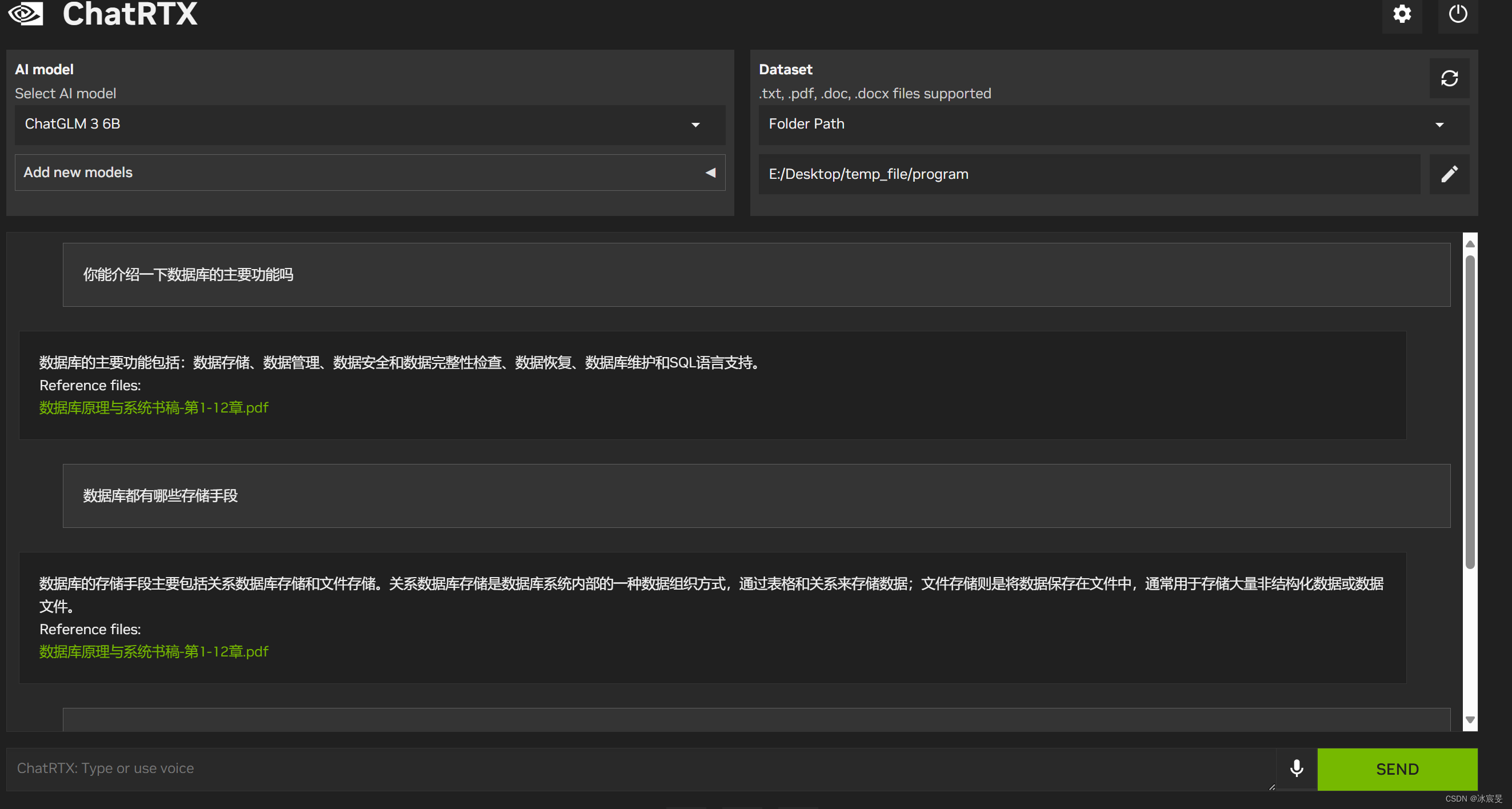
效果
















 1734
1734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











